Pouvez-vous faire quelque chose à ce sujet ?
Les plateformes de médias sociaux explorent de nouvelles avenues pour monétiser les données de leurs utilisateurs, notamment par le biais d'accords avec des entreprises spécialisées dans l'intelligence artificielle. Cette pratique soulève des questions importantes concernant la confidentialité et la protection des informations personnelles. Alors, quelles sont les mesures que les utilisateurs peuvent prendre pour protéger leurs données et leur contenu ?
L'utilisation des données des réseaux sociaux pour l'entraînement de modèles d'IA générative suscite la controverse, mais cela n'empêche pas les plateformes de poursuivre ces pratiques de partage.
Meta, par exemple, utilise déjà les données de ses réseaux pour entraîner ses fonctionnalités d'IA générative, dévoilées lors de Meta Connect en 2023. Cela inclut l'assistant Meta AI et la création d'autocollants générés par IA sur WhatsApp. Mike Clark, directeur de la gestion des produits chez Meta, a confirmé dans un article que les publications partagées publiquement sur Instagram et Facebook, incluant photos et textes, ont été utilisées pour former les modèles d'IA générative.
Cette tendance se poursuit en 2024. Selon Reuters, Reddit a conclu un accord avec Google pour mettre le contenu de sa plateforme à disposition pour l'entraînement de modèles d'IA. Le dépôt S-1 de Reddit confirme que l'entreprise explore des accords de licence, soulignant l'importance des données Reddit pour la construction des technologies d'IA. Ils sont au début du processus d'octroi de licences à des tiers pour l'accès et l'analyse des données.
Bien que Meta et Reddit soient parmi les plus grandes plateformes, elles ne sont pas les seules. Un rapport de 404 Media révèle que Tumblr et WordPress.com prévoient également de vendre les données de leurs utilisateurs à des sociétés comme Midjourney et OpenAI.
Si vous utilisez Facebook, Instagram, Reddit, Tumblr ou WordPress.com, il est fort probable que votre contenu public ait déjà été exploité pour entraîner des modèles d'IA. Par exemple, l'outil de recherche du Washington Post montre que Reddit.com représente 7,9 millions de "tokens" dans l'ensemble de données C4 de Google, utilisé pour l'entraînement de Bard. Tumblr.com en compte 1,6 million, et même de petits blogs personnels sur WordPress.com peuvent être inclus.
Les accords en cours entre les entreprises d'IA et les plateformes sociales impliquent que ces données seront activement vendues et non simplement extraites du web.
Que pouvez-vous faire pour protéger vos données ?
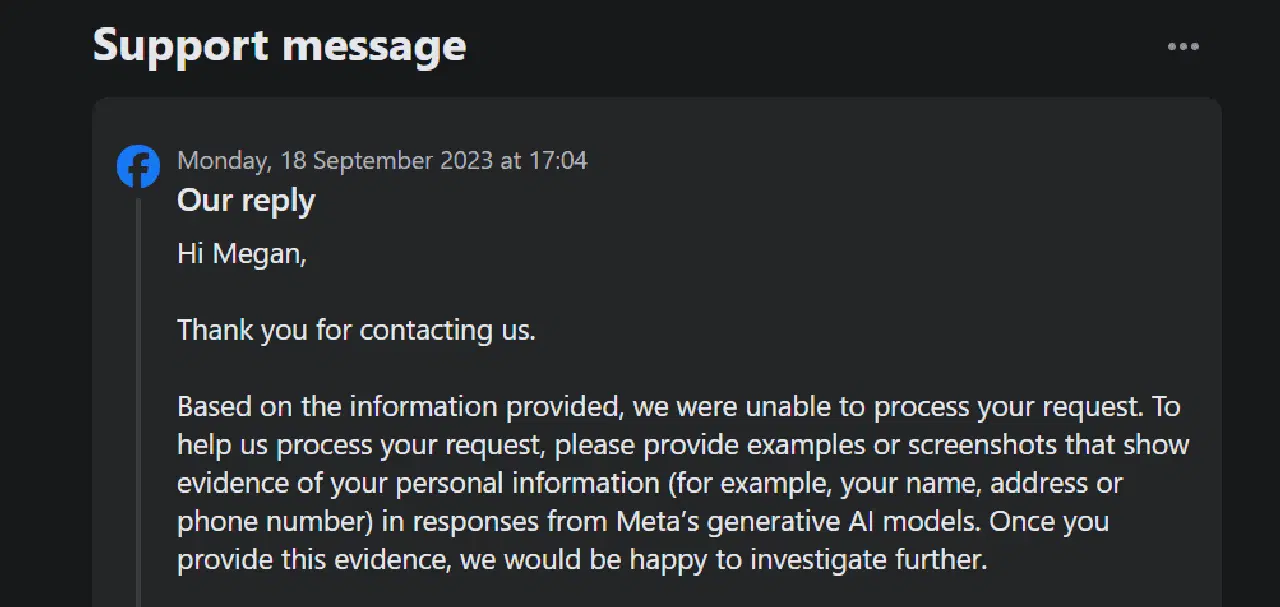
Meta a mis en place un formulaire permettant de s'opposer ou de restreindre le traitement de vos données personnelles par des tiers pour l'entraînement de modèles d'IA générative. Cependant, cette option ne vous permet pas de bloquer l'utilisation de vos données par Meta elle-même. De plus, la demande nécessite de prouver que vos informations apparaissent déjà dans les résultats de l'IA générative de Meta.
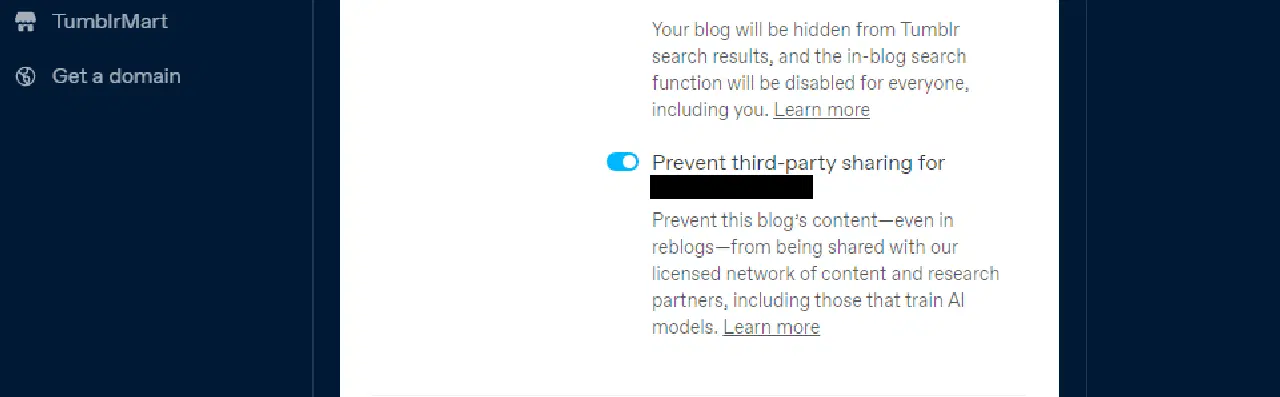
Tumblr a également ajouté une option pour refuser le partage de vos blogs publics avec des tiers, accessible via les paramètres de visibilité de votre blog.
Sur Instagram, rendre votre compte privé peut limiter l'utilisation de vos données. Cette mesure n'est pas une garantie, mais elle peut offrir une protection potentielle, étant donné que l'extraction de données se concentre principalement sur le contenu public. De même, rendre votre compte X (Twitter) privé peut apporter une protection supplémentaire, mais sans garantie absolue.
Une déclaration commune de divers commissaires à l'information et experts à travers le monde propose des actions pour minimiser les risques liés au "scraping" de données par les entreprises d'IA :
- Vérifiez les conditions d'utilisation et politiques de confidentialité des sites pour comprendre comment vos informations sont partagées.
- Limitez les informations que vous publiez en ligne, surtout les informations sensibles.
- Gérez vos paramètres de confidentialité.
- Réfléchissez aux conséquences à long terme des informations que vous partagez en ligne.
- Contactez la plateforme sociale ou le site si vous pensez que vos données ont été collectées de manière inappropriée. Si vous êtes insatisfait, déposez une plainte auprès de votre autorité de protection des données.
Vous pouvez aussi supprimer certaines informations si vous n'êtes pas à l'aise avec leur accès par des tiers, même si celles-ci ont déjà pu être collectées.
Malheureusement, les utilisateurs ont une marge de manœuvre limitée pour protéger leurs données contre les sociétés d'IA. Un réel contrôle sur ces informations ne viendra probablement qu'avec l'intervention des régulateurs.
| Points clés à retenir : |
|