L’analyse du langage naturel permet aux machines de décrypter nos paroles et de les transformer en instructions exécutables. Explorons le fonctionnement de cette technologie et son impact sur notre quotidien.
Comprendre le Traitement du Langage Naturel
Que ce soit avec Alexa, Siri, Google Assistant, Bixby ou Cortana, presque tout détenteur de smartphone ou d’enceinte connectée possède un assistant vocal. Ces assistants deviennent chaque année plus performants pour interpréter et exécuter nos requêtes. Mais comment ces systèmes comprennent-ils nos paroles? C’est grâce au traitement du langage naturel, ou TLN.
Historiquement, les logiciels étaient limités à un ensemble précis de commandes. Un fichier s’ouvrait après un clic sur « Ouvrir », une feuille de calcul effectuait un calcul basé sur des symboles et des noms de fonctions. Un programme communique en utilisant le langage de programmation dans lequel il a été codé, générant une sortie en réponse à une entrée reconnue. Dans ce contexte, les mots sont semblables à des leviers mécaniques, produisant toujours la même action.
Ceci contraste avec les langues humaines, complexes, non structurées et riches en nuances de sens, variant selon la structure des phrases, le ton, l’accent, le rythme, la ponctuation et le contexte. Le traitement du langage naturel, branche de l’intelligence artificielle, cherche à rapprocher la compréhension machine et le langage humain. Il permet aux machines de réagir à notre langage naturel (parlé ou écrit) de manière appropriée.
Cette prouesse est rendue possible par l’analyse de grandes quantités de données pour extraire la signification des différents éléments du langage, au-delà du simple sens des mots. Ce processus est lié à l’apprentissage automatique, qui permet aux ordinateurs de s’améliorer en accumulant des données. C’est pourquoi la plupart des systèmes de traitement du langage naturel semblent progresser avec l’usage.
Pour mieux comprendre, examinons deux des techniques fondamentales utilisées en TLN pour analyser le langage et l’information.
La Tokenisation
La tokenisation consiste à découper le discours en mots ou en phrases, chaque fragment étant un token. C’est ce qui se passe lorsque vos paroles sont analysées. Si simple en apparence, c’est en pratique un processus complexe.
Imaginez utiliser une fonction de dictée vocale pour envoyer un message à un ami. Vous dictez : « Rendez-vous au parc ». Votre téléphone enregistre votre voix et l’algorithme de dictée vocale doit fragmenter cette phrase en tokens, qui seraient alors « Rendez-« , « vous », « au » et « parc ».
Les pauses entre les mots varient d’une personne à l’autre et certaines langues ont des pauses moins audibles entre les mots. La tokenisation est donc un processus qui diffère considérablement selon les langues et les dialectes.
Racine et Lemmatisation
La racinisation et la lemmatisation ont pour but de supprimer les ajouts ou variations d’un mot, pour obtenir sa forme de base que la machine peut reconnaître. Cela vise à uniformiser l’interprétation du discours malgré des mots différents qui expriment des concepts similaires, améliorant ainsi l’efficacité du traitement TLN.
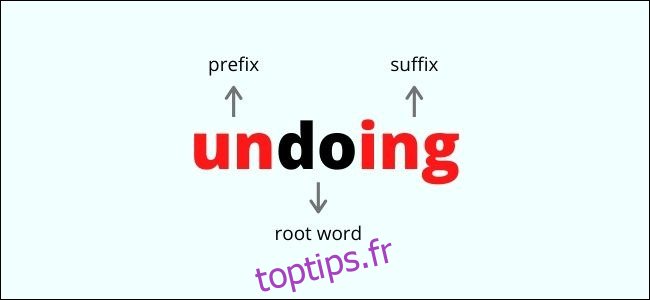
La racinisation est un processus simple et rapide qui consiste à supprimer les affixes (préfixes et suffixes) d’un mot. Elle réduit ainsi le mot à sa forme la plus basique en enlevant simplement certaines lettres. Par exemple :
«Marcher» devient «march»
«Plus rapide» devient «rapid»
«Gravité» devient «grav»
On peut voir que la racinisation peut altérer le sens d’un mot. « Gravité » et « grav » ne sont pas équivalents, mais le suffixe « ité » a été retiré.
La lemmatisation, plus avancée, consiste à ramener un mot à sa forme de base, appelée lemme. Elle tient compte du contexte et de l’usage du mot dans la phrase. Elle implique la recherche d’un terme dans une base de données de mots et de leurs lemmes correspondants. Par exemple :
«Sont» devient «être»
«Fonctionnement» devient «Fonctionner»
«Gravité» devient «grave»
Ici, la lemmatisation a correctement transformé «gravité» en «grave», qui est son lemme et sa racine.
Applications du TLN et Perspectives d’Avenir
Les exemples précédents ne sont qu’un aperçu des possibilités du traitement du langage naturel, un domaine aux multiples applications dans notre vie quotidienne. Voici quelques exemples d’utilisation du TLN :
Texte prédictif : lorsque vous rédigez un message sur votre smartphone, celui-ci suggère des mots basés sur votre saisie ou sur les mots que vous utilisez fréquemment.
Traduction automatique : les services de traduction largement utilisés, comme Google Traduction, intègrent des techniques de TLN perfectionnées pour analyser et traduire des langues.
Chatbots : le TLN est au cœur des chatbots intelligents, notamment en service clientèle, où ils aident les clients et traitent les demandes avant intervention humaine.
De nouvelles applications sont en développement dans des domaines comme les médias, la santé, la gestion des lieux de travail et la finance. Nous pourrions un jour dialoguer de manière sophistiquée avec des robots.
Pour approfondir le sujet, de nombreuses ressources sont disponibles sur le Blog Vers la science des données ou auprès du Groupe de traitement du langage naturel de Stanford.