Un guide d'introduction à MapReduce dans le Big Data
MapReduce représente une approche efficiente, rapide et économique pour la conception d'applications.
Ce modèle s'appuie sur des concepts avancés comme le traitement parallèle et la localité des données, offrant ainsi de multiples avantages aux développeurs et aux entreprises.
Cependant, la multitude de modèles et de cadres de programmation disponibles rend le choix difficile.
Lorsqu'il s'agit de Big Data, il est crucial de ne pas se tromper. Il faut opter pour des technologies capables de gérer de vastes volumes de données.
MapReduce se présente comme une solution idéale à cette problématique.
Cet article a pour objectif de décortiquer le concept de MapReduce et d'en explorer les avantages.
Entamons notre exploration!
Qu'est-ce que MapReduce ?
MapReduce est un paradigme de programmation, un cadre logiciel intégré à l'écosystème Apache Hadoop. Il est conçu pour le développement d'applications capables de traiter en parallèle d'importantes quantités de données sur des milliers de nœuds, formant des clusters ou des grilles, tout en assurant tolérance aux pannes et fiabilité.
Ce traitement de données s'effectue directement sur le système de fichiers ou la base de données où les données sont stockées. MapReduce est compatible avec le système de fichiers Hadoop (HDFS) pour l'accès et la manipulation de volumes de données massifs.
Introduit par Google en 2004 et popularisé par Apache Hadoop, ce cadre constitue une couche de traitement au sein d'Hadoop, exécutant des programmes MapReduce développés dans divers langages tels que Java, C++, Python et Ruby.
Les programmes MapReduce dans l'environnement cloud fonctionnent en parallèle, ce qui les rend particulièrement adaptés à l'analyse de données à grande échelle.
L'approche de MapReduce consiste à segmenter une tâche en sous-tâches plus petites à l'aide des fonctions "map" et "reduce". Chaque tâche est cartographiée, puis réduite en plusieurs tâches équivalentes, ce qui optimise la puissance de traitement et diminue la surcharge du réseau du cluster.
Imaginez que vous préparez un repas pour un grand nombre d'invités. Si vous deviez gérer toutes les préparations seul, le processus serait chaotique et chronophage.
En revanche, si vous sollicitez l'aide d'amis ou de collègues (et non des invités) pour répartir les tâches simultanément, la préparation sera plus rapide et plus simple, permettant d'accueillir les invités dans les meilleures conditions.
MapReduce fonctionne sur le même principe, en distribuant les tâches et en utilisant le traitement parallèle pour accélérer l'exécution de toute tâche donnée.
Apache Hadoop permet aux développeurs d'utiliser MapReduce pour appliquer des modèles à de grands ensembles de données distribués, en s'appuyant sur des techniques avancées d'apprentissage automatique et de statistiques pour identifier des tendances, anticiper des résultats, détecter des corrélations, etc.
Fonctionnalités de MapReduce
Voici quelques-unes des principales fonctionnalités de MapReduce :
- Interface utilisateur : Une interface utilisateur intuitive fournit des informations détaillées sur chaque aspect du cadre, facilitant la configuration, l'application et l'ajustement des tâches.
- Charge utile : Les applications utilisent les interfaces Mapper et Reducer pour exécuter les fonctions de mappage et de réduction. Le Mapper transforme les paires clé-valeur d'entrée en paires clé-valeur intermédiaires. Le Reducer combine les paires clé-valeur intermédiaires partageant une clé en des valeurs plus petites. Ce processus englobe le tri, le mélange et la réduction.
- Partitionneur : Il gère la répartition des clés intermédiaires de sortie de la carte.
- Rapports : Cette fonction permet de suivre la progression, de mettre à jour les compteurs et de définir des messages d'état.
- Compteurs : Ils représentent les compteurs globaux définis par une application MapReduce.
- OutputCollector : Cette fonction collecte les données de sortie du Mapper ou du Reducer au lieu des sorties intermédiaires.
- RecordWriter : Il enregistre la sortie de données ou les paires clé-valeur dans le fichier de sortie.
- DistributedCache : Il distribue efficacement des fichiers volumineux en lecture seule spécifiques à l'application.
- Compression des données : L'auteur de l'application peut compresser les sorties de tâches ainsi que les sorties de carte intermédiaires.
- Saut d'enregistrements incorrects : Vous avez la possibilité d'ignorer les enregistrements incorrects lors du traitement de vos entrées de carte. Cette fonctionnalité est gérée par la classe – SkipBadRecords.
- Débogage : La possibilité d'exécuter des scripts définis par l'utilisateur et d'activer le débogage est disponible. En cas d'échec d'une tâche dans MapReduce, un script de débogage peut être exécuté pour identifier les problèmes.
Architecture MapReduce
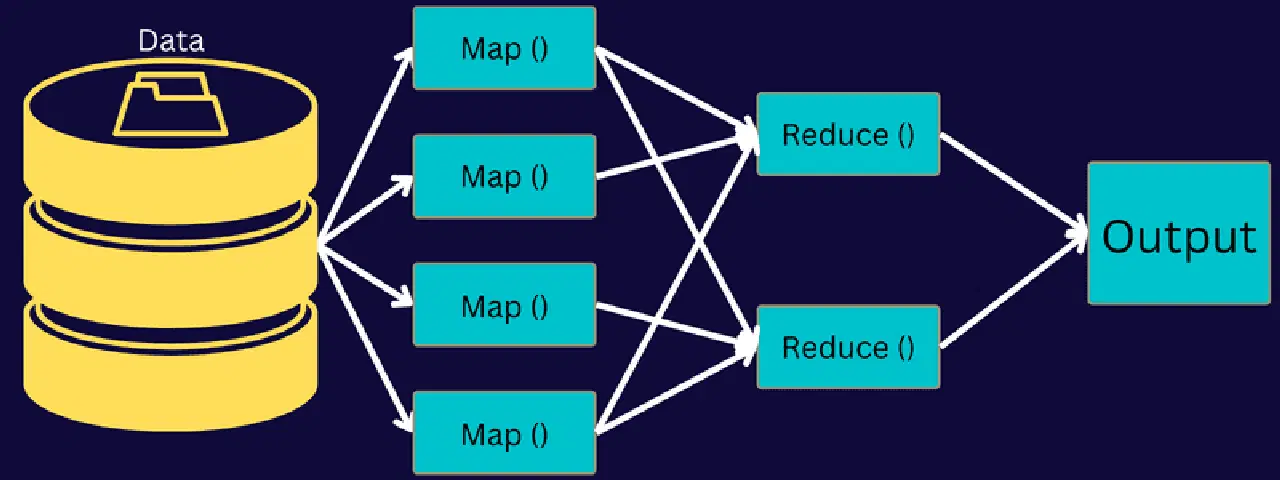
Explorons l'architecture de MapReduce en détail :
- Job : Un job, ou travail, dans MapReduce représente la tâche que le client MapReduce souhaite exécuter. Il se compose de plusieurs sous-tâches qui, ensemble, accomplissent la tâche globale.
- Serveur d'historique des tâches : Ce processus démon est responsable du stockage et de l'enregistrement de toutes les données historiques d'une application ou d'une tâche, telles que les journaux générés avant ou après l'exécution d'une tâche.
- Client : Un client, qu'il s'agisse d'un programme ou d'une API, soumet un job à MapReduce pour traitement. Plusieurs clients peuvent soumettre simultanément des jobs au MapReduce Manager.
- MapReduce Master : Le MapReduce Master divise un job en parties plus petites, s'assurant de l'exécution simultanée des tâches.
- Unités de tâche : Ces sous-tâches sont obtenues en divisant la tâche principale. Elles sont traitées individuellement puis combinées pour former la tâche finale.
- Données d'entrée : Il s'agit des données fournies à MapReduce pour le traitement des tâches.
- Données de sortie : C'est le résultat final obtenu après le traitement de la tâche.
Dans cette architecture, le client soumet un job au MapReduce Master, qui le divise en parties plus petites et égales. Le traitement des tâches est accéléré, car il est plus rapide de traiter des sous-tâches que des tâches massives.
Il est essentiel de ne pas diviser les tâches en trop petites unités, car cela pourrait entraîner une surcharge de gestion des fractionnements et une perte de temps conséquente.
Les composants du job sont mis à disposition pour les tâches Mapper et Reducer. Les tâches Map et Reduce sont adaptées au cas d'utilisation spécifique du projet. Les développeurs créent le code basé sur la logique pour répondre aux exigences.
Les données d'entrée sont transmises à la tâche de carte, où la sortie est générée sous forme de paire clé-valeur. Au lieu de stocker ces données sur HDFS, un disque local est utilisé pour éviter la réplication. Une fois la tâche terminée, la sortie peut être supprimée, car le stockage sur HDFS serait superflu.
La sortie de chaque tâche de mappage est ensuite transmise à la tâche de réduction. La sortie de la carte est envoyée à la machine exécutant la tâche de réduction. Cette sortie est ensuite fusionnée et traitée par la fonction de réduction définie par l'utilisateur. Enfin, la sortie réduite est stockée sur HDFS.
Plusieurs tâches Map et Reduce peuvent être utilisées pour le traitement des données en fonction de l'objectif final. Les algorithmes Map et Reduce sont optimisés pour minimiser la complexité temporelle ou spatiale.
Étant donné que MapReduce est principalement basé sur les tâches Map et Reduce, il est pertinent de les explorer davantage. Discutons des phases de MapReduce pour mieux comprendre ces concepts.
Phases de MapReduce
Carte
Dans cette phase, les données d'entrée sont transformées en paires clé-valeur. La clé peut représenter l'identifiant d'une adresse, tandis que la valeur peut être la valeur réelle de cette adresse.
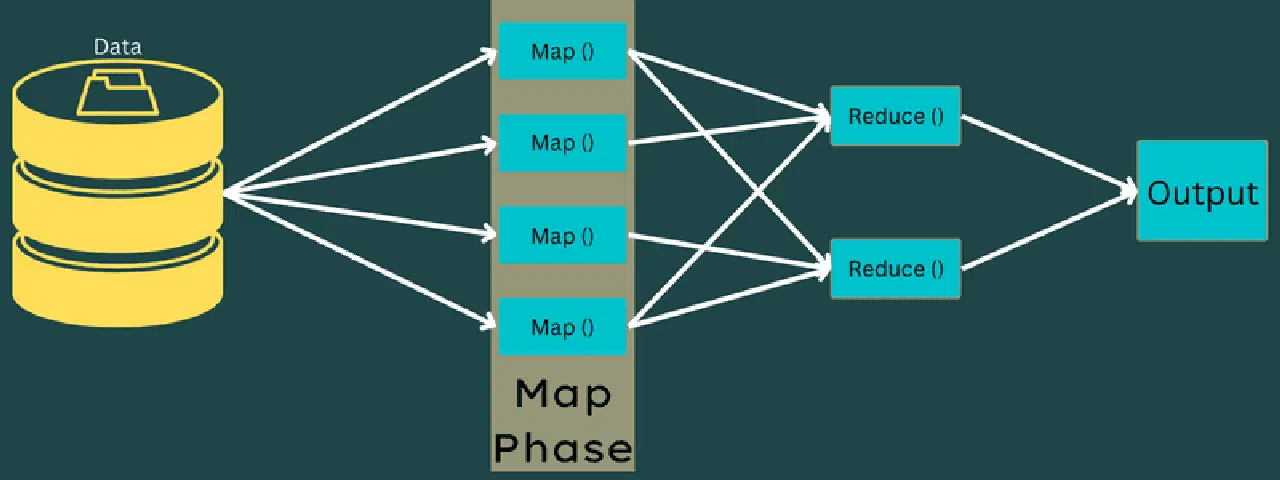
Cette phase comporte deux tâches : les divisions et la cartographie. Les divisions désignent les sous-parties ou les sections du travail séparées du travail principal. On les appelle également divisions d'entrée. Une division d'entrée est donc un bloc d'entrée consommé par une carte.
Ensuite, la tâche de cartographie entre en jeu. Elle est considérée comme la première phase lors de l'exécution d'un programme de réduction de carte. Les données de chaque division sont transmises à une fonction de carte pour être traitées et générer la sortie.
La fonction Map() s'exécute en mémoire sur les paires clé-valeur d'entrée, générant une paire clé-valeur intermédiaire. Cette nouvelle paire clé-valeur servira d'entrée à la fonction Reduce() ou Reducer.
Réduire
Les paires clé-valeur intermédiaires issues de la phase de mappage servent d'entrée à la fonction Reduce ou Reducer. Cette phase implique deux tâches : le mélange et la réduction.
Les paires clé-valeur obtenues sont triées et mélangées avant d'être envoyées au réducteur. Ce dernier regroupe ou agrège les données en fonction de leur paire clé-valeur selon l'algorithme de réduction défini par le développeur.
Les valeurs de la phase de brassage sont combinées pour générer une valeur de sortie. Cette phase synthétise l'ensemble des données.
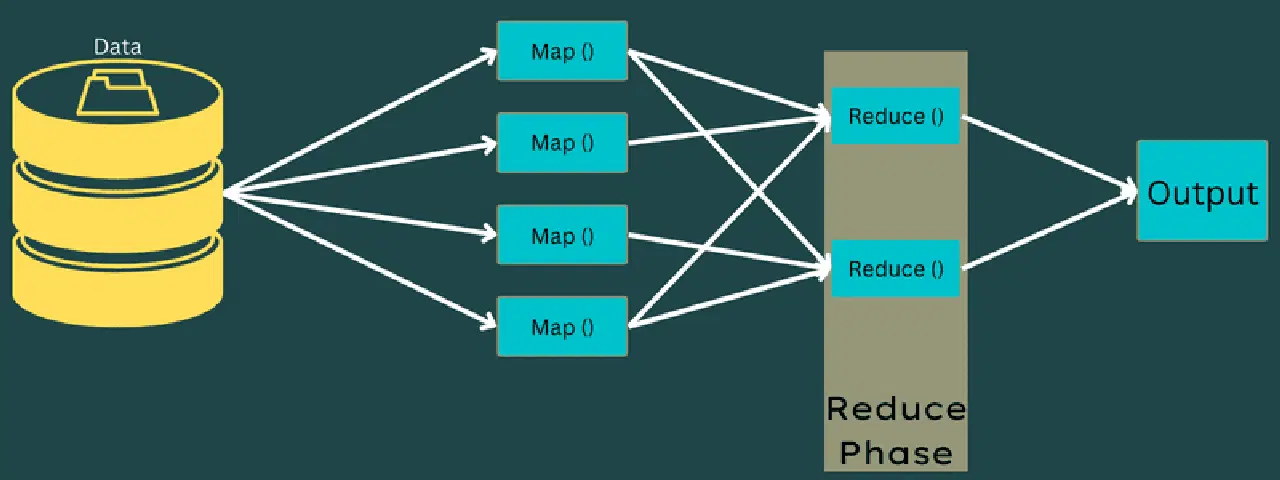
Le processus d'exécution des tâches Map et Reduce est contrôlé par les entités suivantes :
- Suivi des travaux : Le suivi des travaux agit comme un maître, responsable de l'exécution complète d'un job soumis. Il gère tous les jobs et ressources d'un cluster. De plus, le suivi des tâches planifie chaque carte ajoutée sur le suivi des tâches qui s'exécute sur un nœud de données spécifique.
- Plusieurs trackers de tâches : Les trackers de tâches fonctionnent comme des esclaves, exécutant les tâches selon les instructions du Job Tracker. Un tracker de tâche est déployé sur chaque nœud du cluster, exécutant les tâches Mapper et Reducer.
Un job est divisé en plusieurs tâches qui s'exécutent sur différents nœuds de données d'un cluster. Le Job Tracker coordonne le travail en planifiant les tâches et en les exécutant sur plusieurs nœuds. Le tracker de tâche sur chaque nœud exécute des parties du job.
Les trackers de tâches envoient des rapports d'avancement au Job Tracker. Ils envoient également un signal de "battement de cœur" au Job Tracker pour indiquer l'état du système. En cas d'échec, un tracker de tâches peut replanifier le travail sur un autre tracker de tâches.
Phase de sortie : Cette phase génère les paires clé-valeur finales issues du réducteur. Un formateur de sortie peut être utilisé pour traduire ces paires et les enregistrer dans un fichier à l'aide d'un enregistreur d'enregistrement.
Pourquoi utiliser MapReduce ?
Voici les avantages qui expliquent pourquoi il est pertinent d'utiliser MapReduce dans les applications Big Data :
Traitement parallèle
MapReduce permet de diviser une tâche en différentes parties, traitées simultanément par plusieurs nœuds. Cela réduit la complexité des tâches importantes et accélère considérablement le traitement des données, car les tâches sont exécutées en parallèle sur différentes machines.
Localité des données
MapReduce adopte une approche où l'unité de traitement est déplacée vers les données, et non l'inverse.
Traditionnellement, les données étaient transférées vers l'unité de traitement, ce qui entraînait des défis comme des coûts élevés, des temps de traitement longs, une surcharge du nœud maître, des échecs fréquents et une baisse des performances du réseau.
MapReduce surmonte ces obstacles en amenant l'unité de traitement aux données, ce qui répartit les données entre différents nœuds où chaque nœud traite une partie des données. Cela garantit la rentabilité et réduit le temps de traitement. Aucun nœud n'est surchargé.
Sécurité

Le modèle MapReduce offre une sécurité renforcée en protégeant les applications contre les accès non autorisés et en améliorant la sécurité du cluster.
Évolutivité et flexibilité
MapReduce est un cadre hautement évolutif. Il permet d'exécuter des applications sur plusieurs machines en utilisant des données de plusieurs téraoctets. Il offre également la flexibilité de traiter des données structurées, semi-structurées ou non structurées de n'importe quel format ou taille.
Simplicité
Les programmes MapReduce peuvent être écrits dans de nombreux langages de programmation comme Java, R, Perl, Python, etc. La simplicité du modèle le rend facile à maîtriser, tout en garantissant le respect des exigences en matière de traitement de données.
Cas d'utilisation de MapReduce
- Indexation de texte intégral : MapReduce est utilisé pour l'indexation de texte intégral. Le mapper segmente chaque mot ou expression dans un document, tandis que le réducteur écrit tous les éléments mappés dans un index.
- Calcul du Pagerank : Google utilise MapReduce pour calculer le Pagerank.
- Analyse des journaux : MapReduce analyse les fichiers journaux. Il peut diviser un fichier journal volumineux en plusieurs parties, tandis que le mapper recherche les pages Web consultées.
Une paire clé-valeur est envoyée au réducteur si une page Web est repérée dans le journal. La page Web devient la clé, et l'index "1" la valeur. Le réducteur agrège les pages Web, ce qui permet de calculer le nombre total de visites pour chaque page.

- Reverse Web-Link Graph : Ce framework est également utilisé pour Reverse Web-Link Graph. La fonction Map () prend en entrée la source ou la page Web et renvoie la cible de l'URL et la source.
La fonction Reduce() regroupe la liste de chaque URL source associée à l'URL cible. Enfin, elle restitue les sources et la cible.
- Comptage de mots : MapReduce permet de calculer le nombre d'occurrences d'un mot dans un document donné.
- Réchauffement climatique : Les organisations, les gouvernements et les entreprises utilisent MapReduce pour traiter les problèmes liés au réchauffement climatique.
Par exemple, pour évaluer l'augmentation de la température de l'océan due au réchauffement climatique, vous pouvez collecter d'importantes quantités de données sur la température, la latitude, la longitude, la date, etc. Ces données nécessitent plusieurs tâches de carte et de réduction pour produire un résultat précis à l'aide de MapReduce.
- Essais de médicaments : Alors que traditionnellement, les scientifiques et les mathématiciens collaboraient pour formuler de nouveaux médicaments, les services informatiques peuvent maintenant résoudre les problèmes qui nécessitaient des supercalculateurs. L'efficacité d'un médicament sur un groupe de patients peut être analysée plus facilement grâce à MapReduce.
- Autres applications : MapReduce traite des données massives qui ne rentreraient pas dans une base de données relationnelle. Il utilise des outils de science des données pour les exécuter sur différents ensembles de données distribués.
La robustesse et la simplicité de MapReduce en font une solution applicable dans les secteurs militaire, commercial, scientifique, etc.
Conclusion
MapReduce est une avancée technologique majeure, un processus à la fois plus rapide, plus simple, plus rentable et moins gourmand en temps. Ses avantages et son adoption croissante le rendent incontournable dans l'industrie et les organisations.
N'hésitez pas à explorer les ressources disponibles pour approfondir vos connaissances sur le Big Data et Hadoop.