

Votre ordinateur Linux ou macOS utilise la mémoire virtuelle. Découvrez comment cela affecte l’utilisation par votre système de la mémoire physique, du processeur et des ressources du disque dur.
Table des matières
Qu’est-ce que la mémoire virtuelle?
Votre ordinateur est équipé d’une quantité limitée de mémoire physique appelée mémoire vive (RAM). Cette RAM doit être gérée par le noyau et partagée entre le système d’exploitation et toutes les applications en cours d’exécution. Si ces demandes combinées demandent plus de mémoire que celle installée physiquement sur votre ordinateur, que peut faire le noyau?
Les systèmes d’exploitation de type Linux et Unix tels que macOS peuvent utiliser de l’espace sur votre disque dur pour les aider à gérer les demandes de mémoire. Une zone réservée d’espace disque dur appelée «espace de swap» peut être utilisée comme s’il s’agissait d’une extension de RAM. C’est de la mémoire virtuelle.
Le noyau Linux peut écrire le contenu d’un bloc de mémoire dans l’espace de swap, et libérer cette région de RAM pour une utilisation par un autre processus. La mémoire échangée – également appelée «sortie paginée» – peut être récupérée de l’espace d’échange et restaurée dans la RAM lorsque cela est nécessaire.
Bien entendu, la vitesse d’accès à la mémoire paginée est plus lente que celle de la mémoire stockée dans la RAM. Et ce n’est pas le seul compromis. Alors que la mémoire virtuelle fournit un moyen pour Linux de gérer ses demandes de mémoire, l’utilisation de la mémoire virtuelle impose une charge accrue ailleurs sur l’ordinateur.
Votre disque dur doit effectuer plus de lectures et d’écritures. Le noyau – et par conséquent, le processeur – doit faire plus de travail car il échange de la mémoire, échange de la mémoire et maintient toutes les plaques en rotation pour satisfaire les besoins en mémoire des différents processus.
Linux vous permet de surveiller toute cette activité sous la forme de la commande vmstat, qui rend compte statistiques de la mémoire virtuelle.
La commande vmstat
Si vous tapez vmstat comme commande sans paramètres, il vous montrera un ensemble de valeurs. Ces valeurs sont les moyennes de chacune des statistiques depuis le dernier redémarrage de votre ordinateur. Ces chiffres ne sont pas un aperçu des valeurs «pour le moment».
vmstat

Un court tableau de valeurs s’affiche.
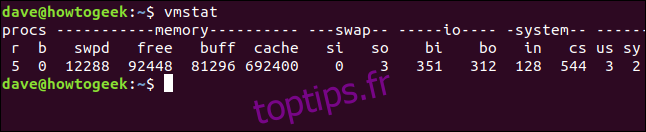
Il y a des colonnes intitulées Procs, Memory, Swap, IO, System et CPU. La dernière colonne (la plus à droite) contient les données relatives à la CPU.
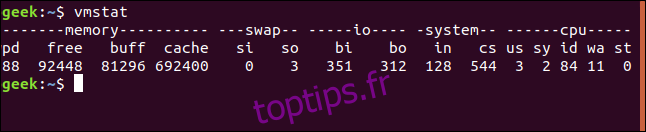
Voici une liste des éléments de données dans chaque colonne.
Proc
r: Le nombre de processus exécutables. Ce sont des processus qui ont été lancés et qui sont en cours d’exécution ou qui attendent leur prochaine rafale de cycles CPU.
b: Le nombre de processus en veille ininterrompue. Le processus ne se met pas en veille, il exécute un appel système bloquant et ne peut pas être interrompu tant qu’il n’a pas terminé son action en cours. En règle générale, le processus est un pilote de périphérique qui attend que certaines ressources soient gratuites. Toutes les interruptions en file d’attente pour ce processus sont gérées lorsque le processus reprend son activité habituelle.
Mémoire
swpd: la quantité de mémoire virtuelle utilisée. En d’autres termes, combien de mémoire a été échangée.,
free: la quantité de mémoire inactive (actuellement inutilisée).
buff: la quantité de mémoire utilisée comme tampons.
cache: la quantité de mémoire utilisée comme cache.
Échanger
si: quantité de mémoire virtuelle permutée à partir de l’espace d’échange.
donc: quantité de mémoire virtuelle échangée vers l’espace d’échange.
IO
bi: Blocs reçus d’un périphérique bloc. Le nombre de blocs de données utilisés pour replacer la mémoire virtuelle en RAM.
bo: Blocs envoyés à un périphérique bloc. Le nombre de blocs de données utilisés pour échanger la mémoire virtuelle hors de la RAM et dans l’espace d’échange.
Système
in: Le nombre d’interruptions par seconde, horloge comprise.
cs: le nombre de changements de contexte par seconde. Un changement de contexte se produit lorsque le noyau passe du traitement en mode système au traitement en mode utilisateur.
CPU
Ces valeurs sont tous des pourcentages du temps CPU total.
us: Temps passé à exécuter du code non-noyau. Autrement dit, combien de temps est passé dans le traitement du temps utilisateur et dans le traitement en temps opportun.
sy: Temps passé à exécuter le code du noyau.
id: temps passé inactif.
wa: Temps passé à attendre l’entrée ou la sortie.
st: Temps volé sur une machine virtuelle. Il s’agit du temps qu’une machine virtuelle doit attendre que l’hyperviseur ait fini de réparer d’autres machines virtuelles avant de pouvoir revenir et s’occuper de cette machine virtuelle.
Utilisation d’un intervalle de temps
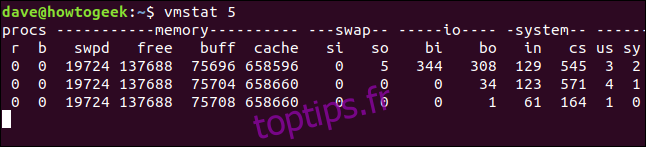
Nous pouvons demander à vmstat de fournir des mises à jour régulières de ces chiffres en utilisant une valeur de délai. La valeur du délai est fournie en secondes. Pour que les statistiques soient mises à jour toutes les cinq secondes, nous utiliserions la commande suivante:
vmstat 5

Toutes les cinq secondes, vmstat ajoutera une autre ligne de données à la table. Vous devrez appuyer sur Ctrl + C pour arrêter cela.
Utilisation d’une valeur de comptage
L’utilisation d’une valeur de délai trop faible exercera une pression supplémentaire sur votre système. Si vous avez besoin de mises à jour rapides pour essayer de diagnostiquer un problème, il est recommandé d’utiliser une valeur de comptage ainsi qu’une valeur de délai.
La valeur de comptage indique à vmstat le nombre de mises à jour à effectuer avant de se fermer et vous renvoie à l’invite de commande. Si vous ne fournissez pas de valeur de comptage, vmstat fonctionnera jusqu’à ce qu’il soit arrêté par Ctrl + C.
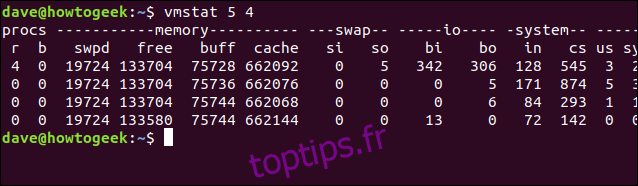
Pour que vmstat fournisse une mise à jour toutes les cinq secondes, mais uniquement pour quatre mises à jour, utilisez la commande suivante:
vmstat 5 4

Après quatre mises à jour, vmstat s’arrête de lui-même.
Changer les unités
Vous pouvez choisir d’afficher les statistiques de mémoire et d’échange en kilo-octets ou en mégaoctets à l’aide de l’option -S (unité-caractère). Ceci doit être suivi de l’un des k, K, m ou M. Ils représentent:
k: 1000 octets
K: 1024 octets
m: 1000000 octets
M: 1048576 octets
Pour que les statistiques soient mises à jour toutes les 10 secondes avec les statistiques de mémoire et de swap affichées en mégaoctets, utilisez la commande suivante:
vmstat 10 -S M

Les statistiques de mémoire et de swap sont désormais affichées en mégaoctets. Notez que l’option -S n’affecte pas les statistiques de bloc d’E / S. Ceux-ci sont toujours affichés par blocs.
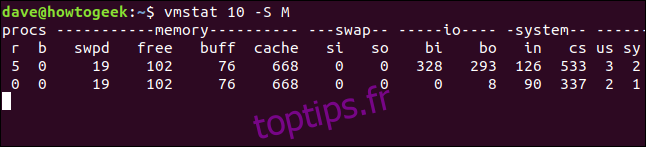
Mémoire active et inactive
Si vous utilisez l’option -a (active), les colonnes de mémoire tampon et de mémoire cache sont remplacées par les colonnes «inact» et «active». Comme ils le suggèrent, ceux-ci montrent la quantité de mémoire inactive et active.
Pour voir ces deux colonnes au lieu des colonnes buff et cache, incluez l’option -a, comme indiqué:
vmstat 5 -a -S M

Les colonnes inactives et actives sont affectées par l’option -S (unité-caractère).
Fourches
Le commutateur -f affiche le nombre de fourchettes qui se sont produites depuis le démarrage de l’ordinateur.
En d’autres termes, cela montre le nombre de tâches qui ont été lancées (et, pour la plupart d’entre elles, refermées) depuis le démarrage du système. Chaque processus lancé à partir de la ligne de commande augmenterait ce chiffre. Chaque fois qu’une tâche ou un processus génère ou clone une nouvelle tâche, ce chiffre augmente.
vmstat -f

L’affichage des fourches ne se met pas à jour.
Affichage de Slabinfo
Le noyau a sa propre gestion de la mémoire à gérer ainsi que la gestion de la mémoire pour le système d’exploitation et toutes les applications.
Comme vous pouvez l’imaginer, le noyau alloue et désalloue de la mémoire encore et encore pour les nombreux types d’objets de données qu’il doit gérer. Pour rendre cela aussi efficace que possible, il utilise un système appelé dalles. C’est une forme de mise en cache.
La mémoire allouée, utilisée et non requise pour un type spécifique d’objet de données noyau peut être réutilisée pour un autre objet de données du même type sans que la mémoire ne soit désallouée et réallouée. Considérez les dalles comme des segments de RAM pré-alloués, faits sur mesure, pour les besoins propres du noyau.
Pour afficher les statistiques des dalles, utilisez l’option -m (dalles). Vous devrez utiliser sudo et vous serez invité à entrer votre mot de passe. Comme la sortie peut être assez longue, nous la transmettons moins.
sudo vmstat -m | less

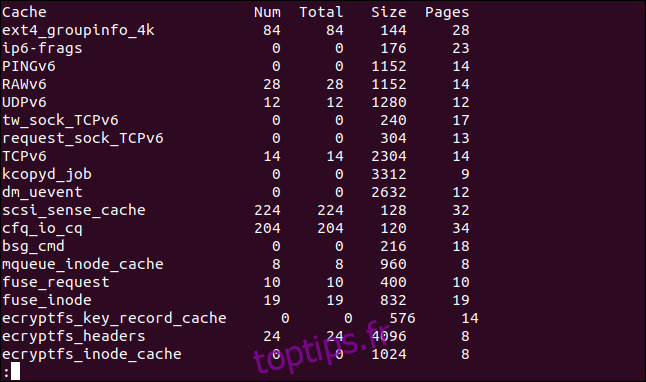
La sortie comporte cinq colonnes. Ceux-ci sont:
Cache: nom du cache.
num: le nombre d’objets actuellement actifs dans ce cache.
total: nombre total d’objets disponibles dans ce cache.
size: la taille de chaque objet dans le cache.
pages: Le nombre total de pages de mémoire qui ont (au moins) un objet actuellement associé à ce cache.
Appuyez sur q pour laisser moins.
Affichage des compteurs d’événements et des statistiques de la mémoire
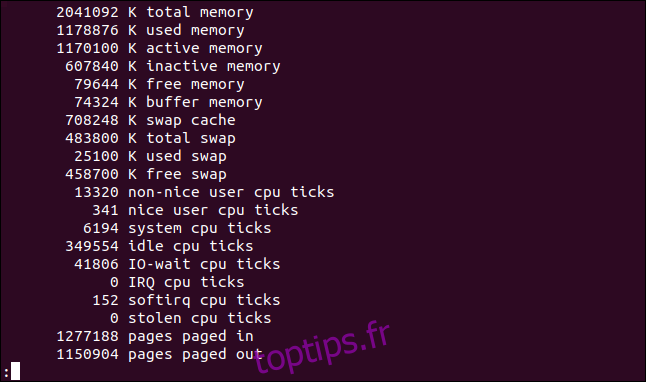
Pour afficher une page de compteurs d’événements et de statistiques de mémoire, utilisez l’option -s (stats). Notez que c’est un «s» minuscule.
vmstat -s

Bien que les statistiques rapportées soient en grande partie les mêmes que les informations qui composent la sortie par défaut de vmstat, certaines d’entre elles sont réparties plus en détail.
Par exemple, la sortie par défaut combine à la fois le temps CPU de l’utilisateur gentil et non agréable dans la colonne «nous». L’affichage -s (stats) répertorie ces statistiques séparément.
Affichage des statistiques du disque
Vous pouvez obtenir une liste similaire des statistiques de disque en utilisant l’option -d (disque).
vmstat -d | less

Pour chaque disque, trois colonnes sont affichées, ce sont les lectures, les écritures et les E / S.
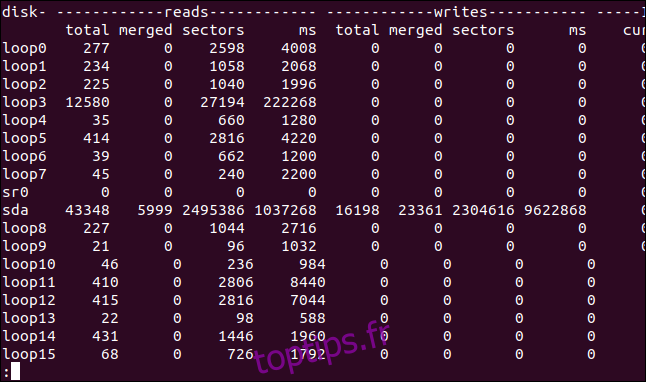
IO est la colonne la plus à droite. Notez que la colonne sec dans IO est mesurée en secondes, mais les statistiques basées sur le temps dans les colonnes de lecture et d’écriture sont mesurées en millisecondes.
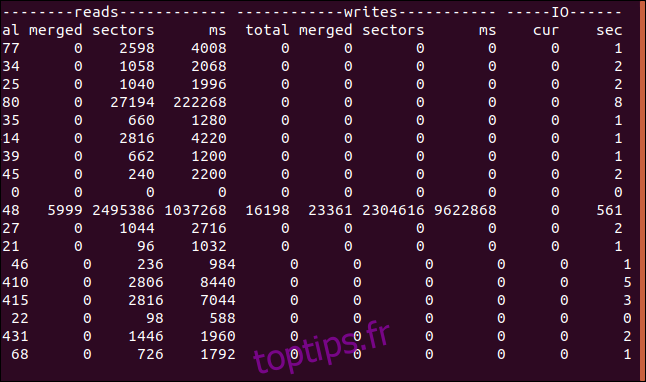
Voici ce que signifient les colonnes:
Lit
total: le nombre total de lectures de disque.
fusionné: le nombre total de lectures groupées.
secteurs: le nombre total de secteurs qui ont été lus.
ms: nombre total de temps en millisecondes qui ont été utilisés pour lire les données du disque.
écrit
total: le nombre total d’écritures sur disque.
fusionné: le nombre total d’écritures groupées.
secteurs: Le nombre total de secteurs écrits dans.
ms = Nombre total de temps en millisecondes qui ont été utilisés pour écrire des données sur le disque.
IO
cur: nombre de lectures ou d’écritures sur le disque en cours.
sec: temps passé en secondes pour toute lecture ou écriture en cours.
Affichage des statistiques récapitulatives du disque
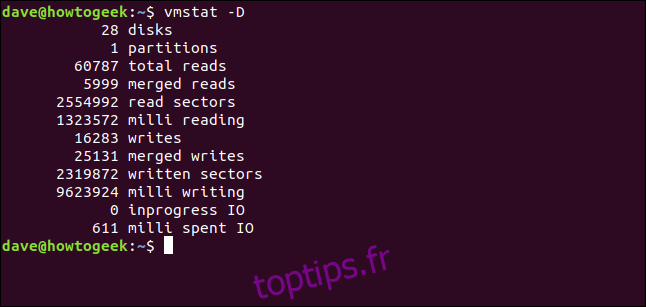
Pour afficher un affichage rapide des statistiques récapitulatives de l’activité de votre disque, utilisez l’option -D (disk-sum). Notez le «D» majuscule
vmstat -D

Le nombre de disques peut sembler anormalement élevé. L’ordinateur utilisé pour rechercher cet article exécute Ubuntu. Avec Ubuntu, chaque fois que vous installez une application à partir d’un Snap, un pseudo-système de fichiers squashfs est créé qui est attaché à un périphérique / dev / loop.
Malheureusement, ces entrées de périphériques sont comptées comme des périphériques de disque dur par de nombreuses commandes et utilitaires Linux.
Affichage des statistiques de partition
Pour afficher les statistiques relatives à une partition spécifique, utilisez l’option -p (partition) et fournissez l’identificateur de partition comme paramètre de ligne de commande.
Ici, nous allons regarder la partition sda1. Le chiffre un indique qu’il s’agit de la première partition du périphérique sda, qui est le disque dur principal de cet ordinateur.
vmstat -p sda1

Les informations renvoyées indiquent le nombre total de lectures et d’écritures sur disque depuis et vers cette partition, ainsi que le nombre de secteurs inclus dans les actions de lecture et d’écriture sur disque.

Un coup d’oeil sous le capot
Il est toujours bon de savoir comment soulever le capot et de voir ce qui se passe en dessous. Parfois, vous essayez de résoudre un problème, parfois cela ne vous intéresse pas parce que vous voulez savoir comment fonctionne votre ordinateur.
vmstat peut vous fournir une tonne d’informations utiles. Vous savez maintenant comment y accéder et ce que cela signifie. Et il est prévenu: lorsque vous avez besoin de retrousser vos manches et d’effectuer des diagnostics, vous saurez que vmstat est de votre côté.