Ensemble Learning expliqué dans les termes les plus simples possibles
L'approche d'apprentissage d'ensemble peut s'avérer très utile pour optimiser vos prises de décision et aborder des problèmes complexes en combinant les prédictions de plusieurs modèles.
L'apprentissage automatique, ou ML, continue d'élargir son champ d'action dans de nombreux secteurs, qu'il s'agisse de la finance, de la santé, du développement d'applications ou de la sécurité.
Un entraînement adéquat des modèles ML est essentiel pour la réussite de vos projets. Différentes méthodes existent pour y parvenir.
Dans cet article, nous allons explorer l'apprentissage d'ensemble, en examinant son intérêt, ses applications concrètes et les techniques qu'il englobe.
Alors, restez avec nous pour en savoir plus !
Qu'est-ce que l'apprentissage d'ensemble ?
En apprentissage automatique et en statistique, le terme "ensemble" fait référence à des méthodes qui génèrent des hypothèses variées en se basant sur un apprenant commun de base.
L'apprentissage d'ensemble est une technique d'apprentissage machine qui consiste à créer et à combiner stratégiquement plusieurs modèles, tels que des experts ou des classificateurs. L'objectif est d'améliorer la résolution de problèmes complexes ou d'obtenir des prédictions plus précises.
Cette approche a pour but d'améliorer la capacité de prédiction, d'approximation de fonctions, ou de classification. Elle permet aussi de limiter le risque de choisir un modèle sous-optimal. Pour améliorer les performances prédictives, plusieurs algorithmes d'apprentissage sont mis à contribution.
Pourquoi l'apprentissage d'ensemble est-il important en ML ?
Dans les modèles d'apprentissage automatique, diverses sources d'erreurs peuvent survenir, telles que les biais, la variance ou le bruit. L'apprentissage d'ensemble peut aider à minimiser ces erreurs et à garantir la stabilité et la précision de vos algorithmes ML.
Voici quelques raisons pour lesquelles l'apprentissage d'ensemble est utilisé dans diverses situations :
Choisir le bon classificateur
L'apprentissage d'ensemble vous aide à sélectionner un modèle ou un classificateur plus performant, tout en réduisant les risques liés à un choix inapproprié.
Différents types de classificateurs sont utilisés pour des problèmes variés, comme les machines à vecteurs de support (SVM), le perceptron multicouche (MLP), les classificateurs bayésiens naïfs, les arbres de décision, etc. De plus, il existe plusieurs implémentations d'algorithmes de classification parmi lesquelles choisir. Les performances peuvent aussi varier en fonction des données d'entraînement.
Plutôt que de sélectionner un seul modèle, l'utilisation d'un ensemble de modèles et la combinaison de leurs sorties permet d'éviter de choisir des modèles moins performants.
Gestion du volume de données
De nombreuses méthodes et modèles ML ne produisent pas de résultats optimaux lorsqu'ils sont confrontés à des données insuffisantes ou, au contraire, à un volume de données trop important.
L'apprentissage d'ensemble, lui, peut fonctionner efficacement dans les deux scénarios.
- Si les données sont insuffisantes, l'amorçage peut être utilisé pour entraîner divers classificateurs à l'aide d'échantillons de données amorcés.
- En présence d'un volume de données trop important, il est possible de diviser stratégiquement les données en sous-ensembles plus petits.
Gérer la complexité

Un classificateur unique peut se révéler insuffisant pour résoudre des problèmes très complexes. Les limites de décision qui séparent les données de différentes classes peuvent être elles-mêmes complexes. Ainsi, un classificateur linéaire appliqué à une frontière non linéaire ne pourra pas l'appréhender.
Cependant, en combinant judicieusement plusieurs classificateurs linéaires, il est possible d'apprendre une limite non linéaire. Le classificateur divisera les données en plusieurs partitions plus simples à apprendre, chaque classificateur apprenant une seule partition. Ensuite, ces classificateurs sont combinés pour produire une limite de décision globale.
Estimation de la confiance
En apprentissage d'ensemble, une confiance est attribuée à une décision prise par un système. Imaginons un ensemble de classificateurs entraînés pour un problème donné. Si la majorité de ces classificateurs s'accordent sur une décision, le résultat sera considéré comme ayant une forte confiance.
Inversement, si la moitié des classificateurs ne sont pas d'accord, la décision aura une faible confiance.
Il est important de noter que le niveau de confiance ne garantit pas toujours la validité d'une décision. Cependant, une décision fortement confiante a plus de chances d'être correcte si l'ensemble a été correctement entraîné.
Amélioration de la précision par la fusion de données
La combinaison stratégique de données provenant de diverses sources peut améliorer la précision des décisions de classification. Cette précision est supérieure à celle obtenue à partir d'une seule source de données.
Comment fonctionne l'apprentissage d'ensemble ?
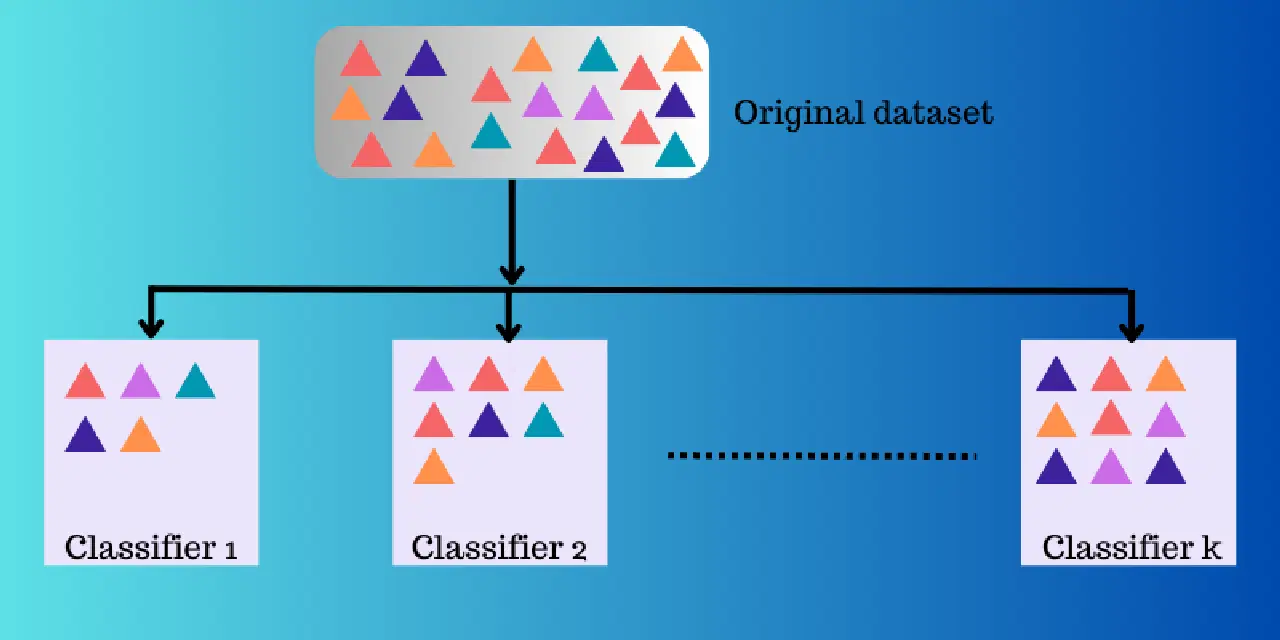
L'apprentissage d'ensemble utilise plusieurs fonctions de mappage acquises par différents classificateurs, puis les combine pour créer une fonction de mappage unique.
Prenons un exemple pour mieux comprendre le fonctionnement de l'apprentissage d'ensemble.
Imaginez que vous développiez une application dédiée à l'alimentation. Pour offrir une expérience utilisateur optimale, vous voulez collecter des retours sur les problèmes rencontrés, les lacunes, les erreurs, etc.
Pour cela, vous pouvez solliciter l'avis de votre famille, de vos amis, de vos collègues ou d'autres personnes avec lesquelles vous communiquez régulièrement, sur leurs choix alimentaires et leur expérience de commande en ligne. Vous pouvez aussi lancer une version bêta de l'application pour recueillir des retours en temps réel, sans biais ni bruit.
Ce que vous faites ici, c'est prendre en compte plusieurs idées et opinions pour améliorer l'expérience utilisateur.
L'apprentissage d'ensemble et ses modèles fonctionnent de la même manière. Il utilise un ensemble de modèles et les combine pour produire un résultat final, améliorant ainsi la précision et la performance des prévisions.
Techniques fondamentales d'apprentissage d'ensemble
#1. Mode
Le "mode" est la valeur qui apparaît le plus souvent dans un ensemble de données. En apprentissage d'ensemble, les experts en ML utilisent plusieurs modèles pour faire des prédictions sur chaque point de données. Ces prédictions sont considérées comme des votes individuels, et la prédiction faite par la majorité des modèles est retenue comme prédiction finale. Cette technique est principalement utilisée pour les problèmes de classification.
Par exemple : Si quatre personnes ont noté votre application avec 4, tandis qu'une autre lui a attribué 3, le mode serait de 4, car c'est la note qui a été donnée par la majorité.
#2. Moyenne
Avec cette technique, les professionnels prennent en compte toutes les prédictions du modèle et calculent leur moyenne pour obtenir la prédiction finale. Elle est surtout utilisée pour faire des prédictions pour les problèmes de régression ou pour calculer les probabilités pour les problèmes de classification.
Reprenons l'exemple précédent où quatre personnes ont noté l'application avec 4, et une personne avec 3. La moyenne serait (4+4+4+4+3)/5 = 3,8.
#3. Moyenne pondérée
Dans cette méthode, les professionnels attribuent différents poids à chaque modèle pour faire une prédiction. Le poids attribué reflète la pertinence de chaque modèle.
Par exemple : Si 5 personnes ont donné leur avis sur votre application, et que parmi elles, 3 sont des développeurs d'applications, alors leurs commentaires auront plus de poids que les 2 autres personnes sans expérience de développement.
Techniques avancées d'apprentissage d'ensemble
#1. Ensachage (Bagging)
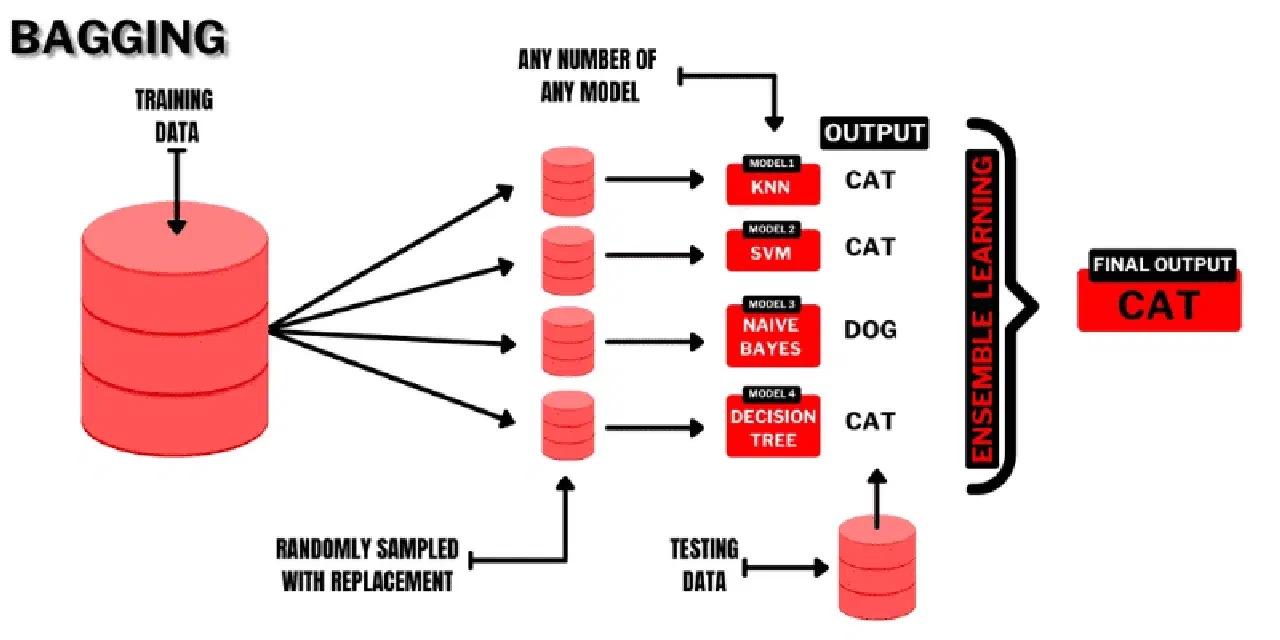
Le bagging (Bootstrap AGGregatING) est une technique d'apprentissage d'ensemble à la fois intuitive, simple et performante. Son nom vient de la combinaison des termes "Bootstrap" et "agrégation".
Le bootstrap est une méthode d'échantillonnage qui consiste à créer plusieurs sous-ensembles à partir d'un ensemble de données d'origine, avec remplacement. Chaque sous-ensemble a la même taille que l'ensemble de données d'origine.
 Source : Programmeur de buggy
Source : Programmeur de buggy
Dans l'ensachage, les sous-ensembles (ou "sacs") sont utilisés pour comprendre la distribution de l'ensemble. Cependant, les sous-ensembles peuvent être plus petits que l'ensemble de données d'origine. Cette méthode utilise un seul algorithme ML. Le but de la combinaison des résultats des différents modèles est d'obtenir un résultat généralisé.
Voici comment fonctionne l'ensachage :
- Plusieurs sous-ensembles sont générés à partir de l'ensemble d'origine, avec remplacement. Ces sous-ensembles sont utilisés pour entraîner des modèles ou des arbres de décision.
- Un modèle faible (ou de base) est créé pour chaque sous-ensemble. Les modèles sont indépendants et fonctionnent en parallèle.
- La prédiction finale est faite en combinant les prédictions de chaque modèle, à l'aide de statistiques comme la moyenne ou le vote.
Les algorithmes populaires utilisés dans cette technique d'ensemble sont :
- Forêt aléatoire
- Arbres de décision ensachés
L'avantage de cette méthode est qu'elle permet de réduire les erreurs de variance dans les arbres de décision.
#2. Empilement (Stacking)
 Source de l'image : OpenGenus IQ
Source de l'image : OpenGenus IQ
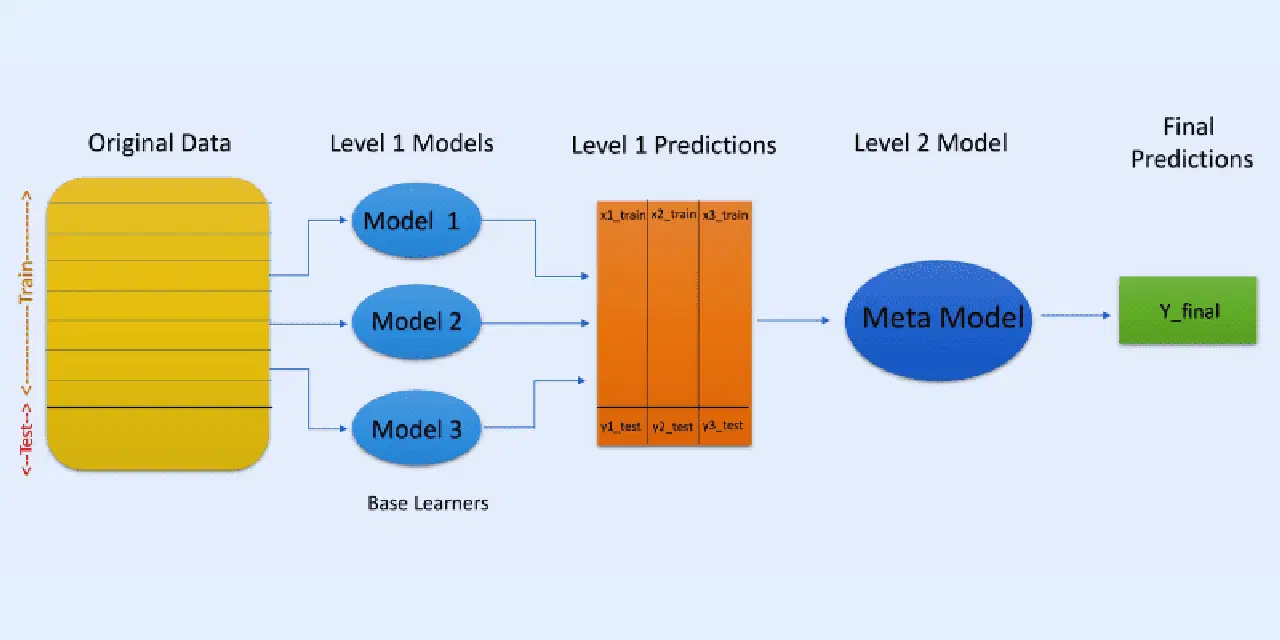
Dans l'empilement, ou généralisation empilée, les prédictions de différents modèles, comme un arbre de décision, sont utilisées pour créer un nouveau modèle, afin de faire des prédictions sur un ensemble de test.
L'empilement implique la création de sous-ensembles de données amorcées pour l'entraînement des modèles, de façon similaire au bagging. Cependant, ici, la sortie des modèles sert d'entrée pour un autre classificateur, appelé méta-classificateur, qui effectuera la prédiction finale.
L'utilisation de deux couches de classificateurs permet de déterminer si les ensembles de données d'apprentissage sont correctement appris. L'approche à deux couches est la plus courante, mais il est possible d'utiliser davantage de couches.
Par exemple, vous pouvez utiliser 3 à 5 modèles dans la première couche (niveau 1) et un seul modèle dans la deuxième couche (niveau 2). Ce dernier combinera les prédictions obtenues au niveau 1 pour faire la prédiction finale.
De plus, vous pouvez utiliser n'importe quel modèle d'apprentissage ML pour agréger les prédictions ; un modèle linéaire comme la régression linéaire ou la régression logistique est souvent utilisé.
Les algorithmes ML populaires utilisés dans l'empilement sont :
- Mélange
- Super ensemble
- Modèles empilés
Remarque : Le mélange utilise un ensemble de validation (ou d'exclusion) de l'ensemble de données d'apprentissage pour effectuer les prédictions. Contrairement à l'empilement, le mélange implique de ne faire des prédictions qu'à partir de l'ensemble d'exclusion.
#3. Boosting
Le boosting est une méthode itérative d'apprentissage d'ensemble qui ajuste le poids d'une observation spécifique en fonction de sa classification précédente ou la plus récente. Chaque modèle ultérieur vise donc à corriger les erreurs trouvées dans le modèle précédent.
Si une observation est mal classée, le boosting augmente son poids.
Dans le boosting, les experts entraînent le premier algorithme de boosting sur un ensemble de données complet. Les algorithmes ML suivants sont construits à partir des résidus extraits de l'algorithme de boosting précédent. Ainsi, un poids plus important est donné aux observations mal prédites par le modèle précédent.
Voici comment cela fonctionne, étape par étape :
- Un sous-ensemble est généré à partir de l'ensemble de données d'origine. Chaque point de données a initialement le même poids.
- Un modèle de base est créé sur le sous-ensemble.
- La prédiction est faite sur l'ensemble de données complet.
- Les erreurs sont calculées à partir des valeurs réelles et prédites.
- Les observations mal prédites reçoivent un poids plus important.
- Un nouveau modèle est créé et la prédiction finale est faite sur cet ensemble de données, le modèle essayant de corriger les erreurs précédemment commises. Plusieurs modèles sont créés de manière similaire, chacun corrigeant les erreurs du précédent.
- La prédiction finale est faite à partir du modèle final, qui est la moyenne pondérée de tous les modèles.
Les algorithmes de boosting populaires sont :
- CatBoost
- GBM léger
- AdaBoost
L'avantage du boosting est qu'il génère des prédictions de meilleure qualité et réduit les erreurs dues aux biais.
Autres techniques d'ensemble

Mélange d'experts : Il est utilisé pour entraîner plusieurs classificateurs, et leurs sorties sont combinées à l'aide d'une règle linéaire générale. Ici, les poids donnés aux combinaisons sont déterminés par un modèle entraînable.
Vote majoritaire : il s'agit de choisir un classificateur impair, et les prédictions sont calculées pour chaque échantillon. La classe qui reçoit le plus grand nombre de votes de la part des classificateurs est la classe prédite par l'ensemble. Il est utilisé pour résoudre des problèmes comme la classification binaire.
Max Rule : Il utilise les distributions de probabilité de chaque classificateur et la confiance pour faire des prédictions. Il est utilisé pour les problèmes de classification multi-classes.
Cas d'utilisation réels de l'apprentissage d'ensemble
#1. Détection des visages et des émotions
L'apprentissage d'ensemble utilise des techniques comme l'analyse des composants indépendants (ICA) pour la détection des visages.
Il est également utilisé pour détecter les émotions à partir de la parole, et permet également d'analyser les émotions faciales.
#2. Sécurité
Détection de la fraude : L'apprentissage d'ensemble permet d'améliorer la modélisation du comportement normal. Il est efficace pour détecter les activités frauduleuses, par exemple dans les systèmes de cartes de crédit et bancaires, les fraudes aux télécommunications, le blanchiment d'argent, etc.

DDoS : Le déni de service distribué (DDoS) est une attaque sérieuse contre les fournisseurs d'accès Internet. Les classificateurs d'ensemble peuvent réduire la détection d'erreurs et également distinguer les attaques du trafic légitime.
Détection d'intrusion : L'apprentissage d'ensemble peut être utilisé dans des systèmes de surveillance, comme des outils de détection d'intrusion, afin de détecter des codes d'intrus en surveillant des réseaux ou des systèmes, en trouvant des anomalies, etc.
Détection de logiciels malveillants : L'apprentissage d'ensemble est efficace pour détecter et classer les codes malveillants tels que les virus, les vers informatiques, les rançongiciels, les chevaux de Troie, les logiciels espions, etc., grâce aux techniques d'apprentissage automatique.
#3. Apprentissage incrémental
En apprentissage incrémental, un algorithme ML apprend à partir d'un nouvel ensemble de données tout en conservant les apprentissages précédents, mais sans accéder aux données précédentes qu'il a vues. Les systèmes d'ensemble sont utilisés pour l'apprentissage incrémental en ajoutant un classificateur supplémentaire à chaque nouvel ensemble de données.
#4. Médecine

Les classificateurs d'ensemble sont utiles pour le diagnostic médical, comme la détection de troubles neurocognitifs (tels que la maladie d'Alzheimer). Ils effectuent la détection à partir d'ensembles de données IRM et classifient la cytologie cervicale. De plus, ils sont appliqués en protéomique (étude des protéines), en neurosciences et dans d'autres domaines.
#5. Télédétection
Détection des changements : Les classificateurs d'ensemble sont utilisés pour détecter des changements, à l'aide de méthodes comme la moyenne bayésienne ou le vote majoritaire.
Cartographie de la couverture terrestre : Des méthodes d'apprentissage d'ensemble comme le boosting, les arbres de décision ou l'analyse en composantes principales du noyau (KPCA) sont utilisées pour cartographier efficacement la couverture terrestre.
#6. Finance
La précision est un aspect essentiel de la finance, qu'il s'agisse de calculs ou de prédictions. Elle influence fortement le résultat des décisions que vous prenez. L'apprentissage d'ensemble permet aussi d'analyser les changements dans les données boursières ou de détecter la manipulation des cours.
Ressources d'apprentissage complémentaires

#1. Méthodes d'ensemble pour l'apprentissage automatique
Ce livre vous aidera à apprendre et à mettre en œuvre les méthodes clés de l'apprentissage d'ensemble, en partant de zéro.
#2. Méthodes d'ensemble : fondements et algorithmes
Ce livre présente les bases de l'apprentissage d'ensemble et de ses algorithmes. Il décrit également comment l'apprentissage d'ensemble est utilisé dans le monde réel.
#3. Apprentissage d'ensemble
Il propose une introduction à une méthode d'ensemble unifiée, les enjeux et les applications.
#4. Ensemble Machine Learning : méthodes et applications :
Il offre une vue d'ensemble des techniques avancées d'apprentissage d'ensemble.
Conclusion
J'espère que vous avez maintenant une bonne idée de l'apprentissage d'ensemble, de ses méthodes, de ses cas d'utilisation et de son intérêt pour vos projets. Il a le potentiel de résoudre de nombreux défis, de la sécurité au développement d'applications en passant par la finance et la médecine. Ses utilisations sont en plein développement et ce concept est appelé à s'améliorer dans un futur proche.
Vous pouvez également explorer certains outils de génération de données synthétiques pour entraîner des modèles d'apprentissage automatique.