Comprendre les terminologies de reprise après sinistre - RTO, RPO, basculement, BCP, etc.
L'élaboration d'un plan de continuité d'activité est une étape cruciale que toute organisation doit franchir afin de se prémunir contre les conséquences d'un événement imprévu.
Dans le secteur informatique, cette démarche commence par la création d'un document formel décrivant les plans, les actions et les procédures à mettre en œuvre pour faire face à une catastrophe et à ses suites.
Une catastrophe est un événement soudain et inattendu qui peut revêtir différentes formes. Lorsqu'elle survient, les individus et les organisations sont confrontés à des défis multiples, notamment des problèmes financiers et des perturbations de l'expérience utilisateur.
En cas d'incident, il est essentiel d'être préparé afin de minimiser ses impacts et de restaurer rapidement les opérations. C'est là qu'un plan de reprise après sinistre bien conçu joue un rôle clé pour atténuer, voire prévenir la catastrophe. Il permet également de limiter ses répercussions en termes d'expérience utilisateur, de coûts et de temps d'arrêt.
Il est également crucial de maintenir vos plans, votre personnel, vos stratégies, votre matériel et vos systèmes prêts à reprendre leurs activités. Cependant, pour ce faire, une compréhension approfondie de la reprise après sinistre est indispensable.
Cet article se propose d'explorer en détail ce concept ainsi que les principales terminologies associées, afin que vous puissiez réagir efficacement et émerger renforcé face à de telles situations défavorables.
C'est parti !
Qu'est-ce qu'une catastrophe ?
Une catastrophe est un événement imprévu qui peut survenir n'importe où, y compris dans le domaine de l'informatique. Elle peut être d'origine naturelle ou humaine et perturber le fonctionnement d'une entreprise et affecter son infrastructure.
Par conséquent, une organisation ainsi que ses clients, fournisseurs, employés et partenaires en subissent les conséquences. Cela met une pression sur l'organisation en termes de finances, d'image, de confiance de la clientèle et de sécurité.
Il est donc impératif de se préparer à l'avance pour surmonter de tels scénarios. Cela implique de rétablir rapidement toutes les opérations et données. En d'autres termes, vous devez préparer votre organisation à une récupération rapide et efficace pour vos clients.
Les catastrophes peuvent prendre différentes formes, telles que les cyberattaques, le sabotage, les attentats terroristes, les rançongiciels ou les menaces physiques, les ouragans, les tremblements de terre, les incendies, les inondations, les accidents industriels, les pannes de courant et bien d'autres encore.
Qu'entend-on par reprise après sinistre ?
La reprise après sinistre est le processus visant à restaurer les opérations normales après un sinistre. Cela implique de rétablir l'accès au matériel, aux logiciels, à l'équipement, à la connectivité, au réseau, à l'alimentation et aux données. Il est nécessaire de définir des règles et des procédures dans un processus documenté afin de préparer votre organisation en amont d'un éventuel sinistre.
Cependant, si les installations de votre organisation sont détruites, il est crucial de prendre en compte d'autres aspects tels que la communication, le transport, l'approvisionnement et les lieux de travail.
Pourquoi un plan de reprise après sinistre est-il important ?
L'élaboration d'un plan de reprise après sinistre efficace, qu'il soit d'origine naturelle ou humaine, est fondamentale pour toute entreprise du secteur informatique. Assurez-vous d'avoir les bonnes personnes et les bons outils à portée de main pour mettre en œuvre ce plan.
Voyons plus en détail pourquoi la reprise après sinistre revêt une importance cruciale.
Limiter les dégâts
Une catastrophe est par nature imprévisible. Personne ne peut prévoir quand elle se produira. Cependant, en vous préparant à l'avance, vous pouvez mieux maîtriser les dommages causés à votre infrastructure.
Par exemple, dans les zones inondables, vous pouvez stocker vos documents et équipements essentiels aux étages supérieurs pour éviter qu'ils ne soient endommagés.
De même, il est essentiel de sauvegarder vos données importantes avant que des cyberattaques ne puissent les compromettre ou les voler.
Restaurer les services
Si vous avez mis en place un plan solide pour faire face à une catastrophe, la restauration de tous les services à leur état normal sera plus simple et rapide. Cela signifie que vous pourrez récupérer rapidement la plupart de vos actifs et services clés.
Minimiser les interruptions
Il est impossible de prévoir l'avenir et les conséquences d'une opération. Cependant, avec un plan de reprise après sinistre bien défini, vous n'aurez pas à vous inquiéter outre mesure. Votre infrastructure pourra continuer à fonctionner avec un minimum d'interruptions.
Formation et préparation

Une infrastructure informatique comprend de nombreux employés travaillant ensemble. Il est important que chacun soit informé des procédures de reprise afin de pouvoir agir rapidement et efficacement en cas d'urgence.
Une bonne préparation permettra de réduire le stress de toutes les personnes impliquées dans votre organisation. De plus, vous pouvez former vos employés à adopter les mesures nécessaires en cas d'événement imprévu.
Terminologies de reprise après sinistre
Commençons par examiner les terminologies clés pour mieux comprendre la reprise après sinistre.
RTO
L'objectif de temps de récupération (RTO) est la durée maximale qu'une organisation se fixe pour tolérer une interruption due à une catastrophe sans que cela n'affecte sa croissance financière.
Lors de la définition du RTO, une entreprise doit évaluer les temps d'arrêt qui pourraient impacter son activité de différentes manières. Il sert de base à l'élaboration de stratégies viables pour assurer la continuité des opérations même après une catastrophe. Lorsque les clients rencontrent des interruptions de service, ils veulent savoir combien de temps il faudra pour que l'application soit de nouveau opérationnelle. Le RTO est la réponse à cette question pour chaque organisation.
Exemple : Prenons l'exemple d'une société de transactions en ligne comme PayPal ou Pioneer qui serait confrontée à des événements imprévisibles. Dans ce cas, son RTO sera très court afin de rétablir rapidement les opérations.
En d'autres termes, une entreprise peut définir un RTO d'une heure ou deux pour éviter des pertes financières ou de données.
RPO
Les objectifs de point de récupération (RPO) correspondent à la quantité de perte de données qu'une infrastructure informatique peut gérer en termes de temps et de volume d'informations.
Cela semble confus ?
Prenons l'exemple d'une base de données qui enregistre les transactions d'une banque, notamment les transferts, les planifications et les paiements. En cas de sinistre, la base de données est restaurée en temps réel. Dans ce cas, il n'y aura aucune différence entre la base de données au moment du sinistre et celle restaurée après le sinistre.
Pour certaines entreprises, il est acceptable d'attendre 24 heures pour récupérer toutes les informations à partir de la sauvegarde, mais cela peut parfois être catastrophique. Il est essentiel de configurer votre infrastructure en fonction de vos exigences RPO. Cela peut inclure l'augmentation de la fréquence des sauvegardes, l'ajout d'une base de données de secours à votre architecture, etc.
Basculement
Imaginez que vous conduisiez sur une longue distance et que vous ayez soudainement une crevaison. Vous êtes soulagé de pouvoir compter sur une roue de secours et les outils pour changer la roue endommagée.
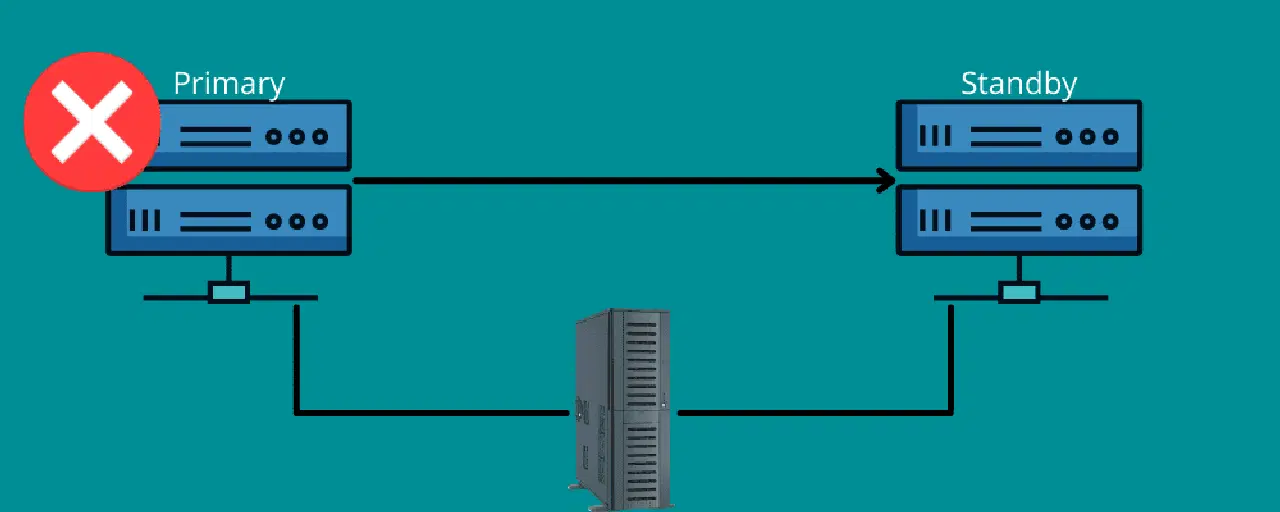
Le basculement fonctionne de la même manière.
Cela signifie que vous avez besoin d'une connexion de secours en cas de catastrophe. Autrement dit, le basculement consiste à disposer de réseaux et de systèmes que vous pouvez utiliser en cas de sinistre pour transférer vos informations vers le système de récupération.
Le basculement assure le bon fonctionnement de tous vos services, même en cas de défaillance de l'infrastructure ou du matériel. Ainsi, vous évitez que votre organisation ne perde des données et des revenus, et vous réduisez les interruptions de service pour vos utilisateurs.
Vous pouvez configurer le basculement manuellement ou l'automatiser pour que les données soient transférées vers le serveur de secours.
Rétablissement
Le rétablissement informatique est une opération simple qui consiste à ramener la production d'origine vers son emplacement initial (système) après un sinistre. Pendant une attaque, les entreprises mettent en œuvre un basculement, ce qui permet de transférer toutes les charges de travail vers une réplique de machine virtuelle ou un système de sauvegarde.
Cependant, il ne suffit pas de passer à l'étape suivante. Lorsque vous avez récupéré tous vos éléments et que vous reprenez vos activités, vous devez transférer toutes les charges de travail vers leurs machines virtuelles ou systèmes d'origine. Ce processus global de retour des charges de travail vers le lieu de travail ou le système d'origine est appelé rétablissement. En d'autres termes, vous revenez à votre état normal après l'attaque.
Le rétablissement est également utilisé pour la maintenance planifiée d'une entreprise. Il est important de noter que le rétablissement intervient toujours après un basculement. En effet, le basculement est la première étape et le rétablissement est la deuxième étape de la récupération des données essentielles. Il peut être configuré de cloud à cloud, sur site à sur site, sur site à cloud ou toute combinaison de ces options.
RD
La reprise après sinistre (DR) est le processus par lequel vous mettez en œuvre des plans préétablis pour récupérer vos actifs dans les délais fixés.
La DR permet à une organisation de réagir rapidement et de restaurer chaque service à la suite d'un événement inattendu. Elle inclut également une documentation formelle contenant des instructions sur les mesures immédiates à prendre en cas d'incident imprévu.
PCA
Le plan de continuité des activités (PCA) est un des plans de reprise après sinistre les plus largement acceptés. Il permet à l'infrastructure informatique de mettre en place des stratégies pour gérer les interruptions informatiques des serveurs, des appareils mobiles, des ordinateurs personnels et des réseaux.
Le PCA diffère légèrement de la reprise après sinistre dans la mesure où il aide une organisation à planifier le rétablissement des logiciels d'entreprise et de la productivité afin de répondre aux besoins fondamentaux de l'entreprise.
Dans ce contexte, une entreprise crée un système de récupération pour surmonter les menaces potentielles telles que les cyberattaques ou les catastrophes naturelles. Son objectif est de protéger les actifs et de garantir que tous les services seront à nouveau opérationnels rapidement après un incident.
BCM

La gestion de la continuité des activités (BCM) est un processus de gestion des risques spécialement conçu pour agir comme un bouclier contre les menaces pesant sur les processus commerciaux. La BCM est la prochaine étape après le PCA. Elle valide les plans de reprise pour s'assurer que tous les employés de l'entreprise respectent le plan et récupèrent tous les éléments essentiels.
La BCM agit comme un cadre de gestion pour identifier les risques d'infrastructure face à des menaces externes et/ou internes. Elle permet également de s'assurer que ce cadre fonctionne efficacement grâce à des tests réguliers afin d'améliorer la prévisibilité, de réduire les risques et d'adapter le plan aux attaques futures.
BIA
L'analyse d'impact sur l'entreprise (BIA) est un processus permettant d'évaluer la capacité de survie d'une entreprise en identifiant les systèmes, opérations et processus critiques. Elle permet d'évaluer l'impact d'une catastrophe sur votre organisation en raison des interruptions de vos opérations.
La BIA permet d'anticiper les conséquences avant une éventuelle attaque afin de recueillir des informations clés susceptibles d'aider à élaborer des stratégies de récupération efficaces. Elle identifie également les coûts associés aux pannes, tels que les frais de remplacement du matériel, les pertes de trésorerie, de bénéfices et de salaires.
Lors de la création d'un rapport BIA, il est important de prendre en compte les processus critiques impliqués dans votre entreprise, l'impact des perturbations sur différents domaines, la durée acceptable, les domaines tolérables et les coûts financiers.
Arbre d'appel
Un arbre d'appel est un processus consistant à tenir une liste d'employés à contacter en cas d'urgence. C'est une procédure qui suit une structure arborescente.
Par exemple, lors d'une catastrophe, une personne contactera un petit groupe de collaborateurs avec un message urgent, et ces collaborateurs contacteront chaque groupe séparément. De cette manière, l'ensemble du personnel sera informé de la menace et commencera à exécuter ses tâches assignées afin de rétablir chaque fonction et chaque processus dans les délais prévus. La création d'une liste est simple, mais sa mise en œuvre en temps réel peut engendrer une confusion.
Il est essentiel de réaliser régulièrement des exercices d'appel afin de préparer chaque employé à rester vigilant. Des tests réguliers permettent également d'identifier les numéros modifiés ou manquants, ce qui peut avoir un impact majeur sur la performance.
Un arbre d'appel contient les informations nécessaires à la transmission d'instructions en cas d'urgence. Si cette opération peut être effectuée manuellement, l'automatisation permet d'accélérer le processus et d'informer les membres dans le monde numérique d'aujourd'hui.
Centre de commandement/Centre de contrôle
Il s'agit d'une installation virtuelle ou physique spécialement conçue pour assurer le commandement ou le contrôle des plans de reprise en cas de crise. Elle communique avec l'équipe pour gérer les systèmes et les fonctions pendant une catastrophe.
Traditionnellement, l'infrastructure dépendait d'un centre de commandement qui gérait les crises sans méthode adaptée. De nos jours, les organisations ont perfectionné leur centre de contrôle, transformant ainsi la réponse immédiate en une compétence essentielle.
Dès qu'il détecte une catastrophe, le centre de commandement passe rapidement à la phase de récupération. Il sert également de point de contact pour les services, la presse, les livraisons, etc. Il réunit également des personnes de différentes disciplines dans de telles situations.
Réponse aux incidents

La réponse aux incidents est un type de réaction adoptée pour faire face à une attaque. Elle est mise en œuvre grâce à des procédures et un personnel appropriés, afin de protéger efficacement la sécurité du réseau et des données au moment opportun.
Si une organisation dispose d'un plan de gestion des incidents avant qu'un événement inattendu ne survienne, elle peut protéger ses données contre les menaces en temps réel. Les spécialistes de la réponse aux incidents restent attentifs aux problèmes et réagissent de manière naturelle lors d'un incident. Ils mettent en œuvre des mesures pour éviter les failles de sécurité en veillant à ne pas omettre d'étape pendant la reprise après sinistre.
Dans un premier temps, il est crucial d'identifier les données critiques et de les stocker dans le cloud ou dans un emplacement distant afin d'assurer leur sécurité. Il est également important d'adapter les plans de réponse aux incidents en fonction des besoins actuels de l'infrastructure et de l'évolution des menaces cybernétiques.
Sauvegarde
Les solutions de sauvegarde permettent à une infrastructure informatique de conserver des copies des données et de les stocker en toute sécurité au bon moment. En cas de corruption de la base de données, de suppression accidentelle de toutes les données ou de tout autre problème, la sauvegarde est un élément clé qui permet de restaurer les données rapidement et de poursuivre les activités.

Il s'agit de répliquer les fichiers et de les stocker dans un emplacement sécurisé afin d'accéder facilement à toutes les données après un événement imprévu. Il est conseillé de sauvegarder vos données à plusieurs endroits afin de pouvoir les restaurer même en cas de défaillance d'un site.
Résilience
La capacité des communautés, des États, des organisations et des individus à résister à une catastrophe sans compromettre les services et les systèmes est appelée résilience aux catastrophes.
Une organisation doit être prête à supporter une grande quantité de stress dû aux dangers. Au lieu d'attendre qu'une aide extérieure arrive, vous devez vous assurer que vous disposez des capacités nécessaires pour minimiser vos pertes grâce à une meilleure planification. Cela vous permettra de faire face aux catastrophes et de récupérer efficacement votre infrastructure informatique.
L'objectif principal est ici de préserver et de restaurer les fonctions et les structures essentielles au moment opportun. Pour devenir une organisation résiliente face aux catastrophes, il est indispensable de se préparer à l'avance et de pouvoir anticiper les risques, s'adapter aux changements, partager et apprendre, intégrer divers secteurs et gérer les niveaux de risque.
SLA

L'accord de niveau de service (SLA) est un plan d'urgence dans lequel vous indiquez aux utilisateurs finaux le temps que vous mettrez à rétablir les services en cas d'urgence.
Le SLA garantit aux clients que leurs données sont en sécurité et ne sont pas compromises ni partagées avec des tiers. Il s'agit du point de contact unique pour les problèmes des utilisateurs finaux.
Chaque infrastructure informatique fournit à ses clients un SLA. Il est donc important d'informer vos utilisateurs en amont.
SPOF
Un point de défaillance unique (SPOF) est un équipement, une personne, une ressource ou une application auquel sont connectés de nombreux autres systèmes ou applications.
Si un tel équipement ou ressource tombe en panne, toutes les parties essentielles connectées au système tombent en panne également. Par conséquent, l'ensemble du processus et du fonctionnement de l'entreprise seront affectés.
Il est donc indispensable d'avoir une stratégie pour faire face à un tel problème et assurer la continuité des activités de votre organisation. La première étape consiste à identifier l'équipement ou le système qui pourrait avoir l'impact le plus important. Ensuite, il est conseillé de réaliser une analyse d'impact sur l'entreprise et d'obtenir un score d'évaluation des risques afin d'être informé des scénarios potentiels. Examinez la situation en profondeur pour les identifier avant qu'un événement ne survienne.
Une fois que vous avez dressé la liste de tous les SPOF, classez-les en fonction de leur processus de récupération. Répartissez-les en trois catégories différentes :
- Ceux qui peuvent être récupérés facilement et rapidement avec un minimum de temps et de budget.
- Ceux dont la récupération serait difficile, mais pour lesquels un processus fiable pourrait être mis en place.
- Ceux qui ne peuvent pas être récupérés une fois qu'ils tombent en panne.
Vous pouvez ensuite agir en conséquence en fonction de la catégorie.
Récupération du système
En cas de défaillance matérielle, vous devez lancer un processus de récupération pour ramener le système ou le serveur concerné à son état initial. Pour récupérer l'ensemble du système, il est nécessaire de prévoir les éléments nécessaires à la récupération, les sauvegardes, la compatibilité du micrologiciel et la compatibilité matérielle.
La récupération du système est un processus qui permet de réinitialiser la machine à ses paramètres initiaux ou à l'état dans lequel elle se trouvait lors de sa première utilisation. Cela permettra de supprimer toute infection virale due à des logiciels ou des applications installés sur votre système.
Ce processus inclut la planification de la reprise d'une infrastructure informatique, qui définit et respecte des procédures spécifiques afin de garantir la disponibilité des données en cas d'interruptions d'origine humaine ou naturelle.
Restauration du système
La restauration du système est un outil de récupération qui permet de rétablir certains fichiers et informations à leur état antérieur au moment opportun.
Grâce à la restauration du système, vous pouvez récupérer les clés de registre, les programmes installés, les pilotes et les fichiers système dans leur version précédente. Il s'agit d'une bouée de sauvetage en cas de catastrophe.
Plan de test
Le plan de test est un document qui contient des informations sur une stratégie de test, des estimations, des ressources, des délais, des objectifs et des calendriers. Il sert de modèle pour exécuter des tests afin d'assurer la sécurité du matériel et des logiciels.
Il comprend différents tests en fonction des procédures et des étapes prévues pour gérer les conséquences d'un sinistre. Réalisez des tests réguliers afin de vous préparer, ainsi que votre organisation, à ne pas omettre d'étape en cas de problème. De cette manière, une infrastructure informatique pourra identifier ses points faibles et se préparer au combat.
Conclusion
Personne ne sait quand une catastrophe se produira. C'est pourquoi des mesures de sûreté et de sécurité adéquates sont essentielles pour chaque entreprise.
Les terminologies de reprise après sinistre vous aideront à comprendre comment réagir aux attaques et aux catastrophes. Elles vous permettront également de vous préparer à l'avance afin de protéger votre infrastructure en cas d'événement inattendu. Vous serez ainsi en mesure de mettre en place une stratégie de reprise après sinistre efficace et en temps réel, ce qui vous permettra d'économiser des sommes importantes et de préserver la confiance de vos clients.