GPU NVIDIA série RTX 3000: voici les nouveautés
Le 1er septembre 2020, NVIDIA a marqué un tournant avec l'introduction de sa nouvelle génération de processeurs graphiques (GPU) dédiés aux jeux : la série RTX 3000, fondée sur l'architecture Ampere. Cet article explore les innovations, les solutions logicielles basées sur l'intelligence artificielle et les caractéristiques qui définissent cette génération.
Présentation des GPU RTX Série 3000
NVIDIA a mis en avant ses nouveaux GPU, construits à l'aide d'un processus de fabrication personnalisé de 8 nm. Ils apportent des améliorations significatives en matière de rendu graphique classique (rastérisation) et de lancer de rayons.
Le modèle d'entrée de gamme, la RTX 3070, est proposé à 499 $. Bien que ce prix puisse sembler élevé pour le modèle le plus abordable de cette série, il devient très intéressant une fois qu'on découvre qu'elle surpasse la RTX 2080 Ti, une carte haut de gamme qui se vendait régulièrement à plus de 1400 $. Suite à l'annonce de NVIDIA, le prix de la 2080 Ti sur le marché de l'occasion a chuté, de nombreux vendeurs se débarrassant de leurs cartes sur eBay pour moins de 600 $.
Au moment de l'annonce, il n'y avait pas de données de référence solides, il est donc difficile de déterminer si la carte est réellement "meilleure" qu'une 2080 Ti ou si NVIDIA a un peu forcé le trait marketing. Les démonstrations utilisaient une résolution 4K et le lancer de rayons, ce qui pourrait exagérer l'écart de performance par rapport aux jeux basés uniquement sur la rastérisation. En effet, la série 3000, basée sur Ampere, est deux fois plus performante en lancer de rayons que Turing. Cependant, avec le lancer de rayons devenant de moins en moins gourmand en ressources et étant pris en charge par les consoles de dernière génération, il s'agit d'un argument de vente important. La possibilité d'obtenir des performances comparables au produit phare de la génération précédente pour un tiers du prix est un atout majeur.
Il n'est pas certain que ces prix se maintiennent. Les cartes de fabricants tiers ajoutent régulièrement au moins 50 $ au prix, et compte tenu de la forte demande, il ne serait pas surprenant de voir la 3070 se vendre à 600 $ en octobre 2020.
Juste au-dessus, on trouve la RTX 3080 à 699 $, annoncée comme deux fois plus rapide que la RTX 2080 et environ 25 à 30 % plus rapide que la 3070.
Enfin, le nouveau produit phare est la RTX 3090, une carte particulièrement imposante. NVIDIA en est consciente et la surnomme "BFGPU", pour "Big Ferocious GPU".

NVIDIA n'a pas publié de mesures de performances précises, mais a montré la carte faisant tourner des jeux en 8K à 60 FPS, ce qui est très impressionnant. Bien sûr, NVIDIA utilise très probablement la technologie DLSS pour atteindre cet objectif, mais le fait est que le jeu en 8K est désormais possible.
Il est certain que des modèles comme la 3060 et d'autres variantes plus abordables finiront par sortir, mais généralement plus tard.
Pour gérer la chaleur, NVIDIA a repensé le système de refroidissement. La 3080 a une consommation de 320 watts, ce qui est assez élevé. NVIDIA a donc opté pour une conception à double ventilateur, mais au lieu de les placer tous les deux sur la partie inférieure, NVIDIA a placé un ventilateur à l'extrémité supérieure, là où se trouve généralement la plaque arrière. Ce ventilateur dirige l'air vers le haut, vers le refroidisseur du processeur et la partie supérieure du boîtier.
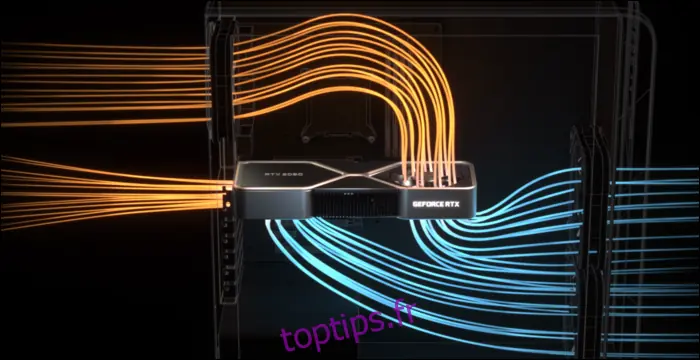
Étant donné l'impact que peut avoir un mauvais flux d'air sur les performances, cette conception est très logique. Cependant, le circuit imprimé est plus petit à cause de cela, ce qui influencera probablement le prix de vente des cartes de fabricants tiers.
DLSS : un avantage logiciel
Le lancer de rayons n'est pas le seul atout de ces nouvelles cartes. En réalité, il s'agit d'un compromis. Les séries RTX 2000 et 3000 ne sont pas intrinsèquement beaucoup plus performantes pour le lancer de rayons que les générations précédentes. Le lancer de rayons d'une scène complète dans un logiciel 3D comme Blender prend généralement plusieurs secondes, voire des minutes par image. Il est donc impossible de le forcer en moins de 10 millisecondes.
Bien qu'il existe du matériel spécialisé, les cœurs RT, dédiés au calcul des rayons, NVIDIA a choisi une approche différente. NVIDIA a amélioré les algorithmes de débruitage, qui permettent aux GPU de produire une image très rapidement, mais d'une qualité médiocre, puis de la transformer - grâce à la magie de l'IA - en quelque chose de visuellement acceptable. Cette technique, combinée aux méthodes traditionnelles de rastérisation, permet de créer des effets de lancer de rayons de manière fluide.

Pour accélérer ce processus, NVIDIA a ajouté des cœurs dédiés au traitement de l'IA, appelés cœurs Tensor. Ils effectuent rapidement tous les calculs nécessaires pour exécuter des modèles d'apprentissage automatique. Ils sont une véritable révolution dans le domaine de l'IA pour les serveurs cloud, où l'IA est largement utilisée.
Outre le débruitage, l'utilisation principale des cœurs Tensor pour les joueurs est le DLSS, ou "Deep Learning Super Sampling". Il prend une image de mauvaise qualité et l'améliore pour atteindre une qualité proche de la résolution native. Cela signifie que vous pouvez jouer avec des fréquences d'images dignes d'un 1080p, tout en profitant d'une qualité visuelle de niveau 4K.
Cela améliore également un peu les performances du lancer de rayons. Les tests de PCMag montrent une RTX 2080 Super faisant tourner Control en qualité ultra, avec tous les paramètres de lancer de rayons au maximum. En 4K, elle a du mal avec seulement 19 FPS, mais avec le DLSS activé, elle atteint 54 FPS. DLSS est une amélioration de performance gratuite pour NVIDIA, rendue possible grâce aux cœurs Tensor présents sur les architectures Turing et Ampere. Tout jeu compatible avec le DLSS et limité par le GPU peut constater des améliorations significatives simplement grâce au logiciel.
Le DLSS n'est pas nouveau et a été présenté comme une fonctionnalité lors du lancement de la série RTX 2000 il y a deux ans. À l'époque, très peu de jeux le prenaient en charge car NVIDIA devait entraîner et optimiser un modèle d'apprentissage automatique pour chaque jeu individuel.
Cependant, NVIDIA a entièrement réécrit cette technologie en la nommant DLSS 2.0. Il s'agit d'une API à usage général, ce qui signifie que n'importe quel développeur peut l'implémenter, et la plupart des jeux importants l'adoptent déjà. Au lieu de travailler sur une image, elle utilise des données vectorielles de mouvement de l'image précédente, de la même manière que le TAA. Le résultat est beaucoup plus net que le DLSS 1.0 et, dans certains cas, il est même meilleur et plus net que la résolution native. Il n'y a donc pas beaucoup de raisons de ne pas l'activer.
Il y a cependant un inconvénient : lorsque l'on change complètement de scène, comme dans les cinématiques, le DLSS 2.0 doit afficher la toute première image avec une qualité de 50 % en attendant les données vectorielles de mouvement. Cela peut entraîner une légère baisse de qualité pendant quelques millisecondes. Mais 99 % de ce que vous regarderez sera rendu correctement, et la plupart des gens ne le remarquent pas dans la pratique.
Architecture Ampere : conçue pour l'IA
Ampere est rapide, particulièrement pour les calculs d'IA. Le cœur RT est 1,7 fois plus rapide que Turing, et le nouveau cœur Tensor est 2,7 fois plus rapide. La combinaison des deux offre un véritable bond en avant en termes de performances de lancer de rayons.

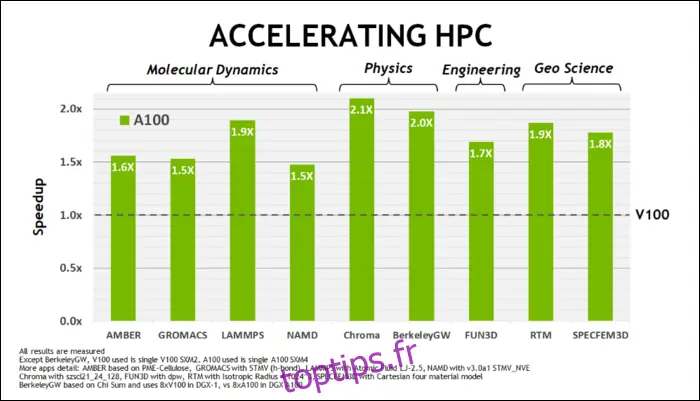
Plus tôt en mai, NVIDIA a présenté le GPU Ampere A100, un GPU pour centres de données conçu pour l'IA. Ils ont donné beaucoup de détails sur ce qui rend Ampere si rapide. Pour les charges de travail des centres de données et le calcul haute performance, Ampere est environ 1,7 fois plus rapide que Turing. Pour l'entraînement de l'IA, il est jusqu'à 6 fois plus rapide.
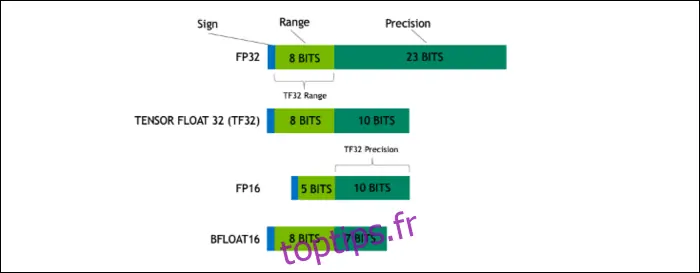
Avec Ampere, NVIDIA utilise un nouveau format de nombre conçu pour remplacer le standard industriel "Floating-Point 32" ou FP32 dans certaines tâches. Sous le capot, chaque nombre que votre ordinateur traite occupe un nombre prédéfini de bits en mémoire, que ce soit 8, 16, 32, 64 ou même plus. Les nombres plus grands sont plus difficiles à traiter, donc si vous pouvez utiliser une taille plus petite, vous en aurez moins à gérer.
Le FP32 stocke un nombre décimal en utilisant 32 bits, dont 8 pour la plage du nombre (sa taille) et 23 pour la précision. NVIDIA affirme que ces 23 bits de précision ne sont pas toujours nécessaires pour les calculs d'IA, et qu'il est possible d'obtenir des résultats similaires et des performances bien meilleures avec seulement 10. Réduire la taille à seulement 19 bits au lieu de 32 représente une différence significative dans de nombreux calculs.
Ce nouveau format s'appelle Tensor Float 32. Les cœurs Tensor de l'A100 sont optimisés pour gérer ce format de taille inhabituelle. C'est, en plus de la réduction des matrices et de l'augmentation du nombre de cœurs, ce qui permet d'obtenir une accélération massive de 6x dans l'entraînement de l'IA.
En plus du nouveau format de nombre, Ampere voit des améliorations de performance significatives dans certains calculs spécifiques, comme FP32 et FP64. Cela ne se traduit pas directement par plus de FPS pour l'utilisateur lambda, mais c'est un facteur qui contribue à la vitesse des opérations Tensor.

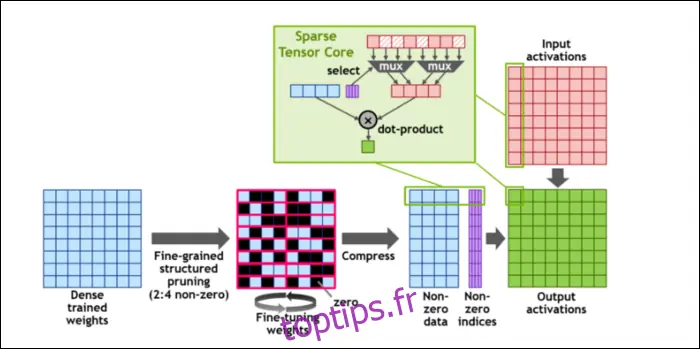
Pour accélérer davantage les calculs, ils ont introduit le concept de « clarté structurée à grain fin », un terme complexe pour une idée assez simple. Les réseaux neuronaux fonctionnent avec de longues listes de nombres, appelés poids, qui affectent le résultat final. Plus il y a de nombres à traiter, plus ce sera lent.
Cependant, tous ces nombres ne sont pas réellement utiles. Certains ne sont que des zéros et peuvent être ignorés, ce qui accélère considérablement les calculs. La rareté compresse les nombres, ce qui demande moins d'effort pour faire les calculs. Le nouveau "Sparse Tensor Core" est conçu pour fonctionner sur des données compressées.
Malgré ces changements, NVIDIA affirme que cela ne devrait pas affecter la précision des modèles entraînés.
Pour les calculs Sparse INT8, l'un des plus petits formats de nombres, les performances maximales d'un seul GPU A100 dépassent 1,25 PetaFLOP, un chiffre incroyablement élevé. Bien sûr, cela n'est vrai que lors du calcul d'un type de nombre spécifique, mais cela reste impressionnant.