Comment synchroniser quotidiennement votre base de données Oracle sur site avec AWS
L'évolution des bases de données d'entreprise : la migration vers le cloud
Depuis deux décennies, l'observation du développement des logiciels d'entreprise révèle une tendance claire : le déplacement des bases de données vers le cloud. Cette transformation, bien que bénéfique, n'est pas sans défis.
J'ai participé à plusieurs projets de migration, visant à intégrer des bases de données existantes dans le cloud d'Amazon Web Services (AWS). Si la documentation AWS décrit souvent ce processus comme simple, l'expérience montre que la mise en œuvre peut s'avérer complexe, voire échouer.
Cet article explore les aspects pratiques de cette migration, en se concentrant sur le cas suivant :
- La source : Bien que le type de base de données source importe peu en théorie (une approche similaire peut être utilisée pour la plupart des systèmes populaires), Oracle est souvent privilégié par les grandes entreprises et servira donc de référence.
- La cible : Le choix de la base de données cible dans AWS est flexible et l'approche décrite reste pertinente.
- Le mode : La migration peut être complète (actualisation totale) ou incrémentale (actualisation partielle). On peut opter pour un chargement par lots (avec un décalage entre les états source et cible) ou un chargement (presque) en temps réel. Nous aborderons ces deux options.
- La fréquence : La migration peut être unique (avec un basculement complet vers le cloud) ou nécessiter une période de transition avec une synchronisation quotidienne entre l'environnement sur site et AWS. Bien que la première approche soit plus simple, la seconde est souvent préférée, mais avec davantage de points de rupture potentiels. Les deux scénarios seront analysés.
Analyse du problème
Le besoin est souvent exprimé simplement :
Nous souhaitons développer des services dans AWS et avons besoin que nos données soient rapidement copiées dans la base de données "ABC". L'objectif est d'utiliser les données dans AWS immédiatement et d'ajuster les structures de base de données ultérieurement.
Cependant, quelques considérations importantes méritent d'être soulignées :
- Il est important de ne pas se précipiter sur une simple copie des données existantes, en pensant les ajuster plus tard. Bien que cette approche soit rapide et simple, elle peut conduire à des problèmes architecturaux fondamentaux, difficiles à résoudre par la suite sans refactorisation majeure de la nouvelle plateforme cloud. L'écosystème cloud est différent de l'environnement sur site. Les services seront utilisés différemment, et une réplication 1:1 de l'état sur site n'est généralement pas la meilleure option. Cela peut convenir dans des cas spécifiques, mais une vérification rigoureuse est nécessaire.
- Il est crucial de remettre en question le besoin en posant des questions pertinentes :
- Qui utilisera principalement la nouvelle plateforme ? Un utilisateur métier transactionnel sur site peut se transformer en data scientist, analyste de données, ou un service (Databricks, Glue, modèles d'apprentissage automatique) dans le cloud.
- Les tâches quotidiennes doivent-elles être conservées après la transition vers le cloud ? Si non, comment vont-elles évoluer ?
- Anticipez-vous une croissance importante des données ? C'est souvent la raison principale de la migration vers le cloud. Le nouveau modèle de données doit être conçu pour supporter cette croissance.
- Il faut anticiper les requêtes générales que les utilisateurs adresseront à la nouvelle base de données. Cela permettra de déterminer l'ampleur des modifications à apporter au modèle de données existant pour garantir des performances optimales.
Préparation de la migration
Après avoir choisi la base de données cible et défini le modèle de données, il est temps de se familiariser avec l'AWS Schema Conversion Tool (SCT). Cet outil offre plusieurs fonctionnalités :
- Analyse et extraction du modèle de données source. SCT examine la base de données actuelle et génère un modèle de données initial.
- Proposition d'une structure de modèle de données cible adaptée à la base de données choisie.
- Génération de scripts de déploiement de la base de données cible, permettant d'installer le modèle de données. Après leur exécution, la base de données dans le cloud sera prête à recevoir les données depuis la base de données sur site.
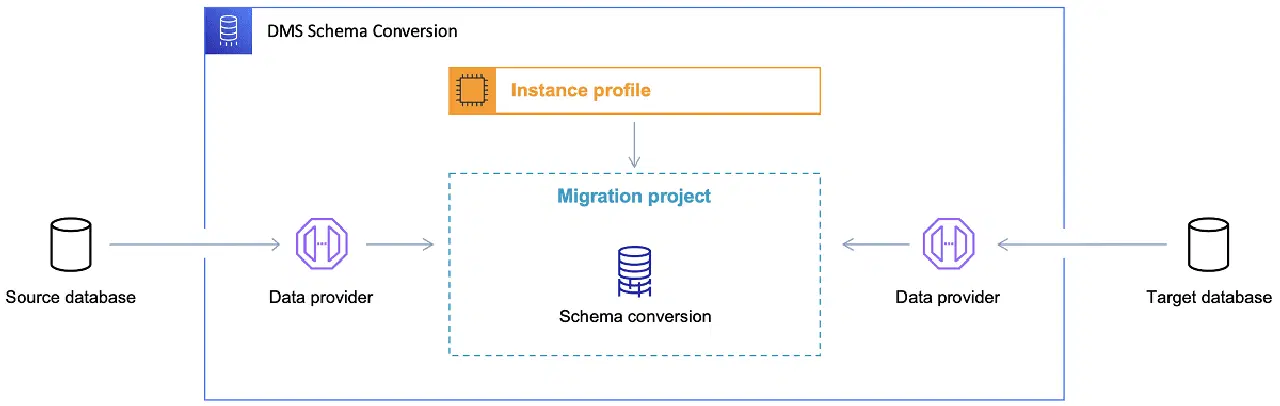
Référence : Documentation AWS
Voici quelques conseils pour l'utilisation du Schema Conversion Tool :
Il est rare que le résultat généré par l'outil soit utilisable directement. Considérez-le comme une base de référence que vous devrez ajuster en fonction de votre compréhension des données et de leur utilisation future dans le cloud.
Les tables étaient souvent sélectionnées par les utilisateurs dans le but d'obtenir des résultats rapides sur une entité spécifique du domaine. Dans le cloud, les données peuvent être utilisées à des fins d'analyse. Les index de base de données qui étaient pertinents sur site peuvent devenir inutiles. Pensez à partitionner les données différemment dans le nouveau système cible.
Il peut également être intéressant de prévoir des transformations de données pendant la migration, en modifiant le modèle de données cible pour certaines tables. Ces transformations devront être implémentées dans l'outil de migration.
Si les bases de données source et cible sont du même type (Oracle sur site vs. Oracle dans AWS, PostgreSQL vs. Aurora Postgresql), il est préférable d'utiliser un outil de migration dédié et pris en charge nativement par la base de données (par exemple, Data Pump pour Oracle).
Cependant, dans la plupart des cas, les bases de données source et cible ne seront pas compatibles. L'AWS Database Migration Service (DMS) est alors l'outil de choix évident.
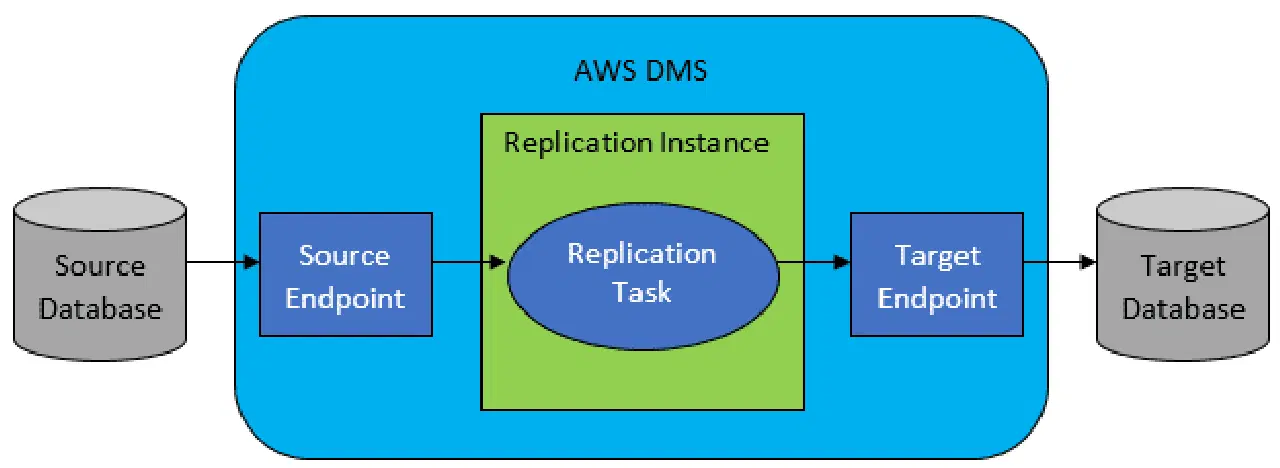
Référence : Documentation AWS
AWS DMS permet de configurer des tâches au niveau de la table, définissant :
- La base de données source et la table à connecter.
- Les spécifications pour extraire les données de la table source.
- Les outils de transformation (si nécessaire) pour mapper les données source vers les données de la table cible.
- La base de données cible et la table où charger les données.
La configuration des tâches DMS est effectuée dans un format simple comme JSON.
Dans un scénario idéal, il suffirait d'exécuter les scripts de déploiement sur la base de données cible et de démarrer la tâche DMS. Mais la réalité est plus complexe.
Migration complète des données en une seule fois

Le scénario le plus simple consiste à déplacer l'ensemble de la base de données vers le cloud. La procédure est alors la suivante :
- Définition des tâches DMS pour chaque table source.
- Configuration précise des tâches DMS, notamment le parallélisme, la mise en cache, la configuration du serveur DMS, le dimensionnement du cluster, etc. Cette phase est souvent la plus longue et nécessite des tests approfondis.
- Création des tables cibles (vides) dans la base de données cible.
- Planification d'une fenêtre de temps pour la migration. Il est nécessaire de vérifier que cette fenêtre est suffisante via des tests de performance. La base de données source ne doit pas être modifiée pendant la migration.
Si la configuration du DMS est correcte, cette migration se déroulera sans problème. Les seules préoccupations sont les performances de l'opération et le bon dimensionnement pour éviter les erreurs de stockage.
Synchronisation quotidienne incrémentielle

C'est dans ce scénario que les choses se compliquent. Le DMS peut fonctionner en deux modes :
- Chargement complet : les tâches DMS sont lancées manuellement ou selon une planification. Une fois terminées, elles ne sont plus actives.
- Change Data Capture (CDC) : la tâche DMS s'exécute en continu et analyse la base de données source pour détecter les changements au niveau de la table et les répliquer dans la base de données cible.
En optant pour CDC, il faut choisir comment extraire les modifications delta de la base de données source.
#1. Lecteur de journaux de rétablissement Oracle
Une option consiste à utiliser le lecteur natif d'Oracle, qui permet d'obtenir les données modifiées et de les répliquer dans la base de données cible.
Bien que cela semble logique pour une source Oracle, le lecteur de journaux redo sollicite le cluster Oracle et impacte les autres activités. Plus vous avez de tâches DMS configurées (ou de clusters DMS en parallèle), plus vous devrez augmenter la capacité du cluster Oracle, ce qui peut impacter les coûts.
#2. Mineur de journaux AWS DMS
Cette solution native AWS ne sollicite pas la base de données Oracle source. Les journaux redo sont copiés dans le cluster DMS où ils sont traités. Cette approche est plus lente que l'option précédente car plus d'opérations sont nécessaires. Le lecteur personnalisé d'AWS pour les journaux redo d'Oracle est probablement moins performant que le lecteur natif.
En fonction de la taille de la base de données source et du volume de modifications quotidiennes, vous pouvez obtenir une synchronisation incrémentielle des données quasi temps réel. Dans la plupart des autres cas, il faudra ajuster la configuration et le parallélisme des clusters source et cible, ou encore le nombre de tâches DMS pour atteindre un délai acceptable entre source et cible.
Il est important de noter que toutes les modifications de tables sources ne sont pas prises en charge par CDC (par exemple, l'ajout d'une colonne). Dans certains cas, une modification manuelle de la table cible et un redémarrage de la tâche CDC peuvent être nécessaires (en perdant les données existantes dans la base de données cible).
Quand les choses tournent mal, quoi qu'il arrive

Il existe un scénario spécifique où la promesse d'une réplication quotidienne peut être difficile à tenir.
Le DMS ne peut traiter les journaux redo qu'à une certaine vitesse. Même en utilisant plusieurs instances de DMS, chaque instance a une limite de vitesse de lecture des journaux redo. Si le volume de modifications quotidiennes est important et que les journaux redo d'Oracle deviennent volumineux (500 Go et plus), le CDC peut ne pas fonctionner et la réplication pourrait ne pas se terminer avant la fin de la journée. Le volume de données à traiter ne ferait qu'augmenter.
Dans ce cas, le CDC n'était pas une option viable. La solution mise en place pour répliquer les données le jour même consistait à :
- Séparer les tables volumineuses peu utilisées et les répliquer seulement une fois par semaine (pendant le week-end).
- Répartir la réplication des tables moins volumineuses, mais importantes, sur plusieurs tâches DMS. Certaines tables ont été migrées par 10 tâches DMS ou plus en parallèle. La répartition des données entre les tâches a nécessité un codage personnalisé.
- Ajouter plus (jusqu'à 4 dans ce cas) d'instances DMS et répartir les tâches DMS entre elles de manière équitable, en tenant compte de la taille des tables.
Nous avons utilisé le mode de chargement complet du DMS pour répliquer les données quotidiennes. Ce n'était pas une solution idéale, mais elle a fonctionné et continue de fonctionner même après plusieurs années.