Démarrer le traitement des données avec Kafka et Spark
La gestion des masses de données représente un défi majeur pour les organisations. La complexité s'accroît lorsque ces données affluent en temps réel et en grande quantité.
Cet article explore le concept du traitement de données massives, les méthodes employées, et met en lumière deux outils phares : Apache Kafka et Spark.
Qu'est-ce que le traitement de données et comment s'effectue-t-il ?
Le traitement de données englobe toute opération, automatisée ou non, visant à collecter, organiser et structurer des informations afin de les rendre interprétables. Imaginez un utilisateur qui effectue une requête dans une base de données ; le traitement des données est le mécanisme qui lui fournit le résultat attendu. Ainsi, les technologies de l'information reposent fondamentalement sur le traitement de données.
Auparavant, un logiciel simple suffisait pour traiter les données. L'essor du Big Data, caractérisé par des volumes d'informations dépassant souvent des centaines de téraoctets, voire des pétaoctets, a bouleversé ce paysage. Ces données, mises à jour en continu (provenant de centres d'appel, de réseaux sociaux, de transactions boursières...), sont qualifiées de flux de données, un flot constant et sans limite apparente.
Le traitement des données se fait généralement en continu, au fur et à mesure de leur arrivée. Cette approche est appelée traitement en temps réel ou en ligne. Une autre méthode consiste à traiter les données par lots, à intervalles de quelques heures ou jours, souvent durant la nuit, pour consolider les informations de la journée. Ces traitements par lots peuvent cependant générer des rapports obsolètes s'ils s'étendent sur des semaines ou des mois.
Les plateformes open source comme Kafka et Spark sont privilégiées pour le traitement du Big Data en flux continu. Leur nature ouverte favorise une évolution rapide et l'intégration de nombreux outils. Les flux de données peuvent ainsi être reçus de diverses sources, avec des débits variables et sans interruption.
Examinons de plus près deux des outils de traitement de données les plus renommés, en les comparant :
Apache Kafka
Apache Kafka est un système de messagerie conçu pour les applications de streaming avec un flux de données ininterrompu. Initialement développé par LinkedIn, il fonctionne sur le principe des journaux, où chaque nouvelle information est ajoutée à la fin du fichier.
Kafka est une solution de choix pour le Big Data grâce à son débit élevé, et permet même de passer d'un traitement par lots à un traitement en temps réel.
Ce système de messagerie fonctionne selon un modèle de publication-abonnement : une application publie des messages, tandis qu'une autre s'y abonne pour les recevoir. Le délai entre la publication et la réception peut être de quelques millisecondes, ce qui garantit une faible latence.
Fonctionnement de Kafka
L'architecture de Kafka est composée de producteurs, de consommateurs, et du cluster lui-même. Les producteurs sont les applications qui publient des messages ; les consommateurs, celles qui les reçoivent. Le cluster Kafka, lui, est un ensemble de nœuds fonctionnant comme une unique instance du service de messagerie.
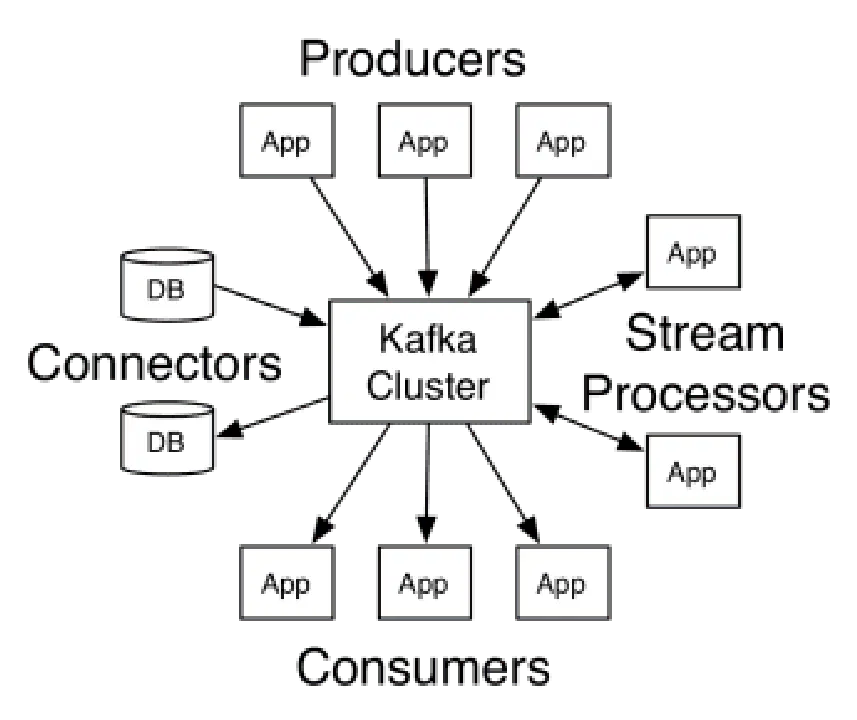
Un cluster Kafka est constitué de plusieurs brokers, des serveurs qui reçoivent les messages des producteurs et les stockent sur disque. Chaque broker gère une liste de sujets, divisés en plusieurs partitions.
Après réception, le broker transmet les messages aux consommateurs abonnés à chaque sujet.
La gestion des paramètres d'Apache Kafka est confiée à Apache Zookeeper, qui conserve les métadonnées du cluster (emplacement des partitions, listes de noms, de sujets, et nœuds disponibles). Ainsi, Zookeeper assure la synchronisation entre les différents composants du cluster.
Zookeeper est essentiel car Kafka est un système distribué, où l'écriture et la lecture sont effectuées simultanément par plusieurs clients. En cas de panne, Zookeeper élit un remplaçant et reprend l'opération.
Cas d'utilisation
Bien que principalement connu comme outil de messagerie, Kafka est polyvalent et peut être utilisé dans divers contextes, tels que :
Messagerie
Un mode de communication asynchrone qui dissocie les parties communicantes. Une partie envoie des données à Kafka, tandis qu'une autre application les consomme ultérieurement.
Suivi d'activité
Permet de stocker et traiter les données d'interaction d'un utilisateur avec un site web (pages vues, clics, saisie de données...). Ce type d'activité génère généralement de gros volumes de données.
Métriques
Consiste à agréger des données et des statistiques provenant de diverses sources pour générer un rapport centralisé.
Agrégation de journaux
Permet d'agréger et stocker de manière centralisée les fichiers journaux provenant de différents systèmes.
Traitement de flux
Le traitement des pipelines de données comprend plusieurs étapes, où les données brutes sont consommées à partir de sujets, puis agrégées, enrichies ou transformées en d'autres sujets.
Pour ces fonctionnalités, la plateforme met à disposition trois API principales :
- API Streams : agit comme un processeur de flux, consommant les données d'un sujet, les transformant et les écrivant dans un autre.
- API Connecteurs : permet de connecter des sujets à des systèmes existants, comme des bases de données relationnelles.
- API producteur et consommateur : permettent aux applications de publier et consommer des données Kafka.
Avantages
Réplication, partitionnement et ordre
Les messages dans Kafka sont répliqués sur les partitions des nœuds du cluster selon leur ordre d'arrivée, pour garantir la sécurité et la rapidité de livraison.
Transformation de données
Avec Kafka, il est même possible de transformer un traitement par lots en temps réel en utilisant l'API de flux ETL par lots.
Accès séquentiel au disque
Kafka conserve les messages sur disque, plutôt qu'en mémoire, car cela se révèle plus rapide dans son cas d'utilisation. Bien que l'accès à la mémoire soit généralement plus rapide, notamment pour les données situées à des emplacements aléatoires, Kafka effectue un accès séquentiel, pour lequel le disque est plus efficace.
Apache Spark
Apache Spark est un moteur de calcul Big Data et un ensemble de bibliothèques dédiées au traitement de données parallèles au sein de clusters. Évolution de Hadoop et du paradigme Map-Reduce, Spark peut être jusqu'à 100 fois plus rapide grâce à une utilisation efficace de la mémoire, évitant ainsi le stockage des données sur disque durant le traitement.

Spark est structuré en trois niveaux :
- API de bas niveau : contient les fonctionnalités essentielles à l'exécution des tâches, la gestion de la sécurité, du réseau, de la planification, et l'accès logique aux systèmes de fichiers HDFS, GlusterFS, Amazon S3, etc.
- API structurées : ce niveau permet de manipuler les données via des ensembles de données ou des cadres de données, lus dans des formats tels que Hive, Parquet, JSON, etc. Avec SparkSQL (API permettant d'écrire des requêtes en SQL), les données peuvent être manipulées selon les besoins.
- Haut niveau : l'écosystème Spark comprend diverses bibliothèques comme Spark Streaming, Spark MLlib et Spark GraphX. Elles se chargent de l'ingestion de flux et des processus associés, tels que la récupération sur incident, la création de modèles d'apprentissage automatique et la gestion de graphiques et d'algorithmes.
Fonctionnement de Spark
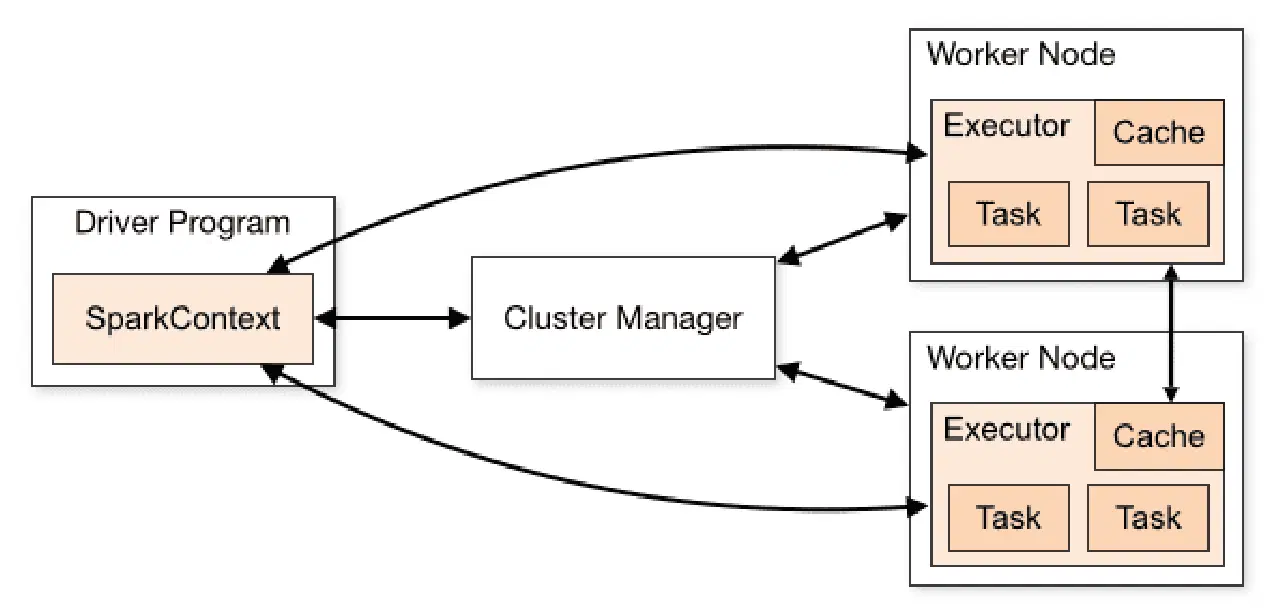
L'architecture d'une application Spark se compose de trois éléments principaux :
Driver Program : Responsable de l'orchestration de l'exécution du traitement des données.
Cluster Manager : Composant qui gère les différentes machines d'un cluster, nécessaire si Spark est exécuté de manière distribuée.
Nœuds de travail : Les machines qui exécutent les tâches d'un programme. Si Spark est exécuté localement, la machine jouera à la fois le rôle de programme pilote et de nœud de travail. Cette méthode d'exécution est appelée "Standalone".
Le code Spark peut être écrit dans plusieurs langages. La console Spark, appelée Spark Shell, est interactive pour l'apprentissage et l'exploration des données.
Une application Spark se compose d'un ou plusieurs Jobs, ce qui permet le traitement de données à grande échelle.
L'exécution de Spark peut se faire de deux manières :
- Client : Le pilote est exécuté directement sur le client, sans passer par le Resource Manager.
- Cluster : Le pilote est exécuté sur l'application maître via le gestionnaire de ressources. Dans ce mode, l'application continue de s'exécuter même si le client se déconnecte.
Une utilisation correcte de Spark est essentielle pour permettre aux services associés (comme le gestionnaire de ressources) d'identifier les besoins de chaque exécution et d'optimiser les performances. Il incombe donc au développeur de connaître la meilleure façon d'exécuter ses jobs Spark, en structurant l'appel effectué et en configurant les exécuteurs Spark comme souhaité.
Les tâches Spark utilisant majoritairement la mémoire, il est courant d'ajuster les valeurs de configuration des exécuteurs de nœuds de travail. Une configuration non standard peut parfois offrir des exécutions plus optimales. Des tests comparatifs entre les options de configuration disponibles et la configuration par défaut peuvent permettre de déterminer la meilleure approche.
Cas d'utilisation
Apache Spark est utile pour traiter d'énormes quantités de données, qu'elles soient en temps réel ou archivées, structurées ou non structurées. Voici quelques cas d'utilisation courants :
Enrichissement des données
Les entreprises utilisent souvent des données clients historiques avec des données comportementales en temps réel. Spark peut aider à créer un pipeline ETL continu pour convertir des données d'événements non structurées en données structurées.
Déclenchement de détection d'événements
Spark Streaming permet une détection et une réponse rapides à des comportements rares ou suspects, qui pourraient signaler un problème potentiel ou une fraude.
Analyse de données de session complexes
Spark Streaming permet de regrouper et analyser les événements liés à la session de l'utilisateur (par exemple, ses activités après sa connexion à l'application). Ces informations peuvent aussi être utilisées en continu pour mettre à jour des modèles d'apprentissage automatique.
Avantages
Traitement itératif
Si une tâche implique de traiter des données de manière répétée, les ensembles de données distribués (RDD) de Spark permettent plusieurs opérations de mappage en mémoire, sans avoir à écrire les résultats intermédiaires sur disque.
Traitement graphique
Le modèle de calcul de Spark, avec l'API GraphX, est idéal pour les calculs itératifs typiques du traitement graphique.
Apprentissage automatique
Spark dispose de MLlib, une bibliothèque d'apprentissage automatique intégrée, qui contient des algorithmes prêts à l'emploi, également exécutés en mémoire.
Kafka contre Spark
Malgré un intérêt similaire, des différences majeures existent entre Kafka et Spark :
#1. Traitement de l'information
Kafka est un outil de streaming et de stockage de données en temps réel, qui assure le transfert de données entre les applications, mais ne suffit pas pour construire une solution complète. Des outils supplémentaires, comme Spark, sont nécessaires pour les tâches que Kafka ne prend pas en charge. Spark, de son côté, est une plateforme de traitement de données par lots qui extrait les données des sujets Kafka et les transforme en schémas combinés.
#2. Gestion de la mémoire
Spark utilise des ensembles de données distribués robustes (RDD) pour la gestion de la mémoire. Au lieu de traiter d'énormes ensembles de données, il les distribue sur plusieurs nœuds d'un cluster. Kafka, quant à lui, utilise un accès séquentiel similaire à HDFS et stocke les données dans une mémoire tampon.
#3. Transformation ETL
Spark et Kafka prennent tous deux en charge le processus de transformation ETL, qui copie les enregistrements d'une base de données à une autre (souvent d'une base transactionnelle OLTP à une base analytique OLAP). Contrairement à Spark, qui possède une capacité intégrée pour ce processus, Kafka s'appuie sur l'API Streams pour le prendre en charge.
#4. Persistance des données

L'utilisation des RDD par Spark permet de stocker les données à plusieurs emplacements pour une utilisation ultérieure, alors que Kafka nécessite la définition d'objets de jeu de données dans la configuration pour conserver les données.
#5. Complexité
Spark est une solution complète et plus facile à prendre en main, grâce à sa compatibilité avec divers langages de programmation de haut niveau. Kafka dépend d'un certain nombre d'API et de modules tiers différents, ce qui peut rendre son utilisation plus complexe.
#6. Récupération
Spark et Kafka proposent tous deux des options de récupération. Spark utilise les RDD, qui lui permettent de sauvegarder les données en continu et de les récupérer en cas de défaillance du cluster.

Kafka réplique en permanence les données au sein du cluster et entre les brokers, ce qui permet de basculer vers différents brokers en cas de panne.
Similitudes entre Spark et Kafka
| Apache Spark | Apache Kafka | |
| Open Source | Oui | Oui |
| Applications de streaming | Création d'applications de streaming de données | Création d'applications de streaming de données |
| Traitement avec état | Oui | Oui |
| SQL | Oui | Oui |
Conclusion
Kafka et Spark sont deux outils open source, écrits en Scala et Java, qui permettent de créer des applications de streaming de données en temps réel. Ils partagent plusieurs points communs, tels que le traitement avec état, la compatibilité avec SQL et l'ETL. Ils peuvent aussi être utilisés de manière complémentaire, afin de simplifier le transfert de données entre les applications.