Meilleures bibliothèques Python pour les scientifiques des données
Cet article examine et explique certaines des bibliothèques Python les plus performantes pour les professionnels de la science des données et les spécialistes de l'apprentissage automatique.
Python est un langage de choix dans ces deux domaines, notamment grâce à la richesse de ses bibliothèques.
Cette popularité est due à l'efficacité des bibliothèques Python pour la gestion des entrées/sorties de données, l'analyse, et diverses autres manipulations de données essentielles aux scientifiques des données et aux experts en apprentissage automatique.
Que sont les bibliothèques Python ?
Une bibliothèque Python est un ensemble complet de modules pré-compilés, incluant des classes et des méthodes. Ces collections permettent d'éviter aux développeurs de devoir écrire du code à partir de zéro.
Pourquoi Python est-il important en science des données et en apprentissage automatique ?
Python propose un vaste choix de bibliothèques de pointe, idéales pour les experts en apprentissage automatique et en science des données.
Sa syntaxe claire facilite l'implémentation d'algorithmes complexes d'apprentissage automatique. Cette simplicité réduit le temps d'apprentissage et améliore la compréhension.
Python permet également un développement rapide de prototypes et des tests d'applications efficaces.
La grande communauté Python est une ressource précieuse pour les scientifiques des données, leur permettant de trouver facilement des réponses à leurs questions.
À quoi servent les bibliothèques Python ?
Les bibliothèques Python jouent un rôle fondamental dans la création d'applications et de modèles pour l'apprentissage automatique et la science des données.
Elles offrent une grande aide en permettant la réutilisation de code. Ainsi, au lieu de tout réinventer, il suffit d'importer la bibliothèque appropriée pour implémenter une fonctionnalité spécifique dans un programme.
Bibliothèques Python utilisées en apprentissage automatique et en science des données
Les experts en science des données recommandent plusieurs bibliothèques Python que les passionnés du domaine doivent connaître. Selon leur application, ils utilisent différentes bibliothèques Python, classées pour le déploiement de modèles, l'extraction et le "scraping" de données, le traitement de données et la visualisation.
Cet article présente quelques-unes des bibliothèques Python les plus couramment utilisées dans le domaine de la science des données et de l'apprentissage automatique.
Examinons-les de plus près.
Numpy
La bibliothèque Numpy, abréviation de "Numerical Python", est construite avec du code C hautement optimisé. Les scientifiques des données l'apprécient pour ses capacités de calcul mathématique et scientifique.
Fonctionnalités
- Numpy possède une syntaxe de haut niveau, ce qui simplifie la tâche des programmeurs expérimentés.
- La performance de la bibliothèque est élevée, grâce au code C optimisé qui la compose.
- Elle inclut des outils de calcul numérique, notamment des transformations de Fourier, de l'algèbre linéaire et des générateurs de nombres aléatoires.
- Elle est open source, ce qui favorise les contributions de nombreux développeurs.
Numpy propose d'autres fonctionnalités complètes, telles que la vectorisation des opérations mathématiques, l'indexation et les concepts clés pour la manipulation de tableaux et de matrices.
Pandas
Pandas est une bibliothèque réputée pour l'apprentissage automatique, qui fournit des structures de données de haut niveau et des outils d'analyse efficaces pour les grands ensembles de données. Avec un nombre limité de commandes, cette bibliothèque permet de gérer des opérations complexes avec des données.
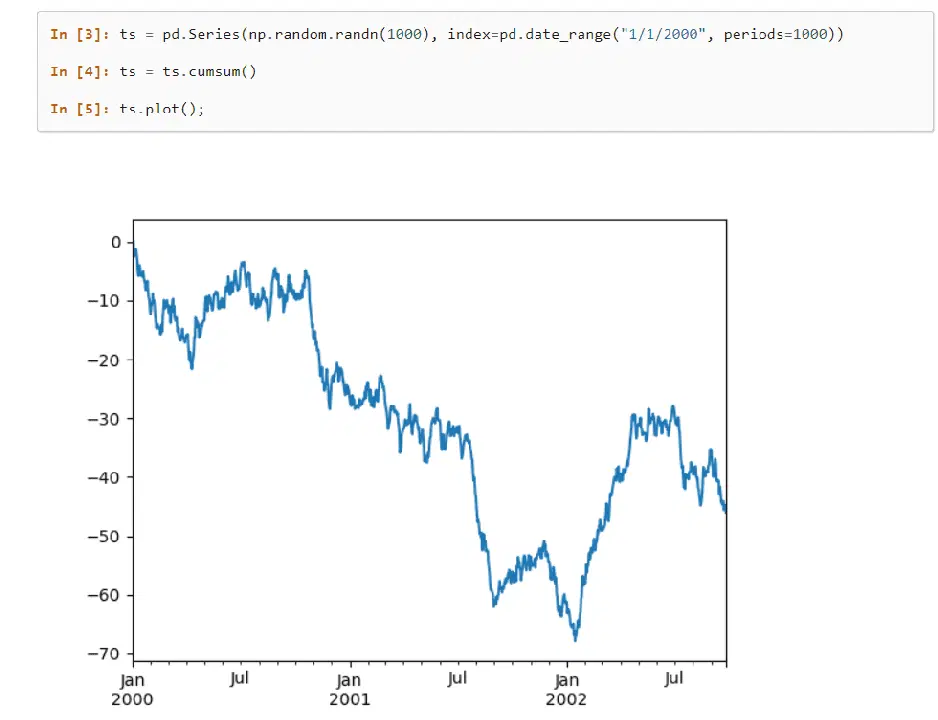
Cette bibliothèque est riche en méthodes intégrées pour regrouper, indexer, récupérer, diviser, restructurer et filtrer les données avant de les organiser en tables unidimensionnelles et multidimensionnelles.
Principales fonctionnalités de la bibliothèque Pandas
- Pandas facilite l'étiquetage des données dans les tables et l'alignement et l'indexation automatiques des données.
- Elle permet de charger et d'enregistrer rapidement des formats de données tels que JSON et CSV.
Elle est très efficace pour son analyse de données performante et sa grande adaptabilité.
Matplotlib
La bibliothèque graphique 2D Matplotlib pour Python peut facilement gérer des données de diverses sources. Les visualisations qu'elle crée sont statiques, animées et interactives, avec une fonction de zoom. Cela la rend efficace pour la visualisation et la création de graphiques. Elle permet également de personnaliser la mise en page et le style visuel.
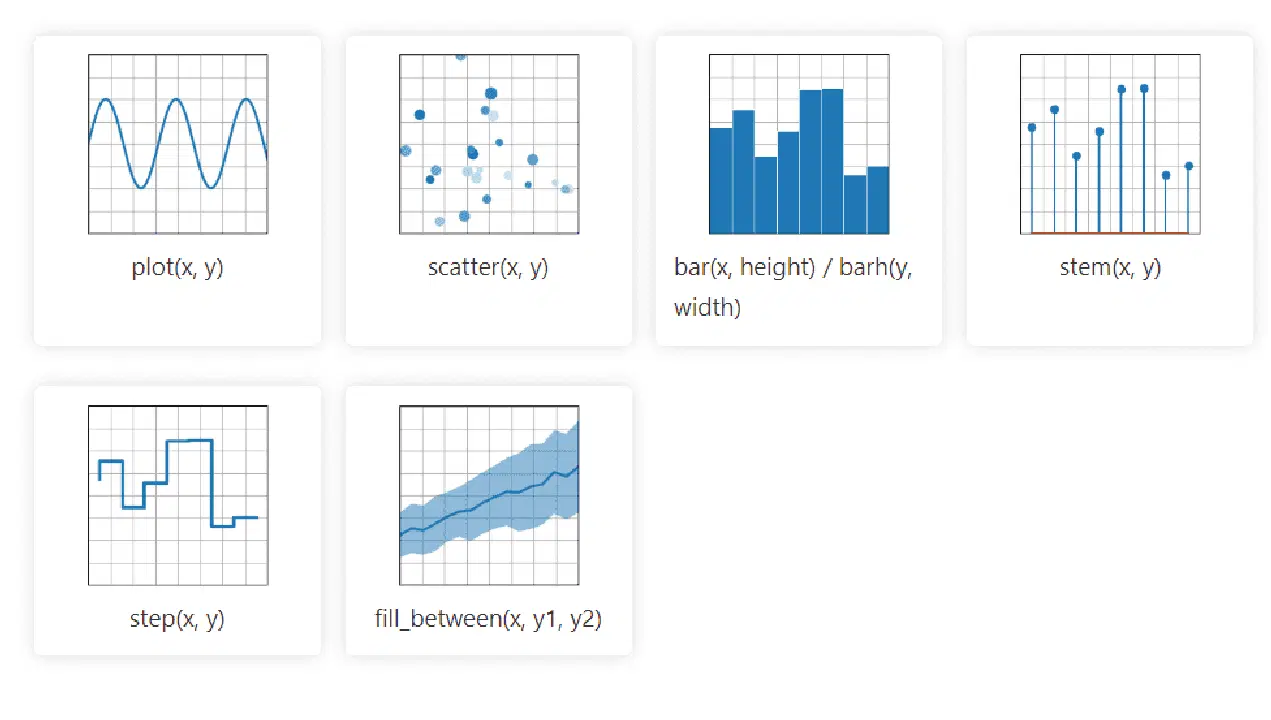
Sa documentation est open source et offre un large éventail d'outils nécessaires à l'implémentation.
Matplotlib importe des classes d'assistance pour manipuler les données de séries temporelles en fonction de l'année, du mois, du jour et de la semaine.
Scikit-learn
Si vous recherchez une bibliothèque pour vous aider à travailler avec des données complexes, Scikit-learn est une solution idéale. Les experts en apprentissage automatique l'utilisent largement. Elle est souvent associée à d'autres bibliothèques telles que NumPy, SciPy et Matplotlib. Scikit-learn propose des algorithmes d'apprentissage supervisé et non supervisé pouvant être utilisés pour des applications de production.
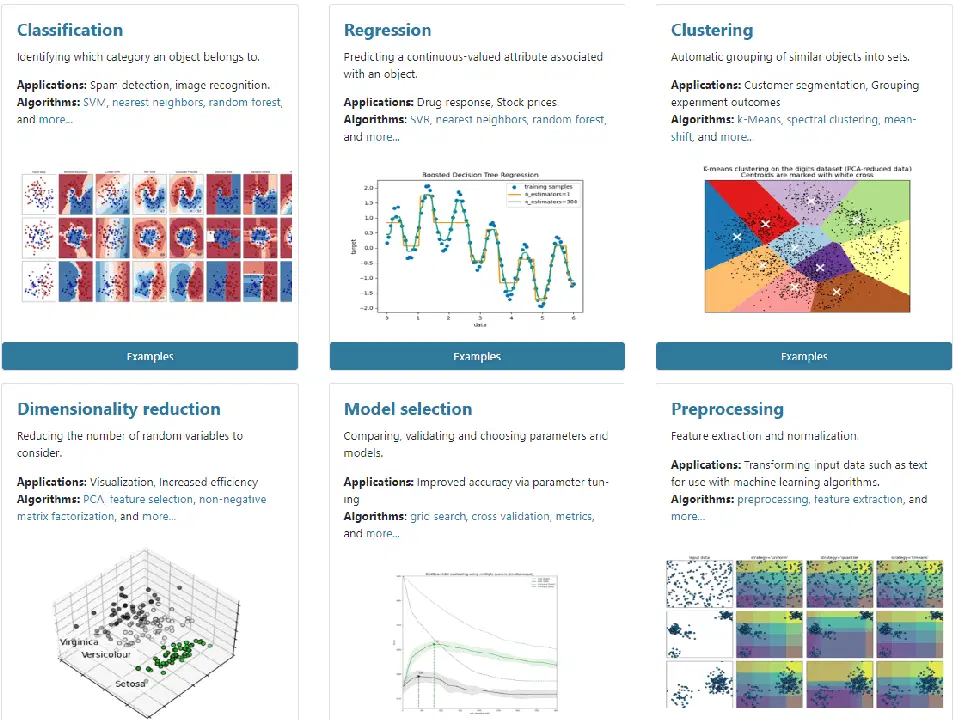
Fonctionnalités de la bibliothèque Scikit-learn Python
- Identification de catégories d'objets, par exemple, avec des algorithmes comme SVM et la forêt aléatoire dans des applications de reconnaissance d'images.
- Prédiction de l'attribut à valeur continue qu'un objet associe à une tâche de régression.
- Extraction de caractéristiques.
- Réduction de dimensionnalité, en réduisant le nombre de variables aléatoires considérées.
- Regroupement d'objets similaires en ensembles.
La bibliothèque Scikit-learn est efficace pour l'extraction de caractéristiques à partir d'ensembles de données texte et image. Il est possible de vérifier l'exactitude des modèles supervisés sur des données inconnues. Ses nombreux algorithmes disponibles facilitent l'exploration de données et autres tâches d'apprentissage automatique.
SciPy
SciPy (Scientific Python) est une bibliothèque d'apprentissage automatique qui propose des modules pour les fonctions mathématiques et des algorithmes. Ses algorithmes résolvent des équations algébriques, l'interpolation, l'optimisation, les statistiques et l'intégration.
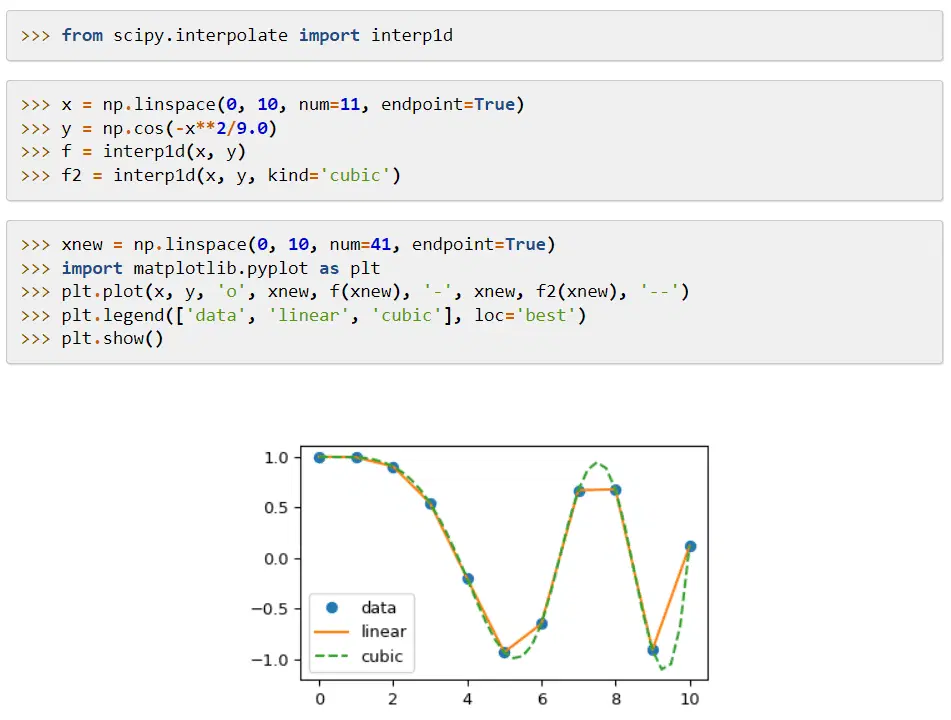
Sa principale caractéristique est son extension à NumPy, qui ajoute des outils pour résoudre les fonctions mathématiques et fournit des structures de données comme des matrices creuses.
SciPy utilise des commandes et des classes de haut niveau pour manipuler et visualiser les données. Ses systèmes de traitement et de prototypage de données en font un outil encore plus performant.
De plus, la syntaxe de haut niveau de SciPy la rend accessible aux programmeurs de tous niveaux d'expérience.
Le seul inconvénient de SciPy est sa focalisation sur les objets numériques et les algorithmes, ne fournissant pas de fonction de traçage.
PyTorch
Cette bibliothèque d'apprentissage automatique diversifiée implémente efficacement des calculs de tenseurs avec accélération GPU, la création de graphiques de calcul dynamiques et des calculs de gradients automatiques. La bibliothèque PyTorch est construite sur la base de la bibliothèque Torch, une bibliothèque open source d'apprentissage automatique développée en C.

Fonctionnalités clés :
- Offre un développement sans friction et une mise à l'échelle fluide grâce à son excellent support sur les principales plates-formes cloud.
- Un écosystème robuste d'outils et de bibliothèques prend en charge le développement de la vision par ordinateur et d'autres domaines comme le traitement du langage naturel (NLP).
- Fournit une transition fluide entre les modes impatient et graphique avec Torch Script et utilise TorchServe pour accélérer sa mise en production.
- Le backend distribué Torch permet une formation distribuée et une optimisation des performances en recherche et en production.
PyTorch peut être utilisé pour développer des applications NLP.
Keras
Keras est une bibliothèque Python open source d'apprentissage automatique utilisée pour expérimenter avec des réseaux de neurones profonds.
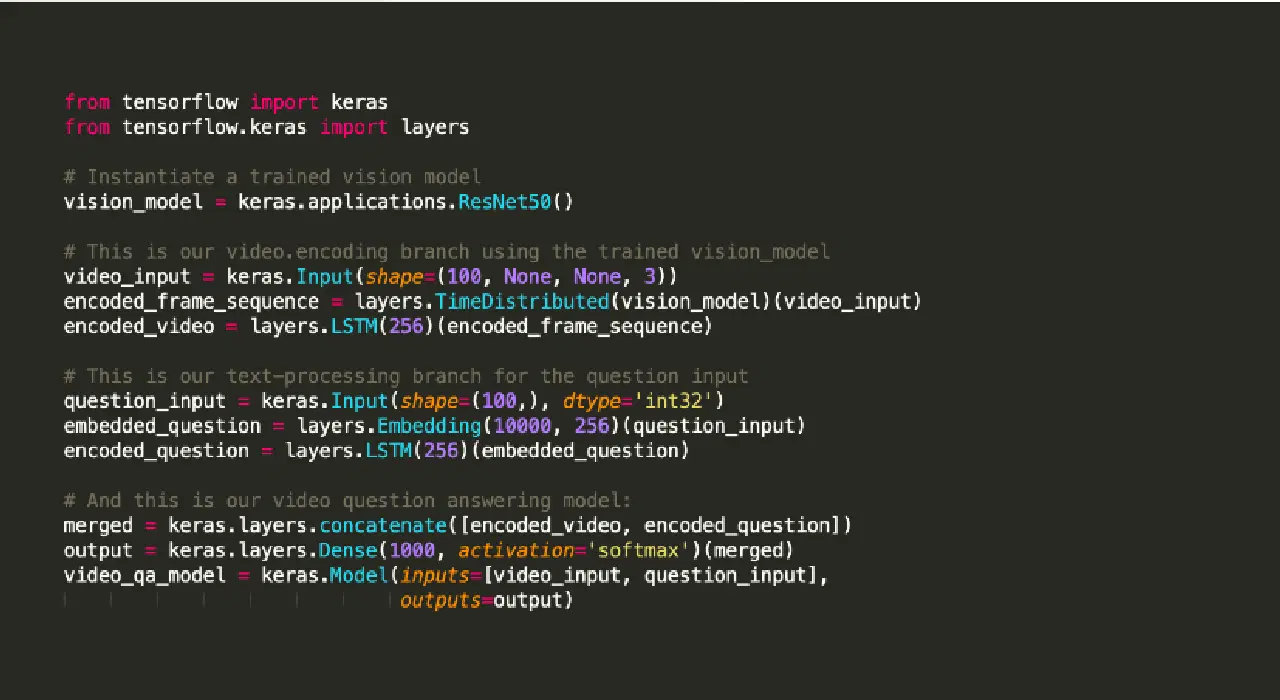
Elle est réputée pour offrir des outils facilitant des tâches telles que la compilation de modèles et la visualisation de graphiques. Elle utilise TensorFlow pour son backend. Alternativement, Theano ou des réseaux de neurones comme CNTK peuvent être utilisés en backend. Cette infrastructure de backend l'aide à créer des graphes de calcul utilisés pour mettre en œuvre les opérations.
Principales caractéristiques de la bibliothèque
- Elle peut fonctionner efficacement à la fois sur l'unité centrale de traitement (CPU) et sur l'unité de traitement graphique (GPU).
- Le débogage est facilité avec Keras car il est basé sur Python.
- Keras est modulaire, ce qui le rend expressif et adaptable.
- Vous pouvez déployer Keras partout en exportant directement ses modules vers JavaScript pour une exécution dans le navigateur.
Les applications de Keras incluent des blocs de construction de réseaux neuronaux tels que les couches et les objectifs, parmi d'autres outils qui facilitent le travail avec des images et des données textuelles.
Seaborn
Seaborn est un autre outil précieux pour la visualisation de données statistiques.
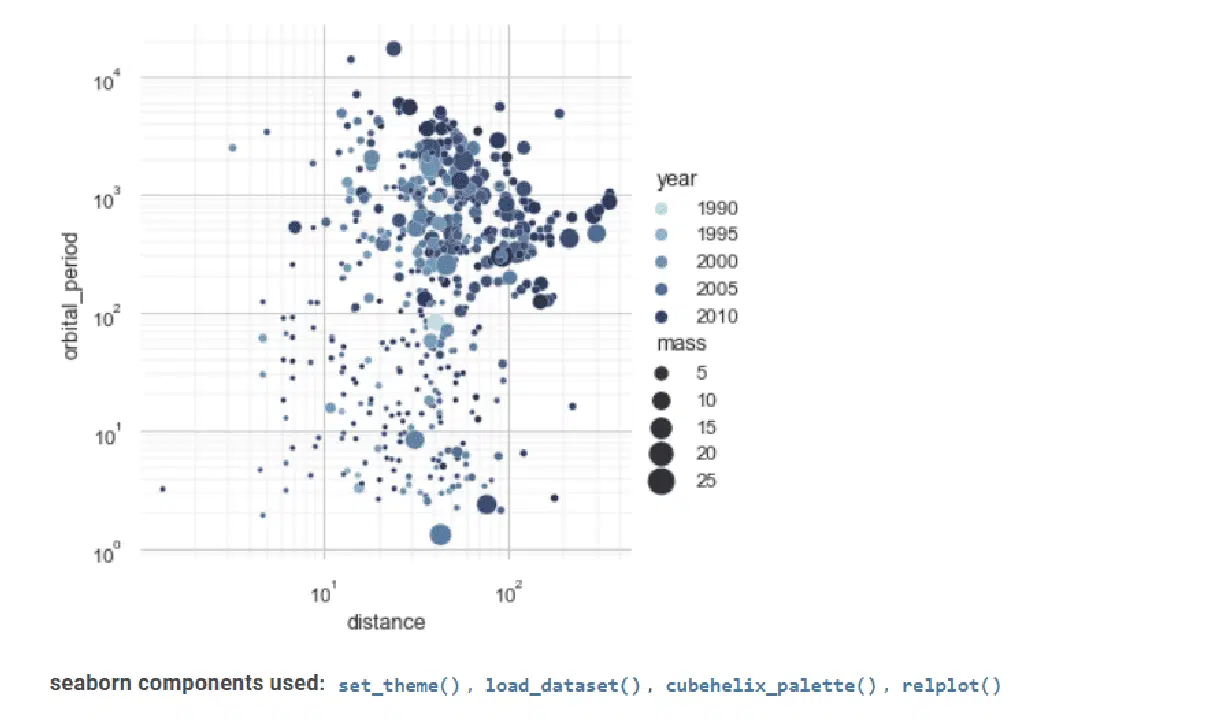
Son interface avancée permet de créer des visualisations statistiques à la fois attrayantes et informatives.
Plotly
Plotly est un outil de visualisation Web 3D basé sur la bibliothèque Plotly JS. Il prend en charge divers types de graphiques, tels que les graphiques linéaires, les nuages de points et les graphiques en boîtes.
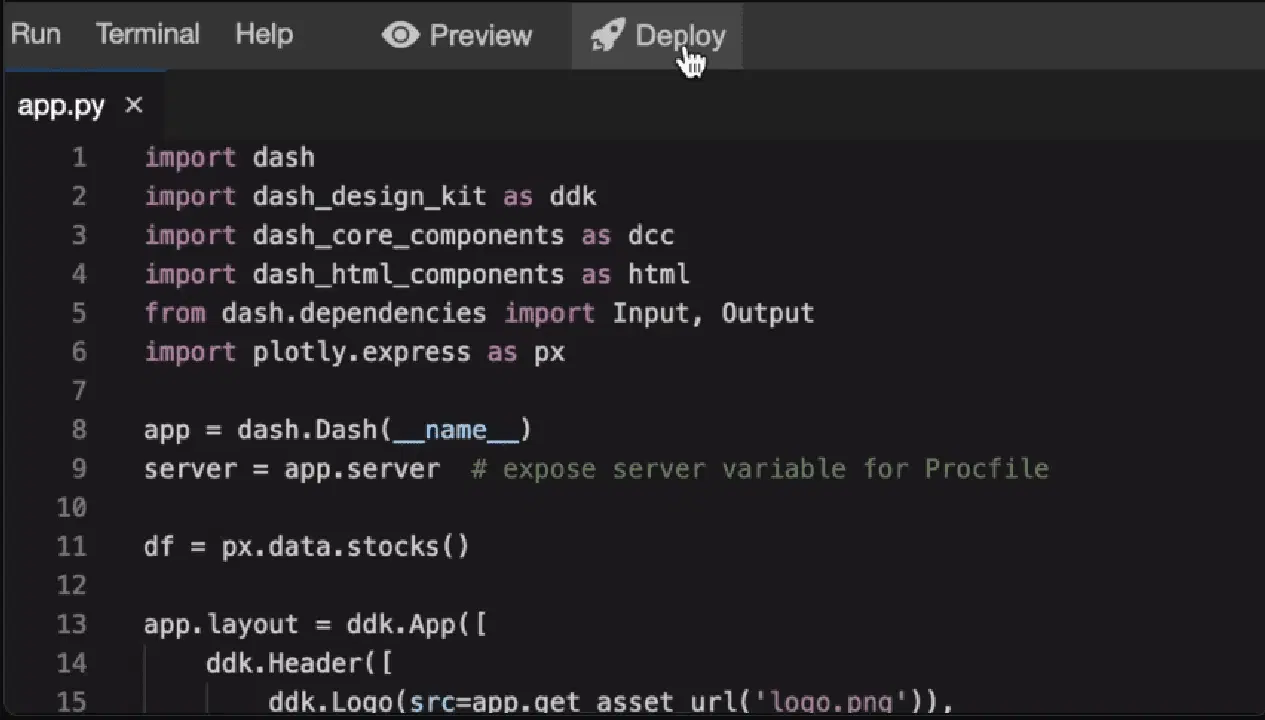
Son application comprend la création de visualisations de données basées sur le Web dans des blocs-notes Jupyter.
Plotly est adapté à la visualisation, car il peut identifier les valeurs aberrantes ou les anomalies dans le graphique grâce à son outil de survol. Vous pouvez également personnaliser les graphiques selon vos préférences.
L'inconvénient de Plotly est que sa documentation est parfois obsolète, ce qui peut rendre son utilisation difficile pour un nouvel utilisateur. Il propose de nombreux outils dont l'utilisateur doit apprendre à maîtriser, ce qui peut être difficile.
Fonctionnalités de la bibliothèque Plotly Python
- Les graphiques 3D qu'elle offre permettent de multiples interactions.
- Sa syntaxe est simplifiée.
- Vous pouvez maintenir la confidentialité de votre code tout en partageant vos visualisations.
SimpleITK
SimpleITK est une bibliothèque d'analyse d'images qui offre une interface à Insight Toolkit (ITK). Elle est basée sur C++ et est open source.
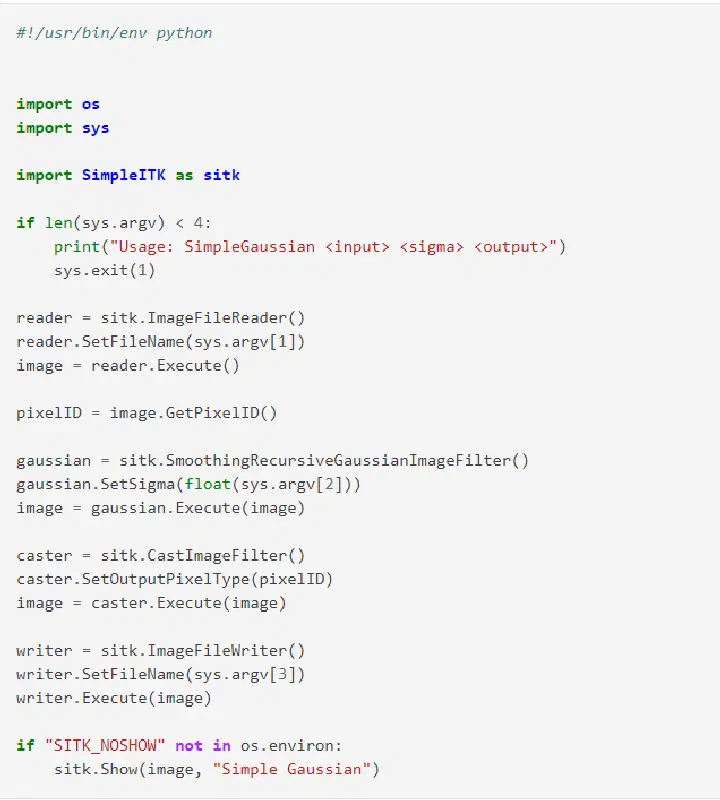
Fonctionnalités de la bibliothèque SimpleITK
- Ses entrées/sorties de fichiers image sont compatibles avec plus de 20 formats, tels que JPG, PNG et DICOM.
- Elle fournit de nombreux filtres pour le flux de travail de segmentation d'image, comme Otsu, les ensembles de niveaux et les bassins versants.
- Elle interprète les images comme des objets spatiaux plutôt qu'un simple tableau de pixels.
Son interface simplifiée est disponible dans divers langages de programmation tels que R, C#, C++, Java et Python.
Statsmodels
Statsmodels estime les modèles statistiques, met en œuvre des tests statistiques et explore des données statistiques à l'aide de classes et de fonctions.
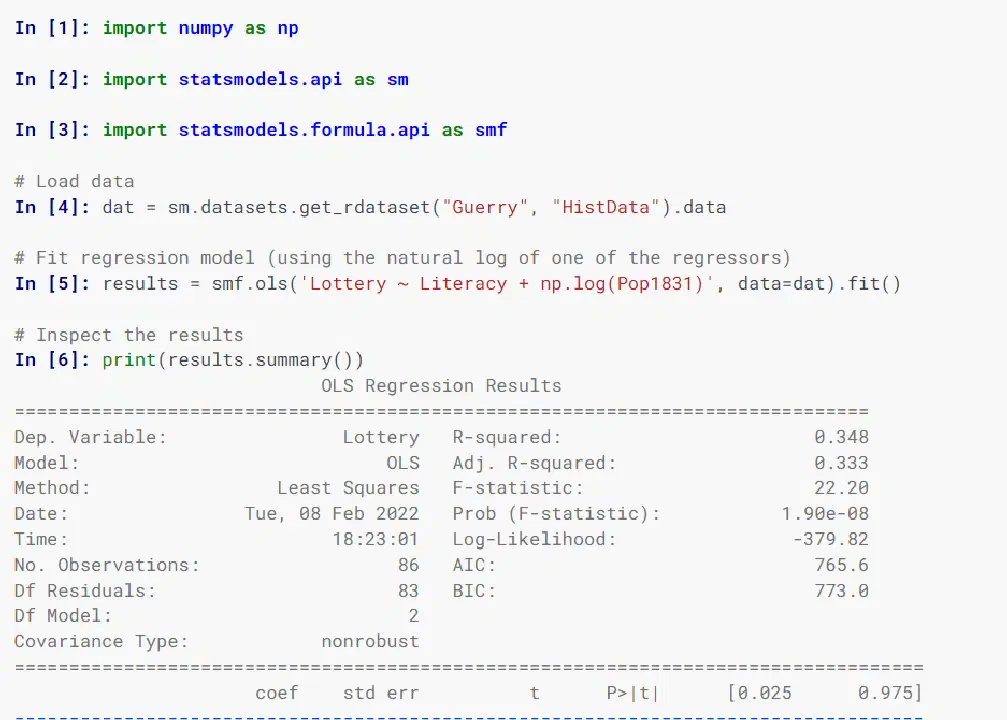
La spécification des modèles utilise des formules de style R, des tableaux NumPy et des trames de données Pandas.
Scrapy
Ce package open source est un outil idéal pour la récupération (scraping) et l'exploration des données de sites Web. Il est asynchrone et donc relativement rapide. L'architecture et les fonctionnalités de Scrapy le rendent efficace.
Son installation diffère selon les systèmes d'exploitation. De plus, il n'est pas utilisable sur les sites Web construits en JS et ne fonctionne qu'avec Python 2.7 ou versions ultérieures.
Les experts en science des données l'utilisent dans l'exploration de données et les tests automatisés.
Fonctionnalités
- Il peut exporter des données aux formats JSON, CSV et XML et les stocker dans plusieurs bases de données.
- Il possède une fonctionnalité intégrée pour collecter et extraire des données à partir de sources HTML/XML.
- Il peut être étendu grâce à une API bien définie.
Pillow
Pillow est une bibliothèque d'imagerie Python qui permet de manipuler et de traiter des images.
Elle complète les fonctionnalités de traitement d'image de l'interpréteur Python, est compatible avec de nombreux formats de fichiers et offre une représentation interne efficace.
Les données stockées dans des formats de fichiers standard sont facilement accessibles avec Pillow.
Conclusion💃
Ceci résume notre exploration de certaines des bibliothèques Python les plus performantes pour les scientifiques des données et les experts en apprentissage automatique.
Comme le montre cet article, Python propose de nombreux packages d'apprentissage automatique et de science des données très utiles. Python propose aussi d'autres bibliothèques qui peuvent être utilisées dans d'autres domaines.
Vous pourriez être intéressé par certains des meilleurs outils pour la science des données.
Bon apprentissage !