Qu'est-ce que Google JAX ? Tout ce que tu as besoin de savoir
Google JAX, ou Just After Execution, est un cadre de travail développé par Google, spécialement conçu pour accélérer les opérations d'apprentissage automatique.
Ce framework peut être considéré comme une bibliothèque Python, ayant pour mission d'optimiser l'exécution des tâches, les calculs scientifiques, les transformations de fonctions, l'apprentissage profond, les réseaux neuronaux et bien d'autres applications.
Présentation de Google JAX
NumPy est un package essentiel de calcul en Python, proposant diverses fonctions comme les agrégations, les opérations vectorielles, l'algèbre linéaire, les manipulations de tableaux et de matrices à n dimensions, ainsi que de nombreuses fonctionnalités avancées.
Que diriez-vous d'une méthode pour accélérer davantage les calculs effectués via NumPy, en particulier pour les vastes ensembles de données ?
Existe-t-il une solution qui fonctionnerait de manière équivalente sur différents types de processeurs, tels que les GPU ou les TPU, sans qu'aucune modification de code ne soit nécessaire ?
Serait-il envisageable que le système puisse réaliser des transformations de fonctions composables, de manière automatique et plus efficace ?
Google JAX est une bibliothèque (ou un cadre de travail) qui répond précisément à ces besoins et propose bien plus encore. Sa conception est axée sur l'optimisation des performances et l'exécution efficace des tâches d'apprentissage automatique (ML) et d'apprentissage profond. Google JAX intègre les fonctionnalités de transformation suivantes, le distinguant des autres bibliothèques ML et facilitant le calcul scientifique avancé pour l'apprentissage profond et les réseaux neuronaux :
- Différenciation automatique
- Vectorisation automatique
- Parallélisation automatique
- Compilation à la volée (JIT)
Particularités de Google JAX
L'ensemble des transformations exploitent XLA (Accelerated Linear Algebra) pour une performance accrue et une optimisation de la mémoire. XLA est un moteur de compilation d'optimisation spécifique au domaine, destiné à l'algèbre linéaire et à l'accélération des modèles TensorFlow. L'intégration de XLA dans votre code Python ne nécessite pas de modifications significatives du code !
Approfondissons chacune de ces fonctionnalités.
Fonctionnalités de Google JAX
Google JAX est doté de fonctions de transformation composables essentielles qui améliorent les performances et optimisent l'exécution des tâches d'apprentissage profond. Par exemple, la différenciation automatique pour obtenir le gradient d'une fonction et déterminer les dérivées de n'importe quel ordre. De même, la parallélisation automatique et JIT permettent l'exécution simultanée de plusieurs tâches. Ces transformations sont indispensables pour des applications telles que la robotique, les jeux et la recherche.
Une fonction de transformation composable est une fonction pure qui transforme un ensemble de données en une autre forme. Elles sont dites composables, car elles sont autonomes (c'est-à-dire sans dépendance vis-à-vis du reste du programme) et sans état (la même entrée produira toujours la même sortie).
Y(x) = T : (f(x))
Dans cette équation, f(x) est la fonction originale à laquelle une transformation est appliquée. Y(x) est la fonction résultante après l'application de la transformation.
Par exemple, si vous avez une fonction nommée « total_bill_amt » et que vous souhaitez que le résultat soit une transformation de fonction, vous pouvez simplement utiliser la transformation désirée, comme le gradient (grad):
grad_total_bill = grad(total_bill_amt)
En transformant des fonctions numériques à l'aide de fonctions telles que grad(), nous pouvons obtenir aisément leurs dérivées d'ordre supérieur, largement utilisées dans les algorithmes d'optimisation d'apprentissage profond, comme la descente de gradient, rendant ainsi ces algorithmes plus rapides et plus efficaces. Par ailleurs, en utilisant jit(), nous pouvons compiler des programmes Python juste-à-temps (de manière paresseuse).
#1. Différenciation automatique
Python utilise la fonction autograd pour différencier automatiquement le code NumPy du code Python natif. JAX exploite une version modifiée d'autograd (grad), associée à XLA (Accelerated Linear Algebra), pour réaliser la différenciation automatique et trouver les dérivées de tous les ordres pour les GPU (Graphic Processing Units) et les TPU (Tensor Processing Units).
Note rapide sur les TPU, GPU et CPU : le CPU, ou unité centrale de traitement, gère toutes les opérations d'un ordinateur. Le GPU est un processeur additionnel qui amplifie la puissance de calcul et exécute les opérations haut de gamme. Le TPU est une unité puissante, conçue pour les tâches complexes et lourdes telles que l'IA et les algorithmes d'apprentissage profond.
Dans l'esprit d'autograd, capable de se différencier à travers des boucles, récursions, branches, etc., JAX emploie la fonction grad() pour calculer les gradients en mode inverse (rétropropagation). De plus, nous pouvons différencier une fonction de n'importe quel ordre en utilisant grad :
grad(grad(grad(sin θ))) (1.0)
Différenciation automatique d'ordre supérieur
Comme mentionné précédemment, grad est très utile pour déterminer les dérivées partielles d'une fonction. Une dérivée partielle peut servir à calculer la descente de gradient d'une fonction de coût par rapport aux paramètres du réseau neuronal en apprentissage profond, afin de minimiser les pertes.
Calcul de la dérivée partielle
Imaginons qu'une fonction dépende de plusieurs variables, x, y et z. La recherche de la dérivée d'une variable, tout en maintenant les autres constantes, est appelée une dérivée partielle. Considérons une fonction :
f(x,y,z) = x + 2y + z2
Exemple illustrant la dérivée partielle
La dérivée partielle de x sera ∂f/∂x, indiquant la façon dont une fonction évolue par rapport à une variable lorsque les autres restent constantes. Si l'on effectue ce calcul manuellement, il est nécessaire d'écrire un programme pour différencier, de l'appliquer pour chaque variable, puis de calculer la descente du gradient. Cette approche deviendrait complexe et chronophage pour un grand nombre de variables.
La différenciation automatique décompose une fonction en un ensemble d'opérations élémentaires, comme +, -, *, / ou sin, cos, tan, exp, etc., puis applique la règle de la chaîne pour calculer la dérivée. Cela peut se faire en mode avant et arrière.
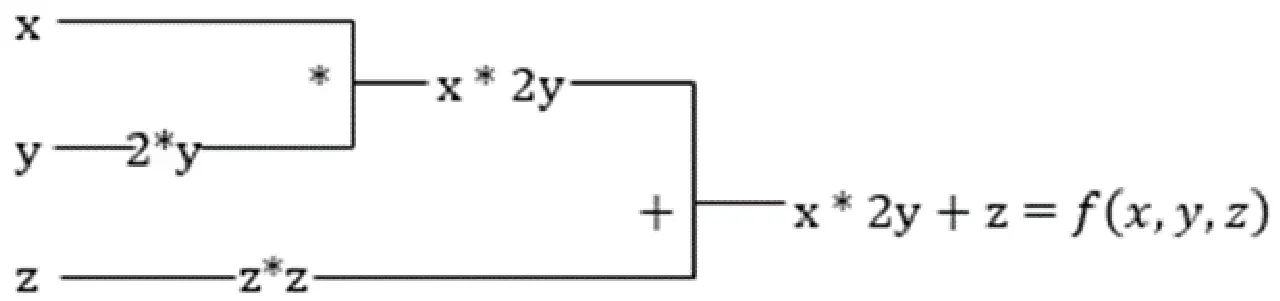
Ce n'est pas tout ! Tous ces calculs sont effectués à une vitesse incroyable (imaginez un million de calculs comme ceux-ci et le temps que cela pourrait prendre !). XLA se charge de la rapidité et des performances.
#2. Algèbre linéaire accélérée
Reprenons l'équation précédente. Sans XLA, le calcul demanderait trois cœurs (ou plus), chaque cœur effectuant une tâche plus restreinte. Par exemple,
Cœur k1 –> x * 2y (multiplication)
k2 –> x * 2y + z (addition)
k3 –> Réduction
Si cette même tâche est effectuée par XLA, un unique cœur gère toutes les opérations intermédiaires en les fusionnant. Les résultats intermédiaires des opérations élémentaires sont diffusés en continu, au lieu d'être stockés en mémoire, ce qui permet d'économiser de la mémoire et d'accroître la vitesse.
#3. Compilation à la volée
JAX utilise en interne le compilateur XLA pour améliorer la vitesse d'exécution. XLA peut accroître la vitesse du CPU, du GPU et du TPU. Tout cela est possible en utilisant l'exécution du code JIT. Pour l'employer, il est possible d'utiliser jit via import :
from jax import jit def ma_fonction(x): …………lignes de code ma_fonction_jit = jit(ma_fonction)
Une autre option consiste à décorer jit sur la définition de la fonction :
@jit def ma_fonction(x): …………lignes de code
Ce code est nettement plus rapide, car la transformation renverra la version compilée du code à l'appelant, au lieu d'utiliser l'interpréteur Python. Ceci est particulièrement efficace pour les entrées vectorielles, comme les tableaux et les matrices.
Ceci s'applique à l'ensemble des fonctions python existantes. Par exemple, les fonctions du package NumPy. Dans ce cas, il est nécessaire d'importer jax.numpy en tant que jnp plutôt que NumPy :
import jax import jax.numpy as jnp x = jnp.array([[1,2,3,4], [5,6,7,8]])
Une fois cette opération effectuée, l'objet tableau principal JAX, dénommé DeviceArray, se substitue au tableau NumPy standard. DeviceArray est paresseux ; les valeurs sont conservées dans l'accélérateur jusqu'à ce qu'elles soient requises. Cela signifie également que le programme JAX n'attend pas que les résultats reviennent au programme appelant (Python), suivant ainsi une répartition asynchrone.
#4. Vectorisation automatique (vmap)
Dans un contexte d'apprentissage automatique typique, les jeux de données comptent souvent un million de points de données, voire plus. Il est très probable que nous effectuions des calculs ou des manipulations sur chacun, ou la plupart, de ces points de données ; il s'agit là d'une tâche très gourmande en temps et en mémoire ! Par exemple, si l'on veut calculer le carré de chaque point de données dans un jeu de données, la première approche qui vient à l'esprit est de créer une boucle et de calculer le carré un par un !
Si ces points sont créés sous forme de vecteurs, il serait possible de réaliser l'ensemble des carrés en une seule fois, en effectuant des manipulations vectorielles ou matricielles sur les points de données avec NumPy. Que demander de plus si un programme peut effectuer cela automatiquement ? C'est précisément ce que réalise JAX ! Il peut vectoriser automatiquement tous les points de données afin de faciliter la réalisation des opérations dessus, rendant ainsi les algorithmes bien plus rapides et efficaces.
JAX exploite la fonction vmap pour la vectorisation automatique. Prenons le tableau suivant :
x = jnp.array([1,2,3,4,5,6,7,8,9,10]) y = jnp.square(x)
En procédant comme ci-dessus, la méthode square s'exécutera pour chaque point du tableau. Toutefois, en faisant comme suit :
vmap(jnp.square(x))
La méthode square ne s'exécutera qu'une seule fois, car les points de données sont désormais vectorisés automatiquement en utilisant vmap, avant l'exécution de la fonction. La boucle est reléguée au niveau élémentaire de fonctionnement, ce qui induit une multiplication matricielle plutôt qu'une multiplication scalaire, et améliore ainsi les performances.
#5. Programmation SPMD (pmap)
La programmation SPMD (Single Program Multiple Data) est un élément clé dans le domaine de l'apprentissage profond. Il est fréquent d'appliquer les mêmes fonctions à différents ensembles de données résidant sur plusieurs GPU ou TPU. JAX possède une fonction nommée pmap, qui permet une programmation parallèle sur plusieurs GPU, ou tout autre accélérateur. À l'instar de JIT, les programmes employant pmap seront compilés par XLA et exécutés simultanément sur tous les systèmes. Cette parallélisation automatique fonctionne à la fois pour les calculs directs et inverses.
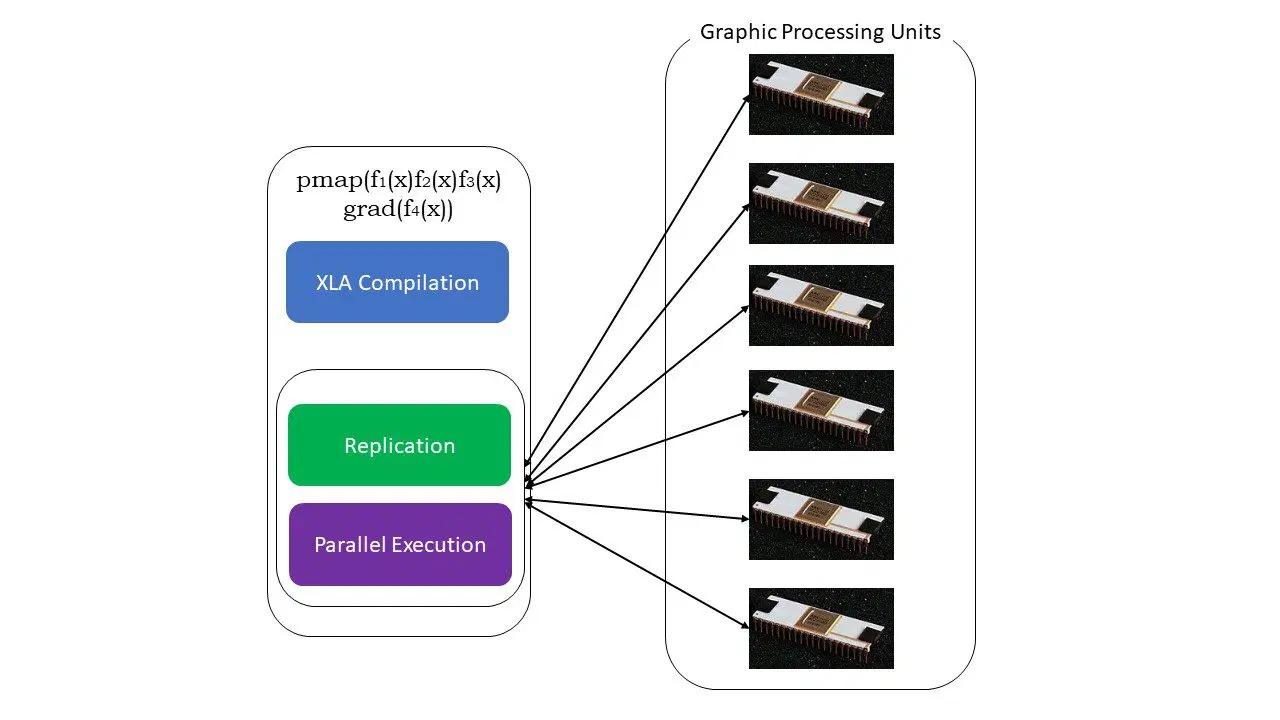
Fonctionnement de pmap
Il est possible d'appliquer plusieurs transformations en une seule fois, dans n'importe quel ordre, à toute fonction :
pmap(vmap(jit(grad (f(x)))))
Multiples transformations composables
Limites de Google JAX
Les développeurs de Google JAX ont pris en considération l'accélération des algorithmes d'apprentissage profond en introduisant ces transformations. Les fonctions et les packages de calcul scientifique sont construits sur le modèle de NumPy, ce qui permet de faciliter la prise en main. Cependant, JAX présente les limitations suivantes :
- Google JAX est encore en développement. Bien que son objectif premier soit l'optimisation des performances, il ne propose pas d'avantages notables pour le calcul CPU. NumPy semble être plus efficace et l'utilisation de JAX risque d'alourdir le processus.
- JAX est encore à ses débuts et a besoin de davantage de perfectionnement pour se hisser au niveau d'infrastructures telles que TensorFlow, qui est plus établi et qui possède plus de modèles prédéfinis, de projets open source et de ressources d'apprentissage.
- Actuellement, JAX n'est pas compatible avec le système d'exploitation Windows ; l'utilisation d'une machine virtuelle est donc nécessaire.
- JAX ne fonctionne que sur les fonctions pures, qui n'ont pas d'effets secondaires. Pour les fonctions avec effets secondaires, JAX n'est pas une option idéale.
Installation de JAX dans votre environnement Python
Si Python est configuré sur votre système et que vous souhaitez exécuter JAX sur votre machine locale (CPU), utilisez les commandes suivantes :
pip install --upgrade pip pip install --upgrade "jax[cpu]"
Pour exécuter Google JAX sur un GPU ou un TPU, suivez les indications fournies sur la page GitHubJAX. Pour configurer Python, rendez-vous sur la page des téléchargements officiels de python.
Conclusion
Google JAX est un outil idéal pour l'écriture d'algorithmes d'apprentissage profond, de robotique et de recherche. Malgré certaines limites, il est largement utilisé avec d'autres frameworks tels que Haiku, Flax, entre autres. Vous pourrez mesurer l'intérêt de JAX en exécutant des programmes et en constatant les différences de temps d'exécution du code avec et sans JAX. Pour commencer, n'hésitez pas à consulter la documentation officielle de Google JAX, très complète.