Explication des algorithmes de traitement du langage naturel (NLP)
La complexité des langues humaines pose un défi majeur pour les machines. Elles doivent décoder des acronymes, des significations multiples, des subtilités grammaticales, le contexte, l'argot et une multitude d'autres éléments.
Cependant, de nombreux processus et opérations d'entreprise s'appuient sur les machines, nécessitant une interaction constante entre l'humain et la machine.
Les chercheurs ont donc cherché des solutions technologiques capables d'aider les machines à déchiffrer les langues humaines et à faciliter leur apprentissage.
C'est ainsi que sont apparus les algorithmes de traitement automatique du langage naturel, ou TALN. Ces programmes informatiques sont conçus pour interpréter les différentes langues humaines, qu'elles soient écrites ou parlées.
Le TALN utilise une variété d'algorithmes pour traiter les langues. L'arrivée de ces algorithmes a propulsé cette technologie au rang d'élément essentiel de l'intelligence artificielle (IA) pour structurer les données non organisées.
Dans cet article, nous allons explorer le TALN et certains de ses algorithmes les plus pertinents.
C'est parti !
Qu'est-ce que le TALN ?
Le Traitement Automatique du Langage Naturel (TALN) est un domaine interdisciplinaire à la croisée de l'informatique, de la linguistique et de l'intelligence artificielle. Il se concentre sur l'interaction entre le langage humain et les ordinateurs. Le TALN permet de programmer les machines pour qu'elles puissent analyser et traiter de vastes ensembles de données liés aux langues naturelles.
Autrement dit, le TALN est une technologie sophistiquée utilisée par les machines pour appréhender, analyser et interpréter le langage humain. Il confère aux machines la capacité de comprendre les textes et le langage oral des humains. Grâce au TALN, les machines peuvent effectuer des tâches telles que la traduction, la reconnaissance vocale, le résumé, la segmentation thématique, et bien d'autres, pour le compte des développeurs.
L'avantage majeur est que le TALN réalise toutes ces opérations en temps réel, en s'appuyant sur de multiples algorithmes, ce qui optimise son efficacité. C'est une technologie qui combine l'apprentissage automatique, l'apprentissage profond et des modèles statistiques à la modélisation informatique basée sur des règles linguistiques.
Les algorithmes du TALN permettent aux ordinateurs de traiter le langage humain par le biais de textes ou de données vocales et d'en déchiffrer le sens pour diverses applications. La capacité d'interprétation des ordinateurs a tellement évolué qu'ils peuvent même comprendre les sentiments et l'intention qui se cachent derrière un texte. Le TALN peut aussi anticiper les mots ou les expressions que l'utilisateur aura en tête lors de l'écriture ou de la parole.
Bien que cette technologie existe depuis plusieurs décennies, elle a évolué et gagné en précision au fil du temps. Le TALN trouve ses racines dans le domaine de la linguistique et a même aidé les développeurs à concevoir des moteurs de recherche pour Internet. Au fur et à mesure des progrès technologiques, l'utilisation du TALN s'est étendue.
Aujourd'hui, le TALN est appliqué dans une large gamme de domaines, allant de la finance, des moteurs de recherche et de l'intelligence économique aux soins de santé et à la robotique. De plus, le TALN a pénétré en profondeur les systèmes modernes ; il est présent dans de nombreuses applications courantes comme le GPS à commande vocale, les chatbots de service client, l'assistance numérique, la synthèse vocale, et bien d'autres.
Comment fonctionne le TALN ?
Le TALN est une technologie dynamique qui emploie différentes méthodes pour traduire le langage humain complexe en données exploitables par les machines. Il utilise principalement l'intelligence artificielle pour traiter et traduire les mots écrits ou parlés, de manière à ce qu'ils puissent être compris par les ordinateurs.
Alors que les humains utilisent leur cerveau pour traiter les informations, les ordinateurs s'appuient sur un programme spécialisé qui les aide à transformer les entrées en sorties compréhensibles. Le TALN opère en deux phases distinctes lors de la conversion : le traitement des données et le développement d'algorithmes.
Le traitement des données constitue la première étape. Les données textuelles d'entrée sont préparées et nettoyées afin de permettre à la machine de les analyser. Les données sont traitées de manière à mettre en évidence toutes les caractéristiques du texte d'entrée et à les rendre compatibles avec les algorithmes informatiques. Fondamentalement, cette étape prépare les données sous une forme que la machine peut interpréter.
Les techniques utilisées durant cette phase sont :
Source : Amazinum
- Tokenisation : le texte d'entrée est divisé en unités plus petites, appelées tokens, pour faciliter leur traitement par le TALN.
- Suppression des mots vides : cette technique élimine les mots courants du texte, comme "le", "la", "un", etc., qui n'apportent pas d'informations essentielles. On ne conserve que les mots importants.
- Lemmatisation et racinisation : ces processus réduisent les mots à leur forme racine ou lemme afin de simplifier leur traitement par les machines.
- Étiquetage morphosyntaxique (POS tagging) : les mots d'entrée sont identifiés selon leur rôle grammatical (nom, adjectif, verbe, etc.), puis ils sont analysés en conséquence.
Une fois que les données d'entrée ont franchi la première étape, la machine passe à la phase de développement d'algorithmes, où elles sont finalement traitées. Parmi les nombreux algorithmes du TALN utilisés pour traiter les mots préparés, les systèmes basés sur des règles et ceux basés sur l'apprentissage automatique sont largement utilisés :
- Systèmes basés sur des règles : dans ce cas, le système utilise des règles linguistiques pour le traitement final des mots. C'est une méthode ancienne qui est encore employée à grande échelle.
- Systèmes basés sur l'apprentissage automatique : il s'agit d'algorithmes plus avancés, combinant des réseaux de neurones, l'apprentissage profond et l'apprentissage automatique. Ces algorithmes définissent leurs propres règles de traitement des mots. S'appuyant sur des méthodes statistiques, ils déterminent comment traiter les mots en fonction des données d'apprentissage et apportent des modifications au fur et à mesure.
Les différentes catégories d'algorithmes du TALN
Les algorithmes du TALN sont des algorithmes ou des ensembles d'instructions basés sur l'apprentissage automatique (ML) utilisés lors du traitement des langues naturelles. Ils se concentrent sur la création de protocoles et de modèles permettant à une machine d'interpréter le langage humain.

Les algorithmes du TALN peuvent adopter différentes formes selon l'approche de l'IA et les données d'entraînement utilisées. Leur rôle principal est d'utiliser diverses techniques pour transformer des entrées confuses ou non structurées en informations exploitables. Ces informations peuvent être utilisées par la machine pour apprendre.
Ces algorithmes utilisent les principes du langage naturel pour rendre les entrées plus compréhensibles pour la machine. Ils permettent à la machine de comprendre la valeur contextuelle d'une entrée donnée, car sans cette valeur contextuelle, la machine ne serait pas capable de traiter la demande correctement.
Les algorithmes du TALN sont divisés en trois catégories principales, le choix de l'une d'entre elles par les modèles d'IA dépendant de l'approche du scientifique des données. Ces catégories sont :
#1. Algorithmes symboliques
Les algorithmes symboliques sont l'un des piliers du TALN. Ils sont chargés d'analyser le sens de chaque texte d'entrée, puis de l'utiliser pour établir des relations entre différents concepts.
Les algorithmes symboliques emploient des symboles pour représenter les connaissances ainsi que les relations entre les concepts. Ils s'appuient sur la logique et attribuent des significations aux mots en fonction de leur contexte, permettant d'atteindre un haut niveau de précision.
Les graphes de connaissances jouent également un rôle essentiel dans la définition des concepts d'une langue d'entrée et de leurs relations. En raison de sa capacité à définir correctement les concepts et à comprendre facilement les contextes des mots, cet algorithme est utile pour la construction de systèmes XAI (Explainable AI).
Cependant, les algorithmes symboliques sont difficiles à adapter à un ensemble de règles plus vaste en raison de diverses contraintes.
#2. Algorithmes statistiques
Les algorithmes statistiques facilitent le travail des machines en leur permettant de parcourir les textes, de les comprendre et d'en extraire le sens. C'est un algorithme du TALN très efficace, car il permet aux machines d'apprendre le langage humain en reconnaissant des schémas et des tendances dans les données textuelles d'entrée. Cette analyse permet aux machines de prédire le mot qui est le plus susceptible d'être écrit après le mot actuel, en temps réel.
Les algorithmes statistiques sont utilisés pour de nombreuses applications, allant de la reconnaissance vocale, de l'analyse des sentiments et de la traduction automatique à la suggestion de texte. Leur utilisation généralisée s'explique principalement par leur capacité à fonctionner sur de grands ensembles de données.
De plus, les algorithmes statistiques peuvent détecter si deux phrases d'un paragraphe ont un sens similaire et indiquer laquelle utiliser. Cependant, l'inconvénient majeur de cet algorithme est qu'il dépend en partie d'une ingénierie de fonctionnalités complexes.
#3. Algorithmes hybrides
Ce type d'algorithme du TALN combine la puissance des algorithmes symboliques et statistiques pour produire un résultat efficace. En se concentrant sur les principaux avantages et fonctionnalités, il peut facilement compenser les lacunes de chaque approche, ce qui est essentiel pour une grande précision.

Il existe de nombreuses façons d'utiliser les deux approches :
- Le symbolique venant en soutien à l'apprentissage automatique
- L'apprentissage automatique soutenant l'approche symbolique
- L'apprentissage symbolique et automatique fonctionnant en parallèle
Les algorithmes symboliques peuvent aider l'apprentissage automatique en lui fournissant un entraînement plus efficace, en réduisant ses efforts pour apprendre le langage par lui-même. De même, l'apprentissage automatique peut aider l'approche symbolique en créant un ensemble de règles initial pour cette dernière, épargnant aux scientifiques des données d'avoir à le construire manuellement.
Cependant, lorsque l'apprentissage symbolique et automatique travaillent ensemble, on obtient de meilleurs résultats, car cela garantit que les modèles comprennent correctement un passage spécifique.
Les meilleurs algorithmes du TALN
De nombreux algorithmes du TALN aident un ordinateur à imiter le langage humain pour la compréhension. Voici les meilleurs algorithmes du TALN que vous pouvez utiliser :
#1. Modélisation thématique
 Source de l'image : détartreur
Source de l'image : détartreur
La modélisation thématique est un algorithme utilisant des techniques statistiques du TALN pour identifier les thèmes ou sujets principaux à partir d'un grand nombre de documents texte.
En somme, elle permet aux machines de trouver le sujet qui définit un ensemble de textes particulier. Étant donné que chaque corpus de documents textuels contient de nombreux sujets, cet algorithme emploie toute technique appropriée pour découvrir chaque sujet en analysant des ensembles spécifiques de vocabulaire.
L'allocation latente de Dirichlet est un choix courant lorsqu'il s'agit d'appliquer la meilleure technique de modélisation thématique. C'est un algorithme d'apprentissage automatique non supervisé qui aide à regrouper et à organiser des archives contenant une grande quantité de données, ce qui est difficile à faire par une annotation humaine.
#2. Résumé de texte
Il s'agit d'une technique du TALN très utile où l'algorithme résume un texte de manière concise et fluide. C'est un processus rapide, car le résumé permet d'extraire toutes les informations essentielles sans avoir à examiner chaque mot.
La synthèse peut être effectuée de deux manières :
- Résumé par extraction : la machine se contente d'extraire les principaux mots et phrases du document, sans modifier le texte original.
- Résumé par abstraction : dans ce cas, de nouveaux mots et expressions sont générés à partir du texte du document, pour décrire l'ensemble des informations et des intentions.
#3. Analyse des sentiments
C'est l'algorithme du TALN qui permet à une machine de comprendre le sens ou l'intention qui se cache derrière un texte d'utilisateur. Il est très populaire et est utilisé dans différents modèles d'entreprise d'IA, car il aide les entreprises à comprendre ce que les clients pensent de leurs produits ou services.
En analysant l'intention des données textuelles ou vocales d'un client sur différentes plateformes, les modèles d'IA peuvent vous informer sur ses sentiments et vous aider à y répondre en conséquence.
#4. Extraction de mots-clés
L'extraction de mots-clés est un autre algorithme du TALN largement utilisé. Il permet d'extraire un grand nombre de mots et de phrases ciblés à partir d'un vaste ensemble de données textuelles.
Il existe plusieurs algorithmes d'extraction de mots-clés, dont TextRank, Term Frequency et RAKE. Certains algorithmes peuvent utiliser des mots supplémentaires, tandis que d'autres permettent d'extraire les mots-clés en fonction du contenu d'un texte donné.
Chaque algorithme d'extraction de mots-clés utilise ses propres méthodes théoriques et fondamentales. Il est avantageux pour de nombreuses organisations, car il facilite le stockage, la recherche et la récupération de contenu à partir d'un ensemble de données non structuré important.
#5. Graphes de connaissances
Lorsqu'il s'agit de choisir le meilleur algorithme du TALN, beaucoup considèrent les algorithmes de graphes de connaissances. Il s'agit d'une technique efficace qui utilise des triplets pour stocker des informations.
Cet algorithme est essentiellement un mélange de trois éléments : le sujet, le prédicat et l'entité. Cependant, la création d'un graphe de connaissances ne se limite pas à une seule technique. Elle nécessite plusieurs techniques du TALN pour être plus efficace et détaillée. L'approche par sujet est utilisée pour extraire des informations structurées à partir d'un ensemble de textes non structurés.
#6. TF-IDF
TF-IDF est un algorithme statistique du TALN qui permet d'évaluer l'importance d'un mot pour un document particulier appartenant à une collection de documents. Cette technique implique la multiplication de valeurs distinctes, qui sont :
- Fréquence du terme : cette valeur indique le nombre total de fois qu'un mot apparaît dans un document. Les mots vides ont généralement une fréquence de terme élevée dans un document.
- Fréquence inverse du document : cette valeur met en évidence les termes qui sont spécifiques à un document, ou les mots qui apparaissent moins souvent dans un corpus de documents.
#7. Nuage de mots
Le nuage de mots est un algorithme unique du TALN utilisant des techniques de visualisation de données. Dans cet algorithme, les mots importants sont mis en évidence, puis affichés dans un tableau.
Les mots essentiels du document sont imprimés en caractères gras et de grande taille, tandis que les mots moins importants sont affichés en petits caractères. Parfois, les éléments les moins importants ne sont même pas visibles sur le tableau.
Ressources d'apprentissage
En complément des informations ci-dessus, si vous souhaitez en savoir plus sur le Traitement Automatique du Langage Naturel (TALN), vous pouvez envisager les cours et les livres suivants.
#1. Science des données : traitement du langage naturel en Python
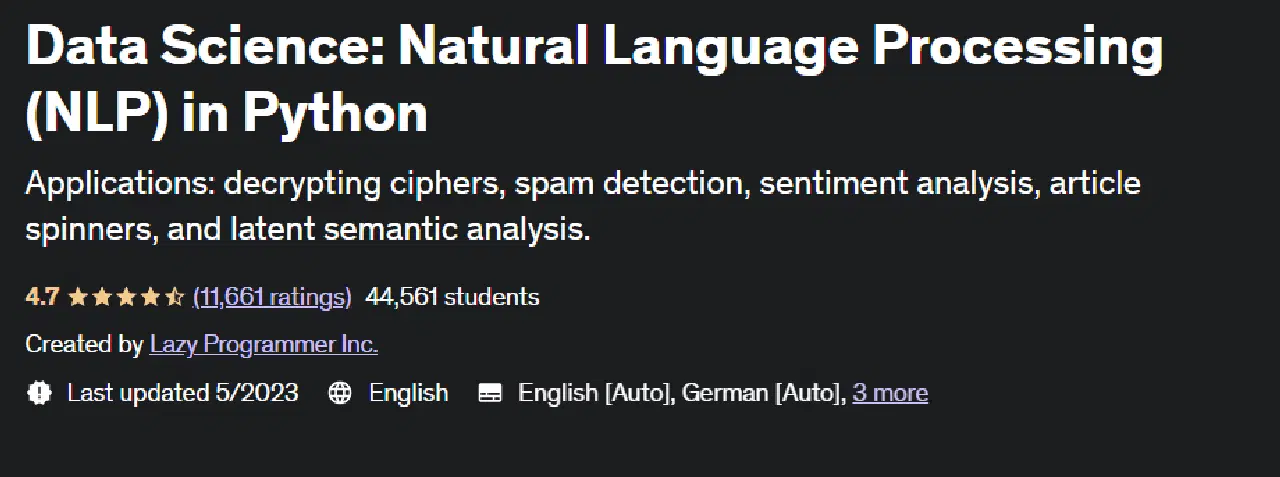
Ce cours Udemy est très apprécié des apprenants et a été créé par Lazy Programmer Inc. Il aborde tous les aspects des algorithmes du TALN et vous apprend à effectuer une analyse des sentiments. D'une durée totale de 11 heures et 52 minutes, ce cours vous donne accès à 88 conférences.
#2. Traitement automatique du langage naturel : TALN avec transformeurs en Python
Avec ce cours populaire d'Udemy, vous découvrirez non seulement le TALN avec des modèles de transformeurs, mais vous aurez également la possibilité de créer des modèles de transformeurs affinés. Ce cours couvre le TALN en profondeur, avec 11,5 heures de vidéo à la demande et 5 articles. De plus, vous découvrirez les techniques de création de vecteurs et le prétraitement des données textuelles pour le TALN.
#3. Traitement du langage naturel avec transformeurs
Ce livre a été publié pour la première fois en 2017 dans le but d'aider les scientifiques des données et les codeurs à se familiariser avec le TALN. Une fois que vous aurez commencé à lire le livre, vous pourrez créer et optimiser des modèles de transformeurs pour de nombreuses tâches du TALN. Vous apprendrez également comment vous pouvez utiliser les transformeurs pour l'apprentissage par transfert interlinguistique.
#4. Traitement pratique du langage naturel
Dans ce livre, les auteurs expliquent les tâches, les problèmes et les approches de solutions pour le TALN. Ce livre enseigne également la mise en œuvre et l'évaluation de différentes applications du TALN.
Conclusion
Le TALN fait partie intégrante du monde de l'IA moderne. Il aide les machines à comprendre et à interpréter les langues humaines. Les algorithmes du TALN sont utiles pour diverses applications, allant des moteurs de recherche et de l'informatique à la finance, au marketing et bien plus encore.
Outre les détails ci-dessus, nous avons également dressé une liste des meilleurs cours et livres sur le TALN qui vous aideront à approfondir vos connaissances dans ce domaine.