Qu'est-ce que le partage de base de données ?
Techniques d'Amélioration des Performances Systèmes : Le Sharding Expliqué
Le partitionnement de base de données, ou "sharding", est une approche cruciale pour optimiser la scalabilité horizontale des systèmes de grande envergure.
Dans la réalité, la plupart des systèmes s'appuient sur un serveur de base de données qui doit gérer un volume important de requêtes de lecture et un nombre considérable de requêtes d'écriture. Cette situation peut rapidement saturer le serveur et impacter négativement les performances globales du système.
Pour contrer ces problèmes et améliorer l'efficacité d'un système, diverses stratégies existent, telles que la réplication de base de données et le sharding. Dans ce guide, nous allons explorer en détail ces techniques d'amélioration des performances, en commençant par :
- L'augmentation des capacités du serveur de base de données
- La réplication de base de données
- Le partitionnement horizontal
Après avoir analysé ces méthodes, nous nous concentrerons sur le fonctionnement du sharding de base de données, en examinant ses avantages et ses limitations.
Commençons notre exploration !
Méthodes pour Booster les Performances du Système
Examinons de plus près les méthodes permettant d'améliorer les performances du système face aux goulots d'étranglement causés par le serveur de base de données :
#1. Accroissement des Ressources du Serveur de Base de Données
L'augmentation de la puissance du serveur de base de données peut sembler une solution simple. Cela peut impliquer l'amélioration de la puissance de calcul, l'ajout de mémoire vive (RAM), etc.
Néanmoins, cette approche comporte des limitations. Il est impossible de disposer d'un serveur aux capacités de stockage et de traitement illimitées. De plus, au-delà d'un certain seuil, les gains d'efficacité diminuent.
#2. Réplication de Base de Données
Lorsque le serveur de base de données est surchargé par un volume trop important de requêtes, la réplication de base de données peut être une solution pertinente.
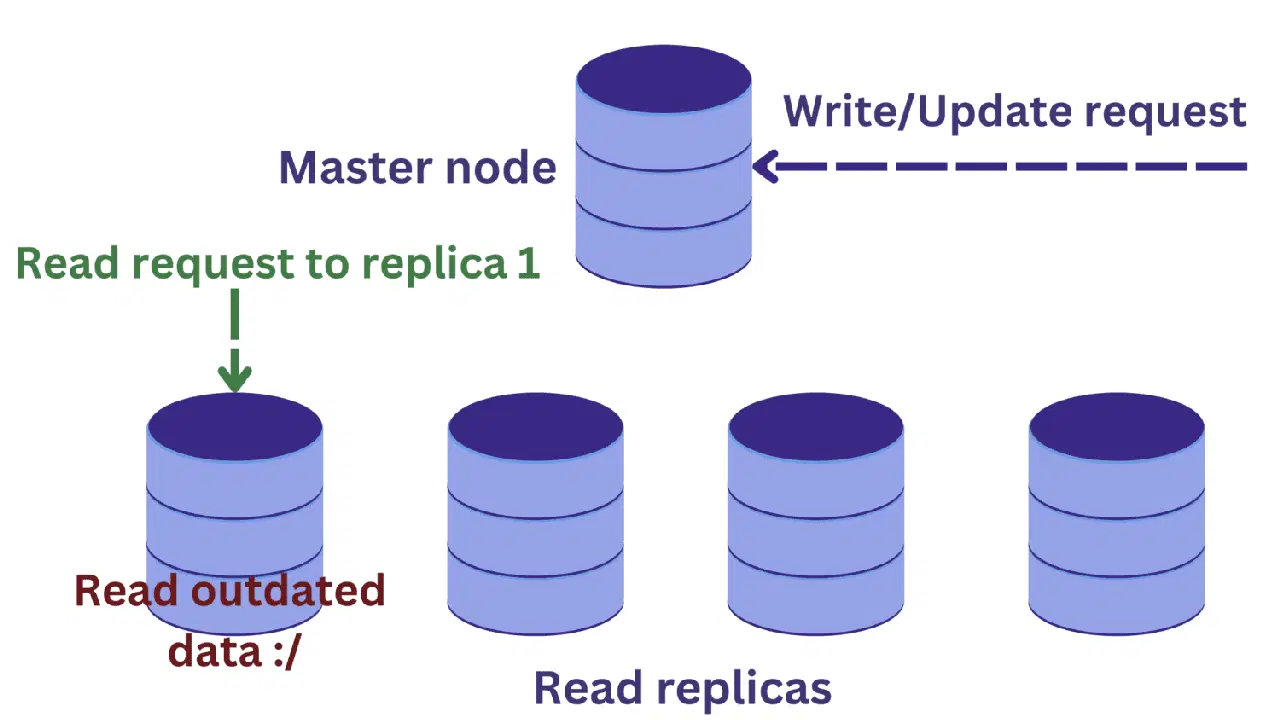
Dans ce scénario, un nœud principal reçoit généralement les requêtes d'écriture, tandis que plusieurs instances répliquées sont dédiées à la lecture.
Cela améliore la disponibilité et diminue la surcharge du système. Les requêtes de lecture peuvent être traitées en parallèle par les réplicas, augmentant ainsi l'efficacité du traitement.
Cependant, un nouveau problème se pose. Les modifications apportées au nœud principal par les requêtes d'écriture doivent être propagées périodiquement aux réplicas.
Imaginons qu'une requête de lecture arrive sur l'un des réplicas au moment où une opération d'écriture est en cours sur le nœud principal. Si les modifications n'ont pas encore été propagées, le réplica peut renvoyer des données obsolètes, ce qui n'est pas souhaitable.
#3. Partitionnement Horizontal
Le partitionnement horizontal est une autre approche pour optimiser les performances du système. Au lieu d'une seule table volumineuse avec des milliards de lignes, comme une table de clients et de transactions, on divise cette table en plusieurs partitions, ou tables plus petites. Les bases de données relationnelles comme PostgreSQL prennent en charge nativement le partitionnement.
Malgré cette division, toutes les partitions restent généralement au sein d'une même instance de serveur de base de données. La différence est que l'on peut désormais lire les données à partir de partitions au lieu d'une seule table volumineuse.
Par conséquent, lors d'une augmentation du nombre de requêtes entrantes, le serveur peut encore être saturé par la demande.
Fonctionnement du Sharding de Base de Données
Après avoir discuté des approches pour améliorer les performances du système et de leurs limitations, explorons le fonctionnement du sharding de base de données.
Le sharding consiste à diviser une base de données unique en plusieurs bases de données plus petites, chacune s'exécutant sur une instance de serveur de base de données distincte. Chaque petite base de données est appelée un "shard". Chaque shard contient un sous-ensemble unique de données.
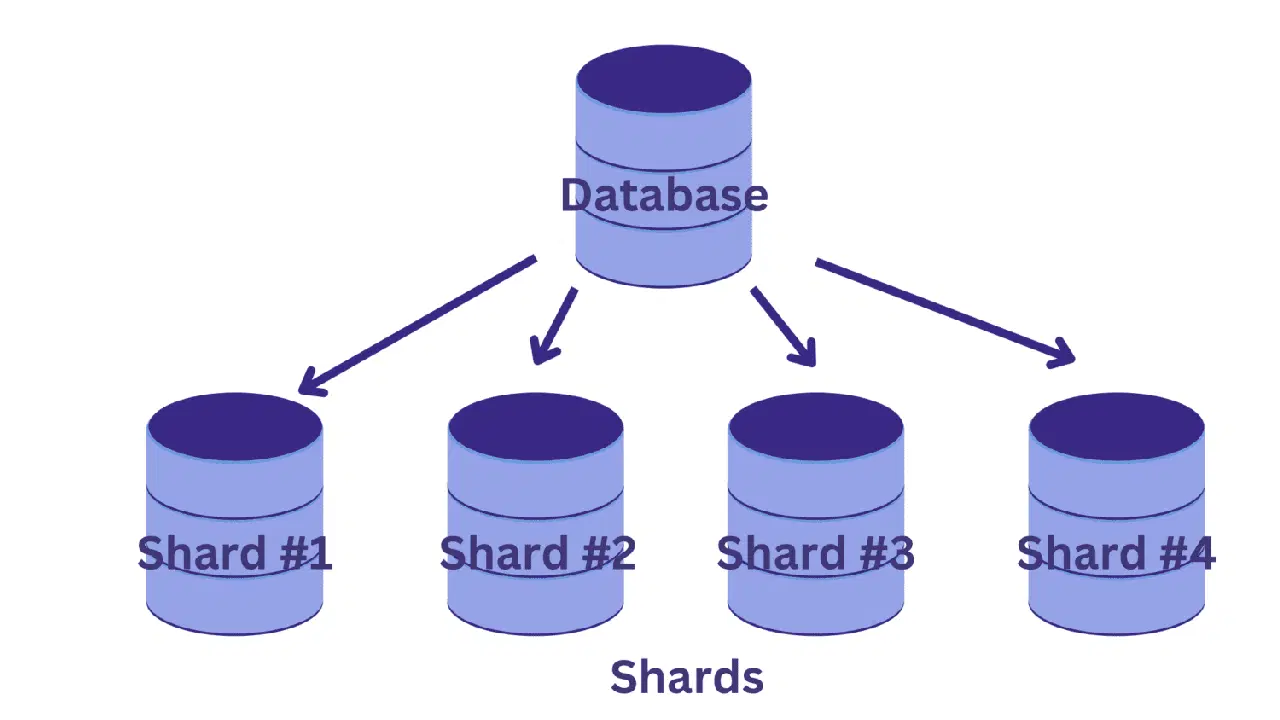
Mais comment répartir les données entre les shards ? Et comment déterminer quelles lignes appartiennent à quel shard ?
🔑 C'est ici qu'intervient la clé de sharding.
Comprendre la Clé de Sharding
La clé de sharding est généralement une colonne (ou une combinaison de colonnes) de la table de base de données. Son choix est crucial pour garantir une distribution uniforme des données entre les shards, évitant ainsi qu'un shard ne devienne disproportionnellement plus grand que les autres.
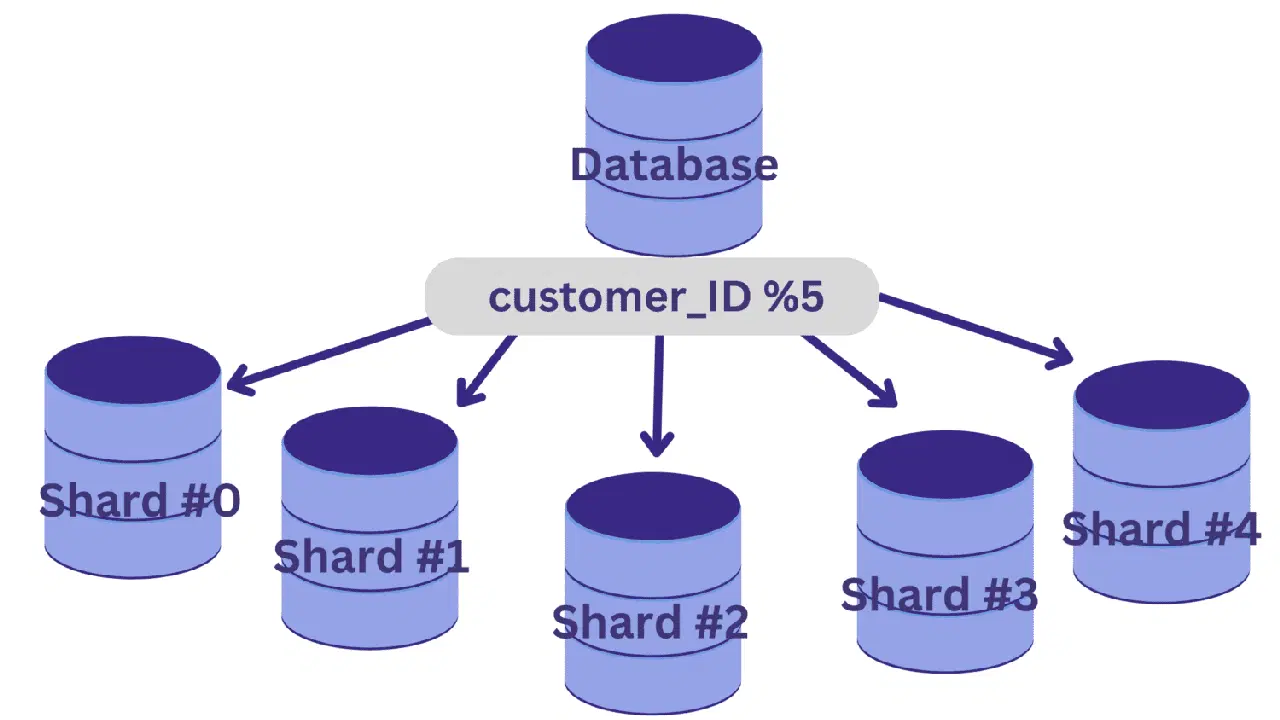
Dans une base de données qui gère les données clients et les transactions, l'identifiant client (customer_ID) peut être un bon candidat pour la clé de sharding.
Une fois la clé de sharding choisie, une fonction de hachage est utilisée pour déterminer quel shard doit recevoir chaque ligne.
Par exemple, si nous souhaitons diviser la base de données en cinq shards (shard #0 à shard #4) en utilisant le customer_ID comme clé, une fonction de hachage simple pourrait être `customer_ID % 5`.
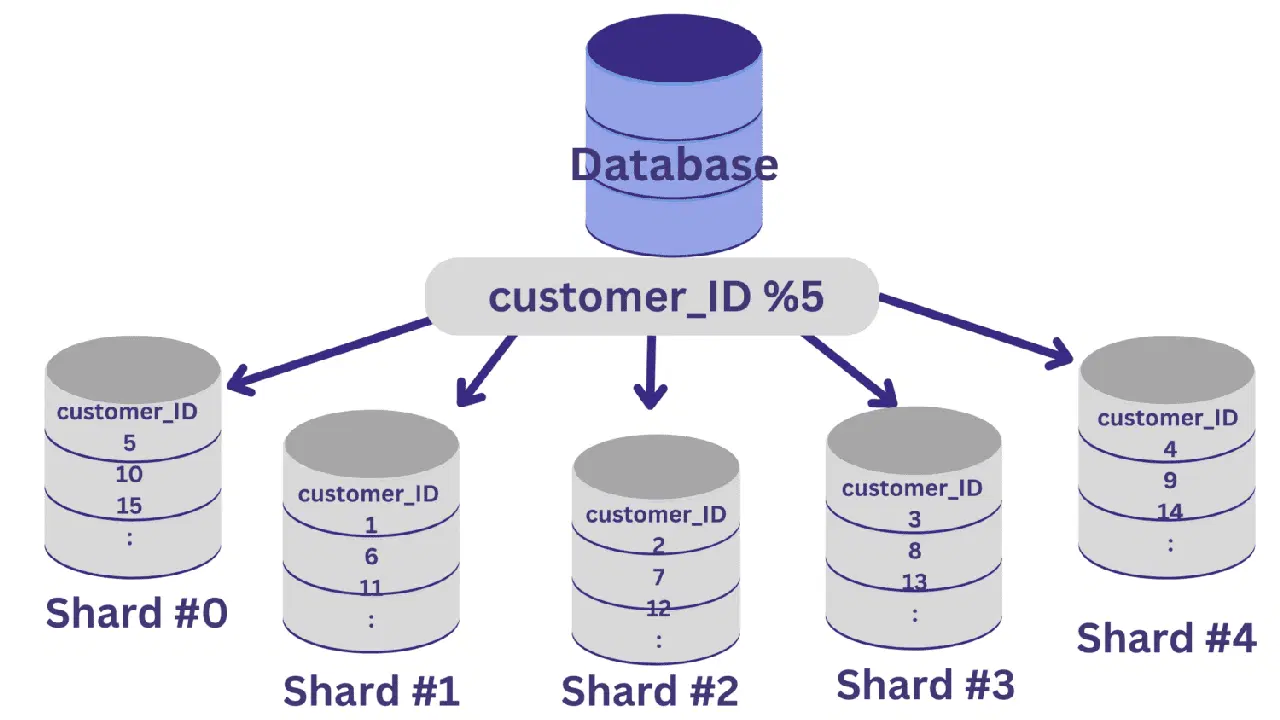
Toutes les valeurs `customer_ID` dont le reste de la division par 5 est 0 seront affectées au shard #0. Celles dont le reste est 1, 2, 3 ou 4 seront affectées respectivement aux shards #1, #2, #3 et #4.
Une fois le sharding implémenté, une couche de routage est indispensable pour acheminer les requêtes entrantes vers le shard approprié.
Avantages du Sharding de Base de Données
Voici quelques-uns des avantages du sharding de base de données :
#1. Forte Scalabilité
Le sharding permet de diviser une base de données en fragments plus petits et donc de mettre à l'échelle horizontalement l'infrastructure de base de données.
#2. Haute Disponibilité
Avec une seule instance de serveur de base de données traitant toutes les requêtes, un point de défaillance unique existe. Si ce serveur tombe en panne, l'ensemble de l'application est hors service.
Le sharding diminue cette vulnérabilité car la probabilité que tous les shards soient indisponibles simultanément est faible. Ainsi, si un shard tombe en panne, les autres peuvent continuer à traiter les requêtes, assurant une meilleure disponibilité et une tolérance accrue aux pannes.
Limitations du Sharding de Base de Données
Analysons maintenant certaines limitations du sharding de base de données :
#1. Complexité Accrue
Malgré ses avantages en termes de scalabilité et de tolérance aux pannes, le sharding introduit une complexité importante dans le système.
La mise en correspondance des enregistrements avec les shards, la gestion de la couche de routage des requêtes, tout cela contribue à augmenter la complexité globale.
#2. Nécessité de Repartitionnement
Une autre limitation est la nécessité potentielle de repartitionner les données.
Même en utilisant une fonction de hachage pour assurer une distribution équitable des enregistrements, il est possible qu'un shard devienne plus volumineux que les autres et doive être "éclaté" à nouveau. Cela implique un travail supplémentaire et une surcharge.
#3. Requêtes Complexes
Lorsque des requêtes d'analyse impliquant des jointures sont nécessaires, il faut consulter les données de plusieurs shards. Cette opération peut s'avérer complexe et exigeante. La dénormalisation des bases de données peut pallier ce problème, mais elle nécessite des efforts supplémentaires.
Conclusion
En résumé, nous avons exploré les différentes méthodes d'optimisation des bases de données.
L'augmentation des ressources matérielles n'est pas toujours optimale, il est donc déconseillé de renforcer uniquement l'instance du serveur. Nous avons également analysé la réplication et le partitionnement horizontal, et leurs limites.
Nous avons ensuite appris comment le sharding divise une base de données en fragments plus petits et plus faciles à gérer. L'importance du choix de la clé de sharding et de la mise en place d'une couche de routage ont été soulignées.
Le sharding offre des avantages tels qu'une haute disponibilité et une scalabilité accrue, mais comporte des inconvénients comme la complexité de la configuration et du repartitionnement.
En conclusion, le sharding doit être envisagé lorsque ses avantages l'emportent sur la complexité qu'il introduit. Il est également important de comparer les différentes bases de données relationnelles AWS pour une solution optimale.