Expliqué en 5 minutes ou moins
Les données constituent le fondement de toute activité commerciale. Elles sont la clé du succès, indispensables pour collecter des informations, prendre des décisions éclairées et améliorer les processus opérationnels.
Une entreprise dépend fortement de ses données et de ses applications pour assurer son fonctionnement quotidien. Mais qu'arrive-t-il lorsqu'une de leurs bases de données ou systèmes critiques subit une défaillance ?
L'intégralité des informations et des données essentielles de l'entreprise pourrait se retrouver compromise.
Heureusement, il existe des solutions pour prévenir de telles situations. L'une des approches les plus efficaces pour protéger les données d'entreprise est la réplication de base de données. C'est une mesure que chaque entreprise, quelle que soit sa taille, doit adopter pour rester compétitive.
Cet article explorera la notion de réplication de données, son fonctionnement ainsi que d'autres aspects importants.
Commençons sans plus tarder !
Qu'est-ce que la réplication de base de données ?
La réplication de base de données fait référence au processus de transfert de données d'une base de données source vers une ou plusieurs bases de données cibles. Cela implique généralement la copie ou la diffusion de données d'une base de données à une autre afin que tous les utilisateurs puissent accéder à des informations synchronisées, indépendamment du système utilisé pour la consultation.
Si des données sont modifiées, un outil de réplication de données s'assure que ces modifications sont également reportées dans la base de données cible. Ainsi, un réseau de stockage de données distribué, offrant une meilleure disponibilité sur plusieurs sites, est mis en place, permettant un accès rapide aux données essentielles et pertinentes pour tous les acteurs.
En adoptant une solution de réplication de données, vous constaterez probablement une amélioration de la cohérence des données sur chaque nœud, une réduction de la redondance des données, une plus grande fiabilité des données et, potentiellement, une augmentation des performances.
La réplication de base de données peut s'effectuer en temps réel, lorsque les données sont créées, modifiées et supprimées sur la base de données source, ou dans le cadre d'un traitement par lots.
Comment fonctionne la réplication de données ?
La réplication de base de données peut être exécutée ponctuellement ou de manière continue. Elle englobe toutes les sources de données d'une organisation et un système de gestion de base de données distribuée (SGBDR) est utilisé pour transférer ou distribuer les données vers toutes les sources.
Toute modification, ajout ou suppression effectuée dans la base de données source est automatiquement synchronisée avec les autres bases de données cibles, si ces changements sont nécessaires. Conformément au paradigme logiciel classique éditeur-abonné, un ou plusieurs "éditeurs" et "abonnés" sont impliqués dans le processus de réplication des données.
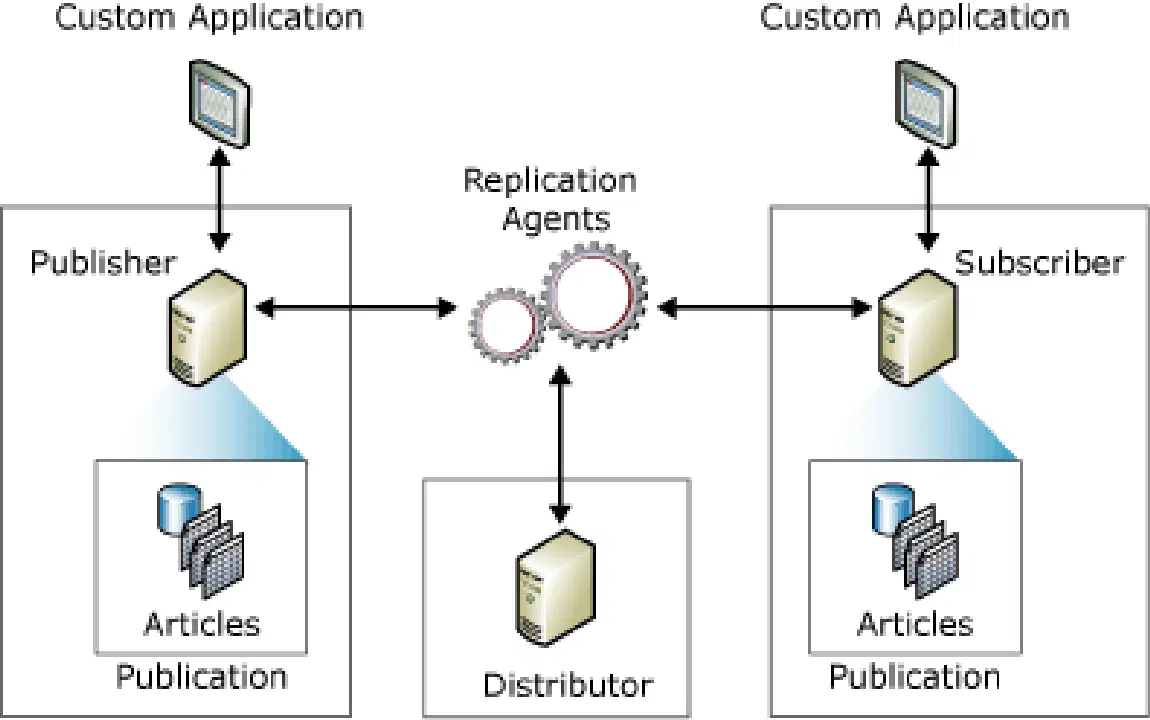 Crédit image : Microsoft
Crédit image : Microsoft
Un "éditeur" est un système ou la base de données source sur laquelle des modifications sont apportées, et un "abonné" est un système sur lequel les modifications sont répliquées.
Toutes les modifications effectuées sur un système "éditeur" sont ensuite reproduites sur les bases de données "abonnées". Les utilisateurs peuvent également apporter des modifications aux bases de données des abonnés, qui sont ensuite répercutées dans la base de données de l'éditeur. Cela distribue les modifications à tous les autres abonnés du réseau si le système est bidirectionnel.
De plus, la majorité des abonnés sont liés de manière permanente à l'éditeur, permettant des modifications ou mises à jour automatiques sans intervention humaine. Ces mises à jour peuvent s'effectuer par lots à intervalles réguliers ou être déclenchées et appliquées en temps réel.
Types de réplication de base de données
Voici quelques types de réplication de base de données :
#1. Réplication de table complète
La réplication de table complète consiste à créer une copie intégrale de la base de données source sur le stockage cible. Elle transfère les lignes de l'éditeur vers l'abonné, incluant les lignes nouvelles, modifiées et existantes.
Cependant, cette méthode de réplication implique des coûts de maintenance élevés en raison des besoins en puissance de calcul et en bande passante réseau pour la copie complète. Elle sollicite fortement le réseau et peut engendrer des retards de réplication, particulièrement lorsque le volume de données est important.
#2. Réplication d'instantané
Dans ce type de réplication, un instantané de la base de données source est utilisé pour reproduire les données dans la base de données cible. Elle ne prend pas en considération les modifications de données, telles que les données nouvelles, mises à jour ou supprimées; elle crée simplement une copie de ce qu'elle collecte au moment de l'instantané.
Cette technique de réplication est idéale lorsque les changements de données sont peu fréquents. Elle est beaucoup plus rapide que la réplication de table complète, mais elle ne conserve pas la trace des données définitivement supprimées.

#3. Réplication de fusion
La réplication de fusion est un processus qui transfère et distribue les objets et données d'une base de données à une autre avec une synchronisation de base de données. Elle est complexe car elle permet aux abonnés et aux éditeurs de modifier la base de données, ce qui peut générer des conflits de données liés aux différentes versions.
Les agents de fusion déployés sur les serveurs synchronisent toutes les modifications et appliquent un processus prédéfini de résolution des conflits afin de gérer tout conflit de données.
#4. Réplication incrémentielle basée sur des clés
La réplication incrémentielle basée sur des clés examine les clés ou les index d'une base de données pour identifier les modifications, telles que les suppressions, créations et mises à jour. Le mécanisme de réplication copie ensuite uniquement les clés de réplication nécessaires dans la base de données répliquée afin de refléter les modifications depuis la dernière mise à jour. Ces clés sont généralement un horodatage, une date ou un nombre entier.
Ce processus est plus rapide, car seules les modifications indiquées sont reproduites dans la base de données répliquée. Malheureusement, cette méthode ne permet pas la gestion des suppressions définitives, car la valeur clé est supprimée en effaçant l'enregistrement de la base de données principale.
#5. Réplication incrémentielle basée sur le journal
Ce type de réplication de base de données duplique les données en se basant sur le fichier journal binaire de la base de données. L'analyse du fichier journal binaire permet d'obtenir des informations sur les modifications apportées à la base de données principale, telles que les mises à jour, insertions ou suppressions. Ensuite, les mêmes changements ou mises à jour sont appliqués à la base de données de destination.
C'est l'une des méthodes de réplication de données les plus utilisées, car elle est efficace, surtout pour les bases de données statiques. De plus, la plupart des fournisseurs de bases de données la prennent en charge, notamment Oracle, MongoDB, MySQL et PostgreSQL.
#6. Réplication transactionnelle
Lorsqu'un nouvel événement se produit dans les données source, la réplication transactionnelle déplace toutes les données existantes de la base de données source vers l'emplacement cible. Ensuite, elle exécute la même transaction dans les répliques.
Bien que cette méthode de réplication soit efficace, les modèles sont principalement utilisés pour les activités de lecture et peuvent ne pas autoriser les opérations de création, suppression ou mise à jour.
Pourquoi la réplication de base de données est-elle importante ?

La réplication de base de données est essentielle pour les raisons suivantes :
Fiabilité et disponibilité des données
La réplication des données favorise la disponibilité des informations. Elle joue un rôle crucial en cas de défaillance d'un serveur, en fournissant des copies de sauvegarde des bases de données. Cela vous permet de gagner du temps, car les données sont disponibles à d'autres emplacements. De plus, elle améliore la fiabilité des données en conservant les dernières informations pertinentes de manière sécurisée sur plusieurs serveurs.
Reprise après sinistre
La réplication de base de données s'avère utile lors d'une panne de serveur. C'est une excellente technique de gestion des sinistres et de reprise, car elle réplique et stocke les données ainsi que les modifications récentes sur d'autres emplacements de serveurs, au lieu de se reposer sur un seul serveur.
Performances du serveur
L'accès aux données est bien plus rapide lorsque les informations sont traitées et exploitées sur plusieurs serveurs. De plus, les administrateurs peuvent libérer des cycles de traitement sur le serveur d'origine pour des opérations d'écriture plus gourmandes en ressources en redirigeant toutes les opérations de lecture de données vers une réplique.
Meilleures performances réseau
La conservation de plusieurs copies des mêmes données à divers endroits peut réduire la latence d'accès aux données, car vous pouvez récupérer les informations pertinentes à partir du lieu où la transaction est exécutée.
Par exemple, les utilisateurs des pays européens peuvent rencontrer des problèmes de latence lorsqu'ils accèdent aux données des centres de données australiens. Ainsi, placer une réplique de ces données à proximité de l'utilisateur peut améliorer les temps d'accès tout en équilibrant la charge du réseau.
Amélioration des performances du système de test

La réplication de base de données rationalise la distribution et la synchronisation des données pour les systèmes de test qui nécessitent un accès rapide pour une prise de décision plus rapide.
Sauvegarde de base de données vs réplication de base de données
La sauvegarde de la base de données et la réplication de la base de données diffèrent de plusieurs façons. Voici quelques exemples :
- Les sauvegardes de base de données nécessitent une reconstruction et une restauration avant de pouvoir être utilisées. Contrairement aux sauvegardes, la réplication de données peut être utilisée immédiatement sans reconstruction.
- Les sauvegardes de base de données comprennent des fichiers ou des dossiers, des fichiers de données de base de données et des fichiers d'application, selon les protocoles de sauvegarde-restauration de l'organisation. En revanche, la réplication de base de données est souvent utilisée pour dupliquer des volumes entiers ou des systèmes de fichiers, bases de données et applications.
- La sauvegarde et la réplication sont toutes deux des mesures de protection des données. La première vise à réduire les objectifs de point de récupération (RPO) et à éviter la perte de données, tandis que la seconde est conçue pour réduire les objectifs de temps de récupération (RTO), assurer la continuité des activités et minimiser les temps d'arrêt.
- La sauvegarde de base de données est une méthode peu coûteuse pour éviter la perte totale de données. Elle est essentielle pour la conformité, mais ne garantit pas la continuité opérationnelle. Au contraire, la réplication garantit la disponibilité constante des applications et processus métier, même après une panne de courant.
- La sauvegarde de base de données se concentre sur la conformité et la récupération granulaire, comme le stockage à long terme des enregistrements de l'entreprise. La réplication et la récupération de bases de données, quant à elles, se concentrent sur la reprise après sinistre, permettant une restauration rapide et facile des opérations après une panne ou une corruption.
- La sauvegarde de base de données est couramment utilisée en milieu de travail pour diverses raisons, allant des serveurs de production aux ordinateurs de bureau. La réplication de base de données, à l'inverse, est souvent utilisée pour les applications critiques qui doivent être constamment disponibles.
Techniques de réplication de bases de données

Les organisations peuvent répliquer des données en adoptant une technique spécifique pour transférer les informations. Ces stratégies diffèrent des types de réplication mentionnés précédemment.
#1. Réplication complète de la base de données
La réplication complète de la base de données consiste à reproduire l'intégralité d'une base de données pour une utilisation sur différents hôtes. Cela assure le plus haut niveau de redondance et de disponibilité des données. Pour les entreprises mondiales, cela permet aux utilisateurs situés en Asie d'accéder aux mêmes données que leurs collègues en Amérique du Nord à la même vitesse. Si le serveur asiatique tombe en panne, les utilisateurs peuvent utiliser leurs serveurs européens ou nord-américains comme sauvegarde.
Cependant, l'inconvénient de cette technique est la lenteur du processus de mise à jour. Il est également difficile de maintenir la cohérence sur chaque emplacement de fichier, ce qui est crucial si les données sont en constante évolution.
#2. Réplication partielle de la base de données
La réplication partielle de base de données consiste à séparer les données d'une base de données en segments et à les enregistrer à divers emplacements, en fonction de la pertinence de chaque site.
Les experts en sinistres, les conseillers financiers et les professionnels de la vente profitent d'une réplication partielle. Ces employés peuvent transporter les bases de données partielles sur d'autres appareils ou ordinateurs portables et les synchroniser régulièrement avec un serveur central.
Pour les analystes, il peut être plus économique de conserver les données européennes en Europe, les données australiennes en Australie, etc. Cela permet de garder les données à proximité des utilisateurs tout en conservant un ensemble de données complet au siège pour une analyse de haut niveau.
Inconvénients de la réplication de base de données

Bien que la réplication de données puisse apporter une valeur significative à votre travail et à votre entreprise, elle présente également certains inconvénients :
Coûts plus élevés
Lorsque les données sont répliquées et stockées à plusieurs endroits, cela nécessite plus d'espace de stockage et de ressources informatiques. Cette augmentation de la demande en ressources matérielles et informatiques peut engendrer des coûts plus élevés, notamment pour l'achat et la maintenance de périphériques de stockage, serveurs et infrastructures réseau supplémentaires.
Contraintes de temps
La réplication de données est un processus complexe qui implique la copie de données d'un emplacement vers plusieurs autres emplacements et le maintien de la cohérence entre toutes les copies. Ce processus peut être chronophage, surtout pour les organisations qui ont de grands volumes de données à répliquer.
Bande passante
À mesure que le volume de données répliquées augmente, les besoins en bande passante augmentent également, ce qui peut peser sur les ressources du réseau.
Données incohérentes
Lors de la réplication de données dans un environnement distribué, il existe un risque de désynchronisation des données si les mises à jour ne sont pas effectuées de manière cohérente sur toutes les répliques. Cela peut conduire à des données incohérentes et nécessiter des efforts supplémentaires pour résoudre ces problèmes.
Cas d'utilisation de la réplication de base de données

Il existe de nombreux cas où la réplication de données peut être bénéfique, tels que :
L'équilibrage de charge
En répliquant les données sur plusieurs serveurs, la charge est répartie sur ces serveurs afin d'améliorer les performances. L'équilibrage de charge garantit qu'aucun serveur n'est submergé par un trop grand nombre de requêtes et que le système reste disponible et réactif, même en cas de forte fréquentation.
Entreposage de données
Un entrepôt de données est un référentiel centralisé pour stocker de grandes quantités de données provenant de sources diverses. La réplication des données de ces sources vers l'entrepôt de données permet aux organisations d'analyser et de générer des rapports sur leurs données de manière centralisée et organisée.
Déploiement interrégional
La réplication des données dans plusieurs régions permet aux organisations d'améliorer l'accessibilité et la redondance des données. En cas de panne dans une région, les données restent accessibles depuis une autre région. De plus, la présence de données dans plusieurs régions peut améliorer la vitesse d'accès pour les utilisateurs situés dans différentes parties du monde.
Sauvegarde et archivage
La réplication des données vers un stockage secondaire permet aux organisations de conserver une copie à long terme de leurs informations. Cela leur permet d'accéder facilement aux données et garantit qu'elles ne seront pas perdues, même en cas de défaillance du stockage principal.
Synchronisation des données
La réplication des données entre plusieurs systèmes garantit la synchronisation, la cohérence et l'actualisation des informations sur tous les systèmes. Ceci est crucial pour les applications telles que le commerce électronique, où les mêmes données doivent être accessibles à partir de plusieurs systèmes.
Collaboration multi-sites
La réplication des données entre plusieurs sites permet aux organisations de partager des données en temps réel, favorisant la collaboration et une productivité accrue. Cela est particulièrement utile pour les organisations dont les équipes sont réparties sur plusieurs sites ou pour les entreprises qui doivent partager des données avec des partenaires ou des clients.
Ressources d'apprentissage
Voici quelques ressources d'apprentissage pour vous aider à approfondir vos connaissances sur le sujet :
#1. Réplication de base de données par Bettina Kemme
Ce livre vous aidera à comprendre les divers mécanismes de contrôle de la concurrence et des répliques, ainsi que les problèmes associés.
#2. Réplication de base de données : un guide complet :
Ce livre vous préparera à relever les défis de la réplication de bases de données en expliquant et en répondant à vos interrogations.
Conclusion
La réplication des données est une stratégie sous-estimée dans le monde d'aujourd'hui, qui est de plus en plus axé sur les données. Si vous êtes chef d'entreprise, vous serez surpris par les avantages qu'elle peut offrir.
Cependant, à mesure que le nombre de sources et de destinations augmente, les entreprises doivent être prêtes à gérer les défis qui en découlent. C'est pourquoi une stratégie de réplication de données fiable et évolutive peut s'avérer très utile.
Vous pouvez également explorer certains logiciels de surveillance de base de données utiles pour analyser les performances.