Data Lakehouse : alimenter votre parcours basé sur les données
L'architecture Data Lakehouse représente une avancée significative dans la gestion des données, en fusionnant les avantages d'un lac de données et d'un entrepôt de données. Cette approche innovante permet de centraliser le stockage de données diversifiées sur une plateforme unique, tout en garantissant la conformité aux principes ACID pour les requêtes et les analyses.
En tant qu'ingénieur logiciel expérimenté, je comprends les défis liés à la gestion et à la maintenance de systèmes de données distincts, ainsi qu'à la circulation de volumes importants de données entre ces derniers. L'intérêt d'un Data Lakehouse est de simplifier cette complexité.
Traditionnellement, les données structurées destinées à l'analyse décisionnelle et à la création de rapports étaient stockées dans des entrepôts de données, tandis que les lacs de données étaient utilisés pour stocker des données brutes, non structurées, provenant de sources variées. L'approche Data Lakehouse offre une solution unifiée, en combinant les meilleures fonctionnalités des deux mondes, éliminant ainsi la nécessité de maintenir des systèmes distincts.
Importance des Data Lakehouse
Pour assurer la croissance et le développement d'une organisation, il est essentiel de pouvoir stocker et analyser des données, quelle que soit leur forme ou leur structure. Les Data Lakehouse jouent un rôle crucial dans la gestion moderne des données, en comblant les lacunes des lacs de données et des entrepôts de données traditionnels.
Les lacs de données peuvent rapidement devenir des "marécages" de données, caractérisés par un manque de structure et de gouvernance, rendant difficile la recherche et l'utilisation des informations, et potentiellement source de problèmes de qualité. Les entrepôts de données, quant à eux, peuvent s'avérer trop rigides et coûteux.
Un Data Lakehouse se distingue par un ensemble de caractéristiques spécifiques que nous allons explorer.
Caractéristiques d'un Data Lakehouse
Avant d'aborder l'architecture d'un Data Lakehouse, examinons ses fonctionnalités et caractéristiques clés.
- Prise en charge des transactions : Dans un environnement de lac de données à grande échelle, de multiples lectures et écritures peuvent se produire simultanément. La conformité ACID assure l'intégrité des données en garantissant que les opérations simultanées ne génèrent pas d'incohérences.
- Compatibilité avec la Business Intelligence : Les outils de BI peuvent être connectés directement aux données indexées, évitant ainsi la nécessité de les copier ailleurs. De plus, cette approche permet d'accéder aux dernières informations rapidement et à moindre coût.
- Séparation du stockage et du calcul : La séparation de ces deux niveaux permet de mettre à l'échelle l'un ou l'autre indépendamment, en ajoutant du stockage sans avoir à augmenter le calcul, et inversement.
- Gestion de types de données variés : S'appuyant sur un lac de données, un Data Lakehouse peut gérer une grande variété de types et de formats de données, notamment audio, vidéo, images et texte.
- Formats de stockage ouverts : Les Data Lakehouse utilisent des formats ouverts et standardisés, tel que Parquet Apache, facilitant l'intégration avec divers outils et bibliothèques pour accéder aux données.
- Prise en charge de divers workloads : Les données stockées dans un Data Lakehouse peuvent être utilisées pour un large éventail de tâches, notamment les requêtes SQL, la BI, l'analyse et l'apprentissage automatique.
- Traitement du flux en temps réel : Il n'est plus nécessaire de mettre en place des systèmes de stockage ou des pipelines spécifiques pour l'analyse en temps réel.
- Gouvernance des schémas : Les Data Lakehouse favorisent une gouvernance et un audit rigoureux des données.
Architecture d'un Data Lakehouse
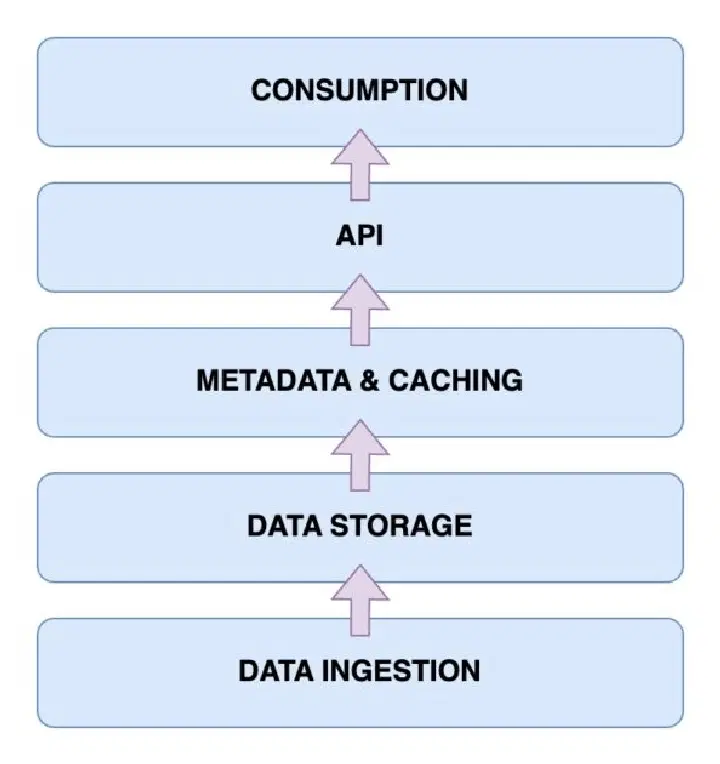
L'architecture d'un Data Lakehouse repose sur cinq éléments principaux qu'il est essentiel de comprendre pour appréhender son fonctionnement.
Couche d'ingestion des données
Cette couche est responsable de la capture des données provenant de diverses sources et dans différents formats. Cela peut inclure des modifications dans une base de données principale, des données provenant de capteurs IoT ou des flux de données utilisateurs en temps réel.
Couche de stockage des données
Une fois ingérées, les données sont stockées dans leurs formats respectifs. Cette couche peut s'appuyer sur des solutions telles qu'AWS S3, qui constitue votre lac de données.
Couche de métadonnées et de mise en cache
Cette couche assure la gestion des métadonnées, offrant une vue unifiée de toutes les données stockées dans le lac. Elle permet également d'ajouter les transactions ACID au lac de données existant, le transformant ainsi en Data Lakehouse.
Couche API
L'accès aux données indexées se fait via la couche API, qui peut être implémentée sous forme de pilotes de base de données, permettant d'exécuter des requêtes via du code, ou via des points de terminaison accessibles par différents clients.
Couche de consommation des données
Cette couche regroupe les outils d'analyse et de Business Intelligence, qui sont les principaux consommateurs des données stockées dans le Data Lakehouse. Elle permet également l'exécution de modèles d'apprentissage automatique pour extraire des informations précieuses à partir des données.
Maintenant que nous avons une bonne compréhension de l'architecture d'un Data Lakehouse, voyons comment en construire un.
Étapes pour créer un Data Lakehouse
Les étapes pour construire un Data Lakehouse sont similaires, que vous partiez d'un lac ou d'un entrepôt de données existant ou que vous construisiez à partir de zéro.
- Identifier les exigences : Définir les types de données à stocker et les cas d'utilisation visés, tels que les modèles d'apprentissage automatique, les rapports commerciaux et les analyses.
- Créer un pipeline d'ingestion : Mettre en place un système pour importer les données dans votre système. Selon les sources, cela peut nécessiter des bus de messagerie tels qu'Apache Kafka ou des points de terminaison d'API.
- Construire la couche de stockage : Utiliser un lac de données existant ou choisir parmi des options comme AWS S3, HDFS ou Delta Lake.
- Appliquer le traitement des données : Extraire et transformer les données en fonction des besoins de l'entreprise à l'aide d'outils open source comme Apache Spark pour exécuter des tâches de traitement régulières.
- Mettre en place la gestion des métadonnées : Suivre et stocker les différents types de données et leurs propriétés pour faciliter le catalogage et la recherche, et éventuellement créer une couche de mise en cache.
- Fournir des options d'intégration : Offrir des points d'accès pour que des outils externes puissent se connecter et accéder aux données, que ce soit par le biais de requêtes SQL, d'outils d'apprentissage automatique ou de solutions de BI.
- Mettre en œuvre la gouvernance des données : Établir des politiques de gouvernance des données pour le contrôle d'accès, le chiffrement et l'audit afin d'assurer la qualité, la cohérence et la conformité des données.
Voyons ensuite comment migrer vers un Data Lakehouse si vous disposez d'un système de gestion de données existant.
Étapes pour migrer vers un Data Lakehouse
La migration vers un Data Lakehouse nécessite une approche structurée afin d'éviter les problèmes de dernière minute.
Étape 1 : Analyser les données
L'analyse des données est cruciale pour définir la portée de la migration et identifier les dépendances. Cette étape permet d'avoir une vue d'ensemble de votre environnement et de prioriser vos tâches.
Étape 2 : Préparer les données pour la migration
La préparation des données, y compris les ensembles de données et les colonnes nécessaires, est une étape importante pour optimiser les ressources et le temps lors de la migration.
Étape 3 : Convertir les données au format requis
Il est recommandé d'utiliser des outils de conversion automatique autant que possible, car la conversion des données peut être complexe. Des outils comme Alchimiste peuvent faciliter cette tâche.
Étape 4 : Valider les données après la migration
La validation des données est essentielle après la migration. Il est recommandé d'automatiser ce processus autant que possible afin de garantir le bon fonctionnement des processus métier et des tâches liées aux données.
Principales fonctionnalités d'un Data Lakehouse
🔷 Gestion complète des données : Le Data Lakehouse offre des fonctionnalités de gestion des données telles que le nettoyage, les processus ETL et l'application du schéma, facilitant la préparation des données pour l'analyse et la BI.
🔷 Formats de stockage ouverts : Les données sont enregistrées dans des formats ouverts et standardisés, tels que AVRO, ORC ou Parquet, facilitant le travail avec des données provenant de sources diverses.
🔷 Séparation du stockage et du calcul : Le couplage souple du stockage et du calcul, grâce à des clusters distincts, permet une mise à l'échelle flexible des ressources.
🔷 Prise en charge du streaming de données : Le Data Lakehouse offre la capacité d'ingérer des données en temps réel, ce qui est crucial pour une prise de décision basée sur les données.
🔷 Gouvernance des données : Le Data Lakehouse prend en charge une gouvernance et un audit robustes, essentiels pour maintenir l'intégrité des données.
🔷 Coûts de données réduits : Le coût d'exploitation d'un lac de données est généralement inférieur à celui d'un entrepôt de données, et l'architecture hybride réduit le besoin de maintenir plusieurs systèmes de stockage.
Data Lake, Data Warehouse et Data Lakehouse
| Fonctionnalité | Data Lake | Data Warehouse | Data Lakehouse |
| Stockage de données | Stocke des données brutes ou non structurées | Stocke des données traitées et structurées | Stocke à la fois des données brutes et structurées |
| Schéma de données | N'a pas de schéma fixe | Possède un schéma fixe | Utilise un schéma open source pour les intégrations |
| Transformation des données | Les données ne sont pas transformées | Un ETL étendu est requis | ETL est effectué selon les besoins |
| Conformité ACID | Aucune conformité ACID | ACID -compliant | ACID-Compliant |
| Performance des requêtes | Généralement plus lent car les données sont non structurées | Très rapide en raison des données structurées | Rapide en raison des données semi-structurées |
| Coût | Le stockage est rentable | Coûts de stockage et de requête plus élevés | Le coût du stockage et des requêtes est équilibré |
| Gouvernance des données | Nécessite une gouvernance prudente | Une gouvernance solide est nécessaire | Prend en charge les mesures de gouvernance |
| Analyses en temps réel | Analyses en temps réel limitées | Analyses en temps réel limitées | Prend en charge l'analyse en temps réel |
| Cas d'utilisation | Stockage de données, exploration, ML et IA | Reporting et analyse à l'aide de BI | À la fois l'apprentissage automatique et l'analyse |
Conclusion
En combinant les forces des lacs et des entrepôts de données, le Data Lakehouse répond aux défis de gestion et d'analyse des données. Cette approche permet de travailler avec des données structurées et non structurées sur une plateforme unifiée, offrant des avantages tels que la conformité ACID.
Les étapes décrites dans cet article vous permettent de bénéficier des avantages d'une plateforme de gestion de données unifiée et rentable. En adoptant une approche Data Lakehouse, vous pouvez rester à la pointe de la gestion moderne des données, améliorer la prise de décision, l'analyse et la croissance de votre entreprise.
Consultez notre article détaillé sur la réplication des données pour en savoir plus.