Création d'un entrepôt de données et d'un lac de données dans AWS
Entrepôt de données, lac de données, ou encore une maison au bord d'un lac... Si ces termes ne vous évoquent rien, il y a fort à parier que votre activité professionnelle n'est pas directement liée à la gestion de données.
Toutefois, il serait illusoire d'affirmer cela, car de nos jours, il semble que tout soit connecté aux données. C'est du moins l'idée que les dirigeants d'entreprises aiment mettre en avant, en parlant d'organisations:
- Ciblées sur les données et pilotées par les données.
- Où les données sont accessibles partout, à tout moment et sous toutes les formes.
L'atout le plus précieux
Il est clair que les données sont devenues un atout primordial pour un nombre croissant d'entreprises. Je me souviens qu'autrefois, les grandes entreprises généraient déjà d'énormes volumes de données, avec des téraoctets de nouvelles données produites chaque mois. C'était il y a une quinzaine d'années. Aujourd'hui, de telles quantités de données peuvent être produites en quelques jours. On peut se demander si c'est vraiment utile, même si ce sont des données qui seront largement exploitées. La réponse est non, bien sûr 😃.
Bien évidemment, toutes les données ne seront pas utilisées, et certaines ne serviront même jamais. J'ai souvent été témoin de situations où des entreprises accumulaient d'énormes volumes de données, qui finissaient par être inutiles après un premier chargement réussi.
Cependant, la situation a évolué. Le stockage de données, désormais dans le cloud, est devenu abordable, les sources de données augmentent de manière exponentielle et il est impossible de prévoir aujourd'hui ce dont on aura besoin dans un an, lorsque de nouveaux services seront intégrés au système. Dans ce contexte, même les données les plus anciennes peuvent prendre de la valeur.
Par conséquent, la stratégie adoptée est de stocker autant de données que possible, tout en les organisant de la manière la plus efficace qui soit. Ainsi, les données peuvent non seulement être conservées de manière optimale, mais aussi être interrogées, réutilisées, transformées et distribuées plus facilement.
Examinons trois approches natives pour cela dans AWS :
- Athena : Une solution économique et performante pour créer un lac de données dans le cloud, bien que d'une manière simple.
- Redshift : Une version cloud robuste d'un entrepôt de données, capable de remplacer la plupart des solutions sur site actuelles, qui peinent à suivre la croissance exponentielle des données.
- Databricks : Une combinaison de lac de données et d'entrepôt de données en une seule plateforme, offrant de nombreux avantages supplémentaires.
Lac de données avec AWS Athena
Source : aws.amazon.com
Un lac de données est un environnement où vous pouvez rapidement enregistrer des données brutes, qu'elles soient non structurées, semi-structurées ou structurées. L'idée est que ces données ne soient pas modifiées une fois stockées. Au contraire, elles doivent être aussi atomiques et immuables que possible. C'est la condition sine qua non pour garantir un potentiel maximal de réutilisation ultérieure. La perte de cette propriété atomique dès le premier chargement dans le lac de données serait irrémédiable.
AWS Athena est une base de données qui stocke directement les données sur des compartiments S3, sans aucun cluster de serveurs exécuté en arrière-plan. C'est donc une solution de lac de données très économique. Les formats de fichiers structurés comme Parquet ou CSV permettent de conserver l'organisation des données. Le compartiment S3 contient les fichiers, et Athena s'y réfère chaque fois que des processus extraient des données de la base de données.
Athena ne prend pas en charge certaines fonctionnalités considérées comme standard, comme les instructions de mise à jour. C'est pourquoi il faut considérer Athena comme une solution très simple. Cela dit, cela vous permet d'éviter de modifier accidentellement votre lac de données atomique, simplement parce que vous ne le pouvez pas 😐.
Athena gère l'indexation et le partitionnement, ce qui permet d'exécuter efficacement les requêtes de sélection et de créer des blocs de données logiquement distincts (par exemple, par colonne de date ou par clé). De plus, son évolutivité horizontale est très simple, car il suffit d'ajouter de nouveaux compartiments à l'infrastructure.

Avantages et inconvénients
Voici les avantages à retenir :
- Le coût est sans doute l'avantage majeur d'Athena : il est très économique (basé uniquement sur les coûts des compartiments S3 et sur la consommation SQL). Si vous cherchez à créer un lac de données abordable dans AWS, c'est la solution idéale.
- En tant que service natif, Athena s'intègre facilement avec d'autres services AWS intéressants, comme Amazon QuickSight pour la visualisation des données, ou AWS Glue Data Catalog pour créer des métadonnées structurées persistantes.
- C'est une solution idéale pour effectuer des requêtes ad hoc sur de grands volumes de données structurées ou non structurées, sans avoir à maintenir une infrastructure complète.
Voici les inconvénients à prendre en compte :
- Athena n'est pas particulièrement performant pour répondre rapidement à des requêtes de sélection complexes, en particulier si les requêtes ne respectent pas les hypothèses du modèle de données et la manière dont les données du lac de données ont été conçues pour être interrogées.
- Cela la rend également moins flexible face aux changements potentiels du modèle de données.
- Athena n'offre pas de fonctionnalités avancées supplémentaires prêtes à l'emploi. Si vous avez besoin d'une fonction spécifique dans le service, vous devez l'implémenter en plus.
- Si les données du lac de données sont destinées à être utilisées dans une couche de présentation plus avancée, le seul choix est souvent de la combiner avec un autre service de base de données plus adapté, comme AWS Aurora ou AWS Dynamo DB.
Objectif et cas d'utilisation réel
Choisissez Athena si votre objectif est de créer un lac de données simple, sans fonctionnalités avancées de type entrepôt de données. Par exemple, si vous n'avez pas besoin d'exécuter régulièrement des requêtes analytiques complexes et performantes sur le lac de données, et que vous souhaitez plutôt disposer d'un ensemble de données immuables, avec une facilité d'extension du stockage.
Vous n'avez plus à vous soucier du manque d'espace. De plus, le coût du stockage des compartiments S3 peut être encore réduit en mettant en œuvre une politique de cycle de vie des données, qui consiste à transférer les données entre différents types de compartiments S3, plus adaptés à des fins d'archivage, avec des temps de récupération plus longs mais des coûts inférieurs.
Une fonctionnalité intéressante d'Athena est qu'elle crée automatiquement un fichier contenant les données issues du résultat d'une requête SQL. Vous pouvez ensuite utiliser ce fichier comme bon vous semble. C'est donc une option intéressante si vous avez de nombreux services lambda qui traitent les données en plusieurs étapes. Chaque résultat lambda sera automatiquement disponible sous forme de fichier structuré, prêt pour un traitement ultérieur.
Athena est un bon choix lorsque de grands volumes de données brutes arrivent dans votre infrastructure cloud, sans que vous ayez besoin de les traiter au moment du chargement. Dans ce cas, vous avez juste besoin d'un espace de stockage rapide dans le cloud, avec une structure facile à comprendre.
Un autre cas d'utilisation serait de créer un espace dédié à l'archivage de données pour un autre service. Dans ce cas, Athena DB deviendrait un emplacement de sauvegarde économique pour toutes les données qui ne sont pas nécessaires dans l'immédiat, mais qui pourraient le devenir à l'avenir. À ce stade, vous vous contenterez de récupérer les données et de les envoyer plus loin.
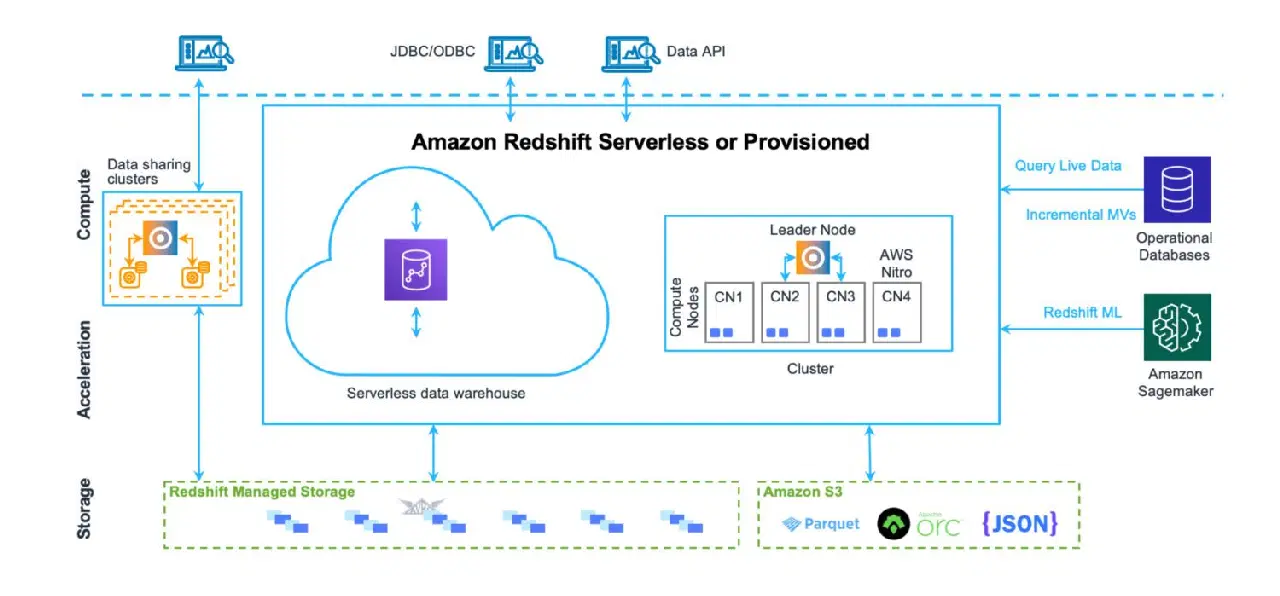
Entrepôt de données avec AWS Redshift
 Source : aws.amazon.com
Source : aws.amazon.com
Un entrepôt de données est un endroit où les données sont stockées de manière très structurée. Elles sont faciles à charger et à extraire. L'objectif est d'exécuter un grand nombre de requêtes complexes, en joignant de nombreuses tables via des jointures complexes. Différentes fonctions analytiques permettent de calculer des statistiques sur les données existantes. L'objectif ultime est d'extraire des prédictions et des tendances pour l'entreprise, en exploitant les données existantes.
Redshift est un système d'entrepôt de données complet. Il est doté de serveurs de cluster à configurer et à mettre à l'échelle (horizontalement et verticalement), ainsi que d'un système de stockage de base de données optimisé pour des retours rapides de requêtes complexes. Toutefois, il est désormais possible d'exécuter Redshift en mode sans serveur. Il n'y a pas de fichiers sur S3 ou de systèmes similaires. Il s'agit d'un serveur de cluster de base de données standard, avec son propre format de stockage.
Redshift offre des outils de surveillance des performances prêts à l'emploi, ainsi que des métriques de tableau de bord personnalisables, que vous pouvez utiliser pour ajuster les performances de votre cas d'utilisation. L'administration est également accessible via des tableaux de bord séparés. Il faut un certain effort pour comprendre toutes les fonctionnalités et tous les paramètres possibles, et leur impact sur le cluster. Cela dit, cela reste bien moins compliqué que l'administration de serveurs Oracle pour les solutions sur site.
Bien qu'il existe certaines limites AWS dans Redshift qui restreignent son utilisation quotidienne (par exemple, des limites strictes sur le nombre d'utilisateurs ou de sessions actifs simultanés dans un cluster de base de données), la rapidité d'exécution des opérations permet de contourner ces limites dans une certaine mesure.

Avantages et inconvénients
Voici les avantages à considérer :
- Redshift est un service d'entrepôt de données cloud AWS natif, facile à intégrer avec d'autres services.
- Il centralise le stockage, la surveillance et l'ingestion de différents types de sources de données provenant de systèmes sources très variés.
- Si vous avez toujours rêvé d'un entrepôt de données sans serveur, sans l'infrastructure à maintenir, c'est désormais possible.
- Il est optimisé pour des analyses et des rapports hautes performances. Contrairement aux solutions de lac de données, il utilise un modèle de données relationnelles robuste pour stocker toutes les données entrantes.
- Le moteur de base de données Redshift est basé sur PostgreSQL, ce qui garantit une compatibilité élevée avec d'autres systèmes de base de données.
- Les instructions COPY et UNLOAD sont très utiles pour charger et décharger les données depuis et vers les compartiments S3.
Voici les inconvénients à prendre en compte :
- Redshift ne prend pas en charge un grand nombre de sessions actives simultanées. Les sessions sont mises en attente et traitées séquentiellement. Même si ce n'est généralement pas un problème, étant donné la rapidité des opérations, c'est un facteur limitant pour les systèmes avec de nombreux utilisateurs actifs.
- Même si Redshift propose de nombreuses fonctionnalités auparavant connues dans les systèmes Oracle, il n'est toujours pas au même niveau. Certaines fonctionnalités attendues pourraient être absentes (comme les déclencheurs DB), ou Redshift les prend en charge sous une forme assez limitée (comme les vues matérialisées).
- Chaque fois qu'une tâche de traitement de données personnalisée plus avancée est nécessaire, vous devez la créer de zéro, généralement en utilisant Python ou Javascript. Ce n'est pas aussi intuitif que PL/SQL dans le système Oracle, où les fonctions et les procédures utilisent un langage très proche des requêtes SQL.
Objectif et cas d'utilisation réel
Redshift peut devenir votre entrepôt central pour toutes les sources de données qui existaient auparavant en dehors du cloud. C'est une alternative valable aux anciennes solutions d'entrepôt de données Oracle. Puisqu'il s'agit également d'une base de données relationnelle, la migration depuis Oracle est une opération assez simple.
Si vous disposez de solutions d'entrepôt de données réparties à différents endroits, sans approche ni structure unifiée, et sans processus communs définis, Redshift est un excellent choix.
Cela vous permettra de regrouper tous les systèmes d'entrepôt de données provenant de différents lieux et pays sous un même toit. Vous pouvez toujours les séparer par pays, afin que les données restent sécurisées et accessibles uniquement aux personnes qui en ont besoin. En même temps, vous pourrez mettre en place une solution d'entrepôt unifiée, qui couvre toutes les données de l'entreprise.
Un autre scénario pourrait être la création d'une plateforme d'entrepôt de données avec une prise en charge étendue du libre-service, c'est-à-dire la possibilité pour les utilisateurs de créer leurs propres traitements, qui ne font pas partie de la solution commune. Ainsi, ces services resteront accessibles uniquement au créateur ou au groupe défini par le créateur, sans affecter les autres utilisateurs.
Consultez notre comparatif entre Datalake et Datawarehouse.
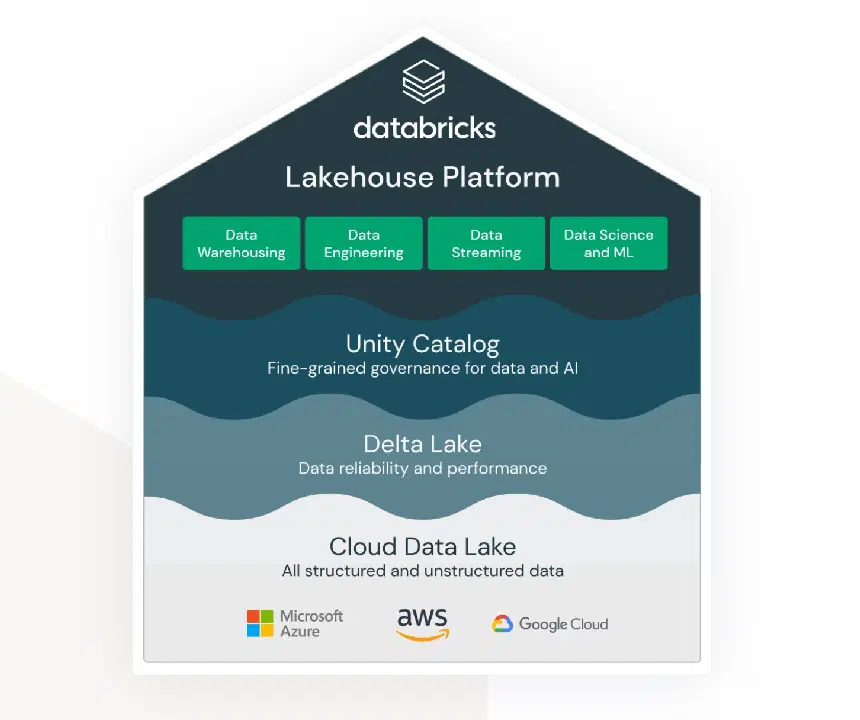
Lakehouse avec Databricks sur AWS
 Source : databricks.com
Source : databricks.com
Le terme Lakehouse est étroitement lié au service Databricks. Bien qu'il ne s'agisse pas d'un service AWS natif, il fonctionne très bien au sein de l'écosystème AWS et propose différentes options pour se connecter et s'intégrer avec d'autres services AWS.
Databricks vise à connecter des domaines qui étaient auparavant très distincts :
- Une solution de stockage de lac de données pour les données non structurées, semi-structurées et structurées.
- Une solution d'entrepôt de données pour les données structurées, qui sont accessibles rapidement (également appelé Delta Lake).
- Une solution de prise en charge de l'analyse et de l'apprentissage automatique sur le lac de données.
- La gouvernance des données pour tous les domaines ci-dessus, avec une administration centralisée et des outils prêts à l'emploi pour faciliter la productivité de différents types de développeurs et d'utilisateurs.
Il s'agit d'une plateforme commune que les ingénieurs de données, les développeurs SQL et les spécialistes des données en apprentissage automatique peuvent utiliser simultanément. Chacun de ces groupes dispose également d'un ensemble d'outils qui lui permettent d'effectuer ses tâches.
Databricks cherche donc à proposer une solution polyvalente, qui combine les avantages du lac de données et de l'entrepôt de données en une seule plateforme. De plus, il fournit les outils pour tester et exécuter des modèles d'apprentissage automatique directement sur les magasins de données déjà construits.

Avantages et inconvénients
Voici les avantages à considérer :
- Databricks est une plateforme de données très évolutive. Elle s'adapte à la taille de la charge de travail, et peut le faire automatiquement.
- C'est un environnement collaboratif pour les scientifiques des données, les ingénieurs de données et les analystes métiers. La possibilité de faire tout cela au même endroit et ensemble est un avantage considérable, non seulement d'un point de vue organisationnel, mais aussi en termes d'économies sur les coûts liés à des environnements séparés.
- AWS Databricks s'intègre de manière fluide avec d'autres services AWS, comme Amazon S3, Amazon Redshift et Amazon EMR. Cela permet aux utilisateurs de transférer facilement les données entre les différents services et de tirer pleinement profit de la gamme de services cloud AWS.
Voici les inconvénients à prendre en compte :
- Databricks peut être complexe à configurer et à gérer, en particulier pour les utilisateurs qui débutent dans le traitement du Big Data. Cela nécessite un niveau d'expertise technique important pour tirer pleinement parti de la plateforme.
- Bien que Databricks soit rentable en termes de modèle de tarification à la demande, son coût peut rapidement devenir élevé pour les projets de traitement de données à grande échelle. Le coût d'utilisation de la plateforme peut vite s'accumuler, surtout si les utilisateurs ont besoin d'augmenter leurs ressources.
- Databricks fournit une variété d'outils et de modèles prédéfinis, mais cela peut aussi être une limitation pour les utilisateurs qui ont besoin de plus d'options de personnalisation. La plateforme peut ne pas convenir aux utilisateurs qui ont besoin de plus de flexibilité et de contrôle sur leurs workflows de traitement de données volumineuses.
Objectif et cas d'utilisation réel
AWS Databricks est particulièrement adapté aux grandes entreprises avec de très grands volumes de données. Il peut prendre en charge le chargement et la contextualisation de sources de données variées provenant de différents systèmes externes.
Souvent, l'objectif est de fournir des données en temps réel. Cela signifie que dès que les données apparaissent dans le système source, les processus doivent immédiatement récupérer, traiter et stocker les données dans Databricks instantanément ou avec un délai minimal. Si le délai dépasse une minute, on parle de traitement en temps quasi réel. Dans tous les cas, les deux scénarios sont généralement réalisables avec la plateforme Databricks. Ceci est principalement dû au grand nombre d'adaptateurs et d'interfaces en temps réel qui se connectent avec différents services AWS natifs.
Databricks s'intègre également facilement avec les systèmes ETL d'Informatica. Si votre organisation utilise déjà largement l'écosystème Informatica, Databricks sera un complément compatible et adapté à votre plateforme.
Mots de la fin
Alors que le volume de données continue de croître de manière exponentielle, il est bon de savoir qu'il existe des solutions qui peuvent y faire face efficacement. Ce qui était autrefois un cauchemar à administrer et à maintenir nécessite désormais très peu de travail administratif. L'équipe peut se concentrer sur la création de valeur à partir des données.
En fonction de vos besoins, il vous suffit de choisir le service qui y répond le mieux. Alors qu'AWS Databricks est une solution que vous devrez probablement adopter une fois la décision prise, les autres alternatives sont beaucoup plus flexibles, même si elles sont moins performantes, en particulier en mode sans serveur. Il est assez facile de migrer vers une autre solution par la suite.