L’utilitaire Linux `uniq` est conçu pour analyser vos fichiers texte et identifier les lignes uniques ou celles qui apparaissent en plusieurs exemplaires. Dans cet article, nous allons explorer en détail sa flexibilité et ses différentes options, afin de vous montrer comment exploiter pleinement cet outil pratique.
Identifier les doublons de texte sous Linux
La commande `uniq` est efficace, adaptable et excelle dans sa fonction principale. Toutefois, comme beaucoup de commandes Linux, elle possède ses particularités. Il est crucial de les connaître pour éviter toute confusion. Sans une bonne compréhension préalable, vous risquez d’être surpris par les résultats. Nous mettrons en lumière ces spécificités tout au long de notre exploration.
La commande `uniq` s’inscrit parfaitement dans la philosophie Unix, qui prône la création d’outils spécialisés qui accomplissent une tâche unique avec brio. C’est pourquoi elle est particulièrement adaptée pour être intégrée dans des pipelines de commandes, souvent en collaboration avec d’autres outils. L’un de ses alliés les plus fréquents est `sort`, car `uniq` exige des données triées pour fonctionner correctement.
Alors, mettons-nous au travail !
Utilisation de `uniq` sans options
Nous disposons d’un fichier texte contenant les paroles de la chanson Robert Johnson intitulée « Je crois que je vais épousseter mon balai ». Examinons comment `uniq` traite ce fichier.
Pour cela, nous allons exécuter la commande suivante et afficher le résultat avec `less`:
uniq dust-my-broom.txt | less
Nous visualisons l’intégralité des paroles, y compris les doublons, dans `less` :
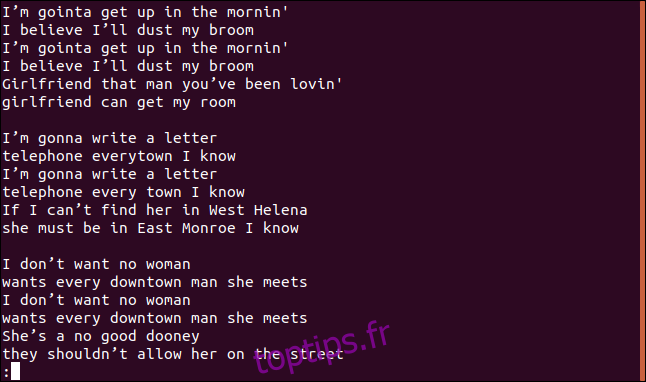
Cela ne semble pas correspondre à une liste de lignes uniques ou de doublons.
Effectivement, c’est la première particularité à connaître. En l’absence d’options, `uniq` agit comme si l’option `-u` (lignes uniques) avait été spécifiée. Cela signifie qu’il n’affichera que les lignes qui apparaissent une seule fois dans le fichier. Si des doublons persistent, c’est parce que `uniq` considère comme doublon une ligne qui est directement adjacente à son identique. C’est là qu’intervient le tri.
En triant le fichier au préalable, nous regroupons les lignes identiques et `uniq` les identifie comme doublons. Nous allons donc trier le fichier, rediriger le résultat vers `uniq`, et ensuite le résultat final vers `less`.
Pour cela, nous allons utiliser cette commande :
sort dust-my-broom.txt | uniq | less

Une liste triée de lignes apparaît dans `less`.
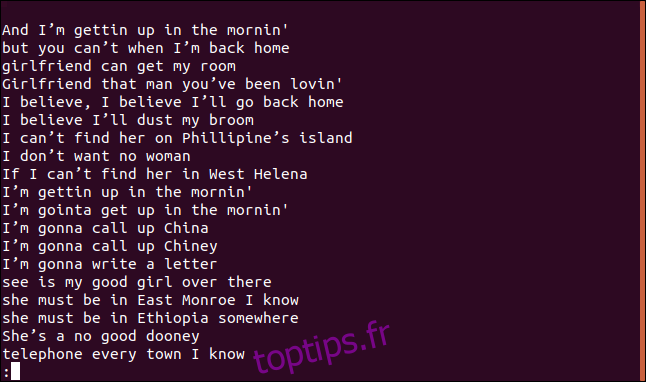
La phrase « Je crois que je vais épousseter mon balai » revient plus d’une fois dans la chanson, notamment deux fois dans les quatre premières lignes.
Alors, pourquoi n’apparaît-elle qu’une seule fois dans la liste des lignes uniques ? C’est parce que la première occurrence de chaque ligne est considérée comme unique ; seules les entrées suivantes sont des doublons. On peut voir cela comme la liste de la première apparition de chaque ligne unique.
Pour éviter de devoir utiliser `sort` à chaque fois, nous allons trier le fichier une seule fois et rediriger le résultat dans un nouveau fichier.
Nous tapons la commande suivante :
sort dust-my-broom.txt > sorted.txt

Nous disposons maintenant d’un fichier pré-trié pour nos prochains essais.
Compter les doublons
L’option `-c` (compter) permet d’afficher le nombre d’occurrences de chaque ligne dans le fichier.
Pour cela, tapez :
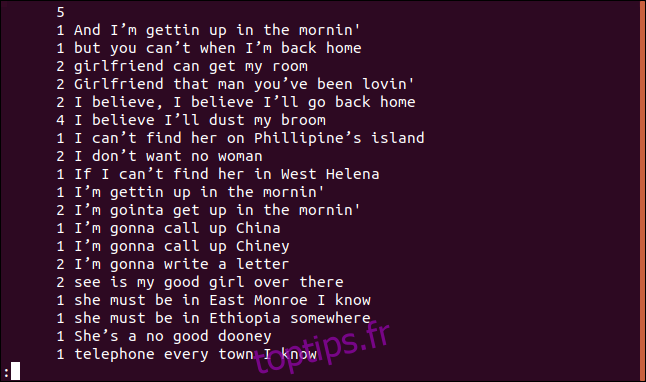
uniq -c sorted.txt | less

Chaque ligne commence par le nombre de fois qu’elle apparaît dans le fichier. On remarque que la première ligne est vide. Cela signifie qu’il y a cinq lignes vides dans le fichier.
Si vous souhaitez que les lignes soient triées en fonction du nombre d’occurrences, vous pouvez rediriger le résultat de `uniq` vers `sort`. Dans notre exemple, nous allons utiliser les options `-r` (inverse) et `-n` (tri numérique), puis afficher le résultat avec `less`.
Voici la commande à utiliser :
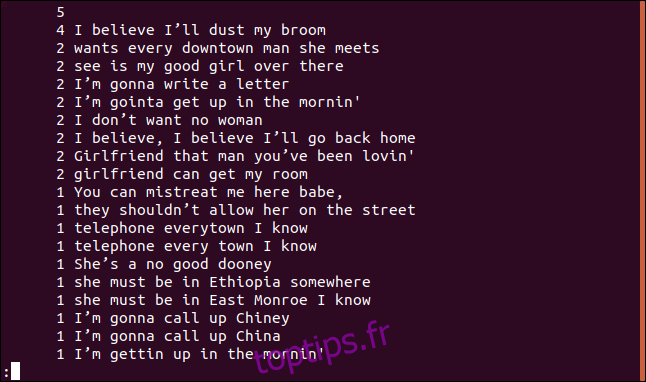
uniq -c sorted.txt | sort -rn | less

La liste est maintenant triée par ordre décroissant selon la fréquence d’apparition de chaque ligne.
Afficher uniquement les doublons
Si vous voulez afficher uniquement les lignes qui se répètent, l’option `-d` (dupliquées) est faite pour vous. Peu importe combien de fois une ligne est dupliquée dans un fichier, elle n’apparaîtra qu’une seule fois dans la liste.
Voici la commande pour utiliser cette option :
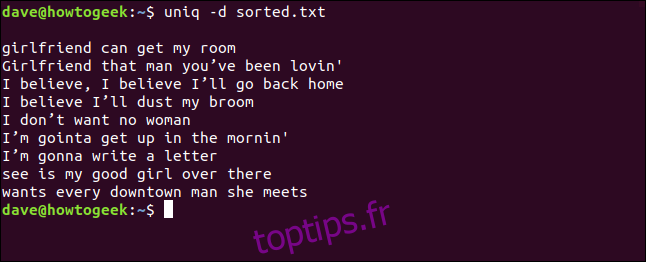
uniq -d sorted.txt

Les lignes dupliquées sont listées. La ligne vide en haut indique que le fichier contient des lignes vides en double.
On peut également combiner les options `-d` (dupliquées) et `-c` (compter) et utiliser `sort` pour trier le résultat. Cela permet d’afficher une liste triée des lignes qui apparaissent au moins deux fois.
Pour ce faire, utilisez cette commande :
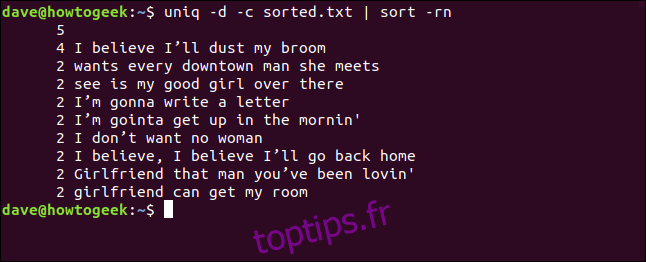
uniq -d -c sorted.txt | sort -rn
Afficher toutes les lignes dupliquées
Si vous souhaitez visualiser toutes les occurrences des lignes dupliquées, l’option `-D` (toutes les lignes dupliquées) est la bonne. Chaque fois qu’une ligne apparaît, elle est listée.
Pour utiliser cette option, tapez :
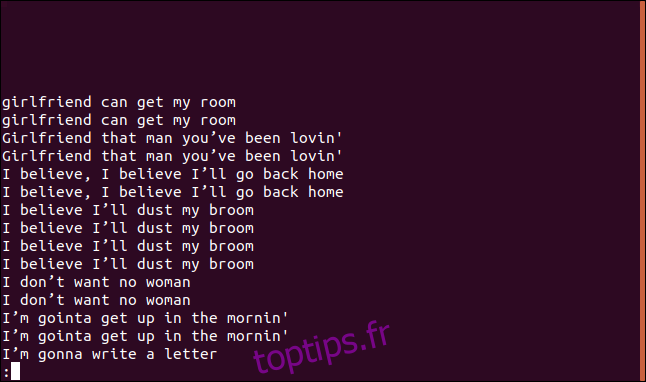
uniq -D sorted.txt | less

La liste contient autant d’entrées que d’occurrences de chaque ligne dupliquée.
Avec l’option `–group`, vous pouvez insérer une ligne vide avant (préfixer), après (ajouter) ou avant et après (les deux) chaque groupe de lignes dupliquées.
Par exemple, si nous utilisons l’option ‘append’, tapez ceci :
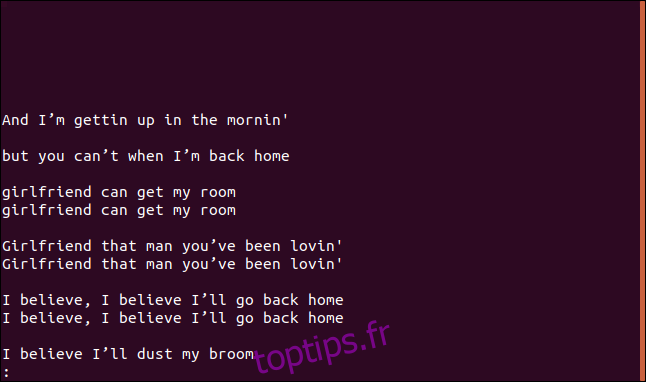
uniq --group=append sorted.txt | less

Les groupes de lignes dupliquées sont séparés par des lignes vides, ce qui les rend plus faciles à lire.
Vérifier un nombre spécifique de caractères
Par défaut, `uniq` compare l’intégralité de chaque ligne. Si vous voulez limiter la comparaison à un certain nombre de caractères, vous pouvez utiliser l’option `-w` (vérifier les caractères).
Par exemple, pour comparer uniquement les trois premiers caractères, tapez :
uniq -w 3 --group=append sorted.txt | less

Les résultats et les regroupements obtenus sont très différents.
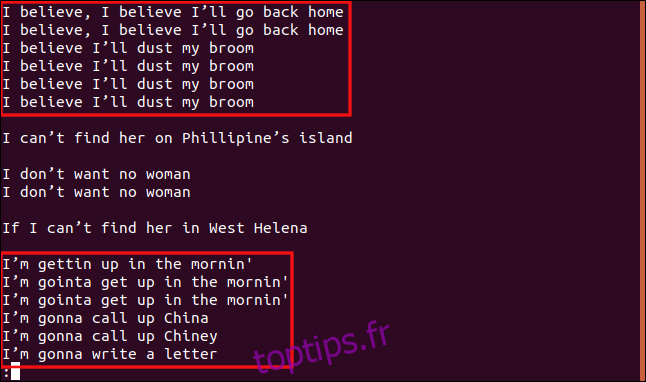
Toutes les lignes commençant par « I b » sont regroupées, car ces trois caractères sont identiques, et elles sont donc considérées comme des doublons.
De même, toutes les lignes qui commencent par « Je s » sont considérées comme des doublons, même si le reste du texte diffère.
Ignorer un nombre de caractères
Dans certains cas, il peut être utile d’ignorer un certain nombre de caractères au début de chaque ligne. Par exemple, si les lignes d’un fichier sont numérotées. Ou encore, si vous voulez que `uniq` ignore un horodatage et commence à comparer à partir du sixième caractère.
Voici une version de notre fichier trié avec des lignes numérotées.
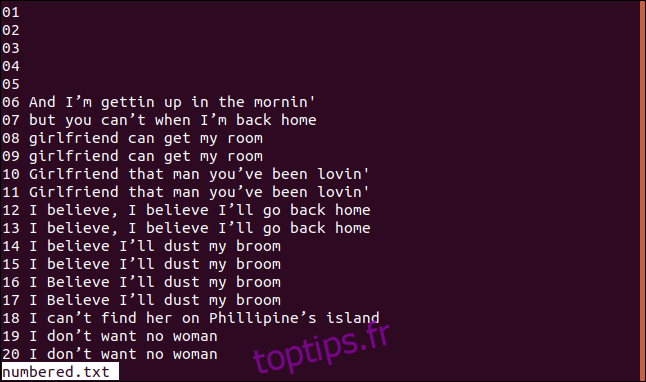
Si nous voulons que `uniq` commence à comparer les lignes à partir du troisième caractère, nous pouvons utiliser l’option `-s` (ignorer les caractères) en tapant cette commande :
uniq -s 3 -d -c numbered.txt
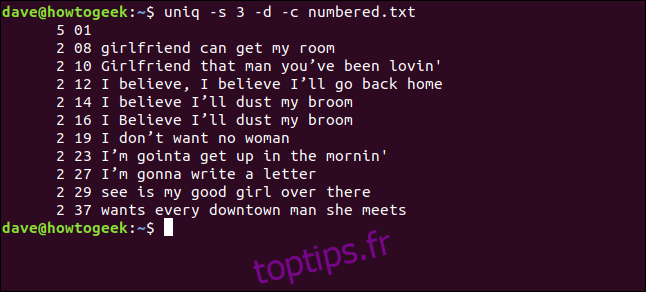
Les lignes sont correctement identifiées comme des doublons et comptées. Notez que les numéros de lignes affichés sont ceux de la première occurrence de chaque doublon.
Il est aussi possible d’ignorer des champs (une séquence de caractères et un espace blanc) plutôt que des caractères. Pour cela, nous allons utiliser l’option `-f` (champs), qui indique à `uniq` combien de champs ignorer.
Pour dire à `uniq` d’ignorer le premier champ, tapez :
uniq -f 1 -d -c numbered.txt
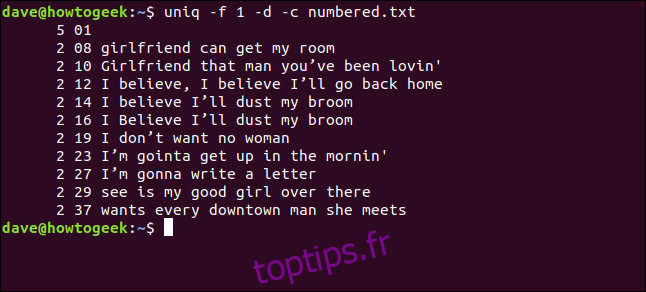
Nous obtenons le même résultat que lorsque nous avons demandé à `uniq` d’ignorer les trois premiers caractères de chaque ligne.
Ignorer la casse
Par défaut, `uniq` est sensible à la casse. Autrement dit, si une même lettre apparaît en majuscule et en minuscule, les lignes sont considérées comme différentes.
Par exemple, observez le résultat de cette commande :
uniq -d -c sorted.txt | sort -rn
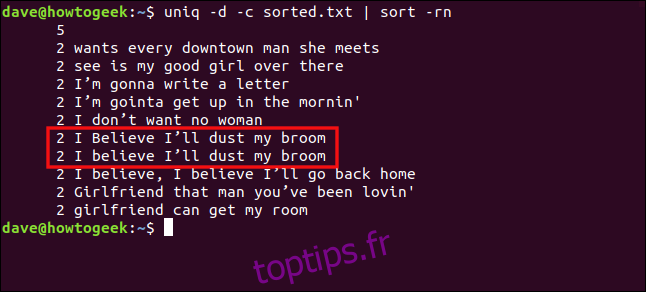
Les lignes « Je crois que je vais dépoussiérer mon balai » et « Je crois que je vais dépoussiérer mon balai » ne sont pas traitées comme des doublons à cause de la différence de casse entre le « B » et le « crois ».
Cependant, si nous incluons l’option `-i` (ignorer la casse), ces lignes seront considérées comme des doublons. Pour ce faire, tapez :
uniq -d -c -i sorted.txt | sort -rn
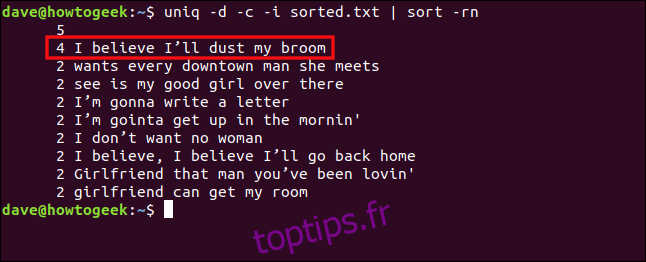
Les lignes sont maintenant identifiées et regroupées comme des doublons.
Linux propose une multitude d’outils spécialisés. Comme beaucoup d’entre eux, `uniq` n’est pas un utilitaire que vous utiliserez tous les jours.
Une part importante de la maîtrise de Linux consiste à se souvenir quel outil utiliser pour résoudre un problème donné et où le trouver. Avec de la pratique, vous serez sur la bonne voie.
Ou vous pouvez toujours chercher sur toptips.fr – nous avons probablement un article sur le sujet.