Comment les coffres-forts de données sont l'avenir de l'entreposage de données[+5 Learning Resources]
Face à l'augmentation constante des volumes de données générées par les entreprises, l'approche traditionnelle de l'entreposage de données se révèle de plus en plus complexe et onéreuse à gérer. Le Data Vault, une méthodologie émergente, propose une alternative en fournissant une solution évolutive, flexible et économique pour administrer de vastes ensembles de données.
Cet article explore comment les Data Vaults redéfinissent l'avenir de l'entreposage de données, et pourquoi un nombre croissant d'organisations adoptent cette approche. Nous mettons également à disposition des ressources pédagogiques pour ceux qui souhaitent approfondir ce sujet.
Qu'est-ce que le Data Vault ?
Le Data Vault est une technique de modélisation d'entrepôt de données particulièrement adaptée aux contextes agiles. Il offre une grande adaptabilité aux évolutions, un suivi temporel complet de l'historique des données, et permet une parallélisation efficace des processus de chargement des données. Dan Linstedt a conceptualisé la modélisation Data Vault dans les années 1990.
Après sa première publication en 2000, elle a gagné en notoriété en 2002 grâce à une série d'articles. En 2007, Linstedt a obtenu l'approbation de Bill Inmon, qui l'a qualifiée de "choix optimal" pour son architecture Data Vault 2.0.
Quiconque s'intéresse à un entrepôt de données agile sera rapidement confronté au Data Vault. Cette technologie se distingue par son orientation vers les besoins des entreprises, en permettant des ajustements simples et flexibles à un entrepôt de données.
Data Vault 2.0 considère l'ensemble du processus de développement et de l'architecture, et comprend la méthode des composants (implémentation), l'architecture et le modèle. L'avantage réside dans le fait que cette approche prend en compte tous les aspects de la business intelligence avec l'entrepôt de données sous-jacent lors du développement.
Le modèle Data Vault offre une solution innovante pour surmonter les limites des méthodes traditionnelles de modélisation des données. Sa capacité d'évolution, sa flexibilité et son agilité fournissent une base solide pour créer une plateforme de données capable de s'adapter à la complexité et à la diversité des environnements de données actuels.
L'architecture en étoile du Data Vault et la distinction entre entités et attributs facilitent l'intégration et l'harmonisation des données provenant de multiples systèmes et domaines, favorisant un développement progressif et agile.
Un rôle essentiel du Data Vault dans la création d'une plateforme de données est d'établir une source unique de vérité pour toutes les données. Sa vue unifiée des données et la prise en charge de la capture et du suivi des modifications des données historiques via des tables satellites permettent d'assurer la conformité, l'audit, les exigences réglementaires, ainsi que des analyses et des rapports complets.
Les capacités d'intégration de données en temps quasi réel du Data Vault, via le chargement delta, facilitent la gestion de vastes volumes de données dans des environnements en constante évolution tels que les applications Big Data et IoT.
Data Vault comparé aux modèles d'entrepôt de données traditionnels
La forme normale 3 (3NF) est l'un des modèles d'entrepôt de données traditionnels les plus reconnus, souvent privilégié dans de nombreuses implémentations d'envergure. Il correspond d'ailleurs aux idées de Bill Inmon, l'un des pionniers du concept d'entrepôt de données.
L'architecture Inmon est basée sur le modèle de base de données relationnelle et élimine la redondance des données en décomposant les sources de données en tables plus petites, stockées dans des magasins de données et reliées par des clés primaires et étrangères. Elle garantit la cohérence et l'exactitude des données en appliquant des règles d'intégrité référentielle.
L'objectif de la forme normale était de créer un modèle de données complet à l'échelle de l'entreprise pour l'entrepôt de données principal. Cependant, elle présente des défis en termes d'évolutivité et de flexibilité en raison de datamarts fortement couplés, de difficultés de chargement en mode quasi temps réel, de requêtes complexes, d'une conception et d'une mise en œuvre descendantes.
Le modèle Kimball, utilisé pour l'OLAP (traitement analytique en ligne) et les magasins de données, est un autre modèle d'entrepôt de données reconnu. Les tables de faits contiennent des données agrégées, tandis que les tables de dimension décrivent les données stockées dans un schéma en étoile ou en flocon de neige. Dans cette architecture, les données sont organisées en tables de faits et de dimensions qui sont dénormalisées pour simplifier l'interrogation et l'analyse.
Kimball repose sur un modèle dimensionnel optimisé pour les requêtes et les rapports, ce qui le rend idéal pour les applications de business intelligence. Cependant, il a rencontré des difficultés avec l'isolement des informations orientées sujet, la redondance des données, des structures de requête incompatibles, des défis d'évolutivité, une granularité incohérente des tables de faits, des problèmes de synchronisation et la nécessité d'une conception descendante avec une mise en œuvre ascendante.
À l'inverse, l'architecture Data Vault est une approche hybride qui combine des aspects des architectures 3NF et Kimball. Il s'agit d'un modèle basé sur les principes relationnels, la normalisation des données et les mathématiques de redondance, qui représente différemment les relations entre les entités et structure les champs de table et les horodatages de manière spécifique.
Dans cette architecture, toutes les données sont stockées dans un coffre-fort de données brutes ou un lac de données, tandis que les données fréquemment utilisées sont stockées dans un format normalisé dans un coffre-fort d'entreprise. Ce dernier contient des données historiques et spécifiques au contexte, pouvant être utilisées pour l'élaboration de rapports.
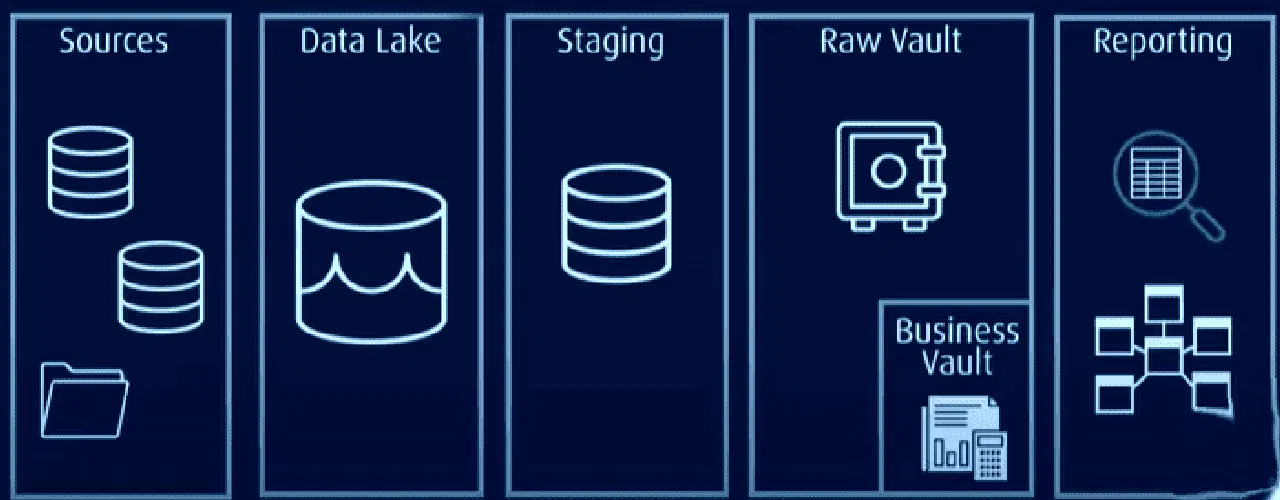
Data Vault résout les problèmes des modèles traditionnels en étant plus efficace, évolutif et flexible. Il permet un chargement en temps quasi réel, une meilleure intégrité des données et une extension facile sans altérer les structures existantes. Le modèle peut également être étendu sans nécessiter la migration des tables existantes.
| Approche de modélisation | Structure de données | Approche de conception |
| Modélisation 3NF | Tables dans 3NF | Descendante |
| Modélisation Kimball | Schéma en étoile ou en flocon | Ascendante |
| Data Vault | Hub-and-Spoke | Ascendante |
Architecture du Data Vault
Data Vault possède une architecture de type hub-and-spoke et se compose principalement de trois niveaux :
Niveau intermédiaire : recueille les données brutes provenant des systèmes sources, tels que les CRM ou les ERP.
Niveau de l'entrepôt de données : lorsqu'il est modélisé selon le modèle Data Vault, ce niveau inclut :
- Raw Data Vault : stocke les données brutes.
- Business Data Vault : comprend les données harmonisées et transformées selon les règles métier (optionnel).
- Metrics Vault : conserve les informations relatives à l'exécution (optionnel).
- Coffre-fort opérationnel : stocke les données transitant directement des systèmes opérationnels vers l'entrepôt de données (optionnel).
Niveau Data Mart : ce niveau modélise les données sous forme de schéma en étoile et/ou d'autres techniques de modélisation. Il fournit des informations pour l'analyse et l'élaboration de rapports.
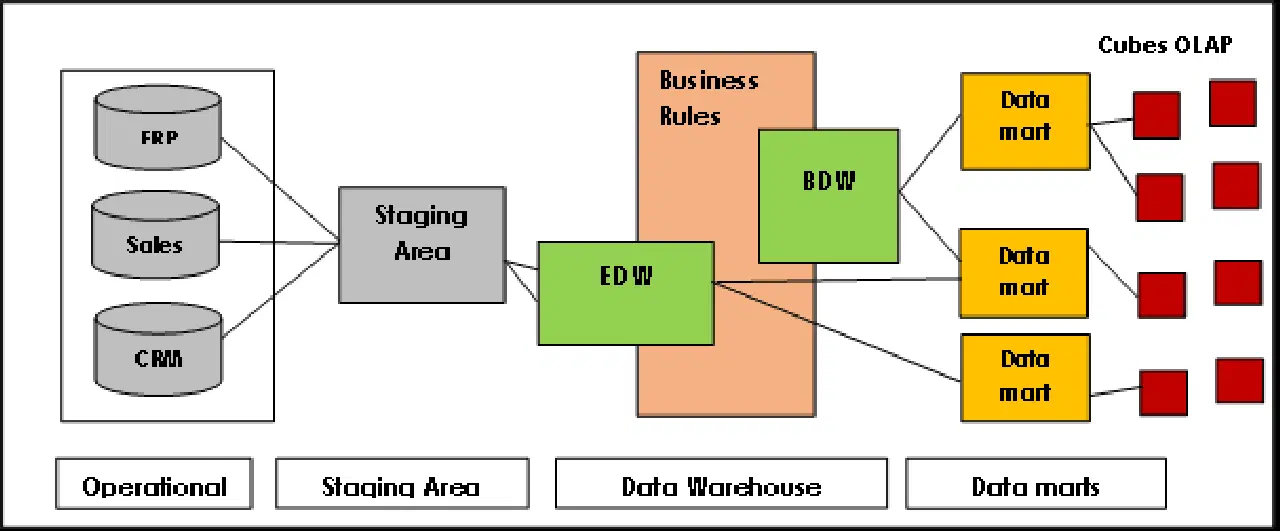
Source de l'image : Lamia Yessad
Data Vault ne nécessite pas de réarchitecture. De nouvelles fonctionnalités peuvent être construites en parallèle en utilisant directement les concepts et les méthodes de Data Vault, et les composants existants ne sont pas perdus. Les frameworks peuvent simplifier considérablement le travail : ils créent une couche entre l'entrepôt de données et le développeur, réduisant ainsi la complexité de la mise en œuvre.
Composants du Data Vault
Lors de la modélisation, Data Vault divise toutes les informations relatives à l'objet en trois catégories, contrairement à la modélisation classique de troisième forme normale. Ces informations sont ensuite stockées de manière strictement séparée. Les domaines fonctionnels peuvent être cartographiés dans Data Vault à travers ce que l'on appelle les hubs, les liens et les satellites :
#1. Hubs
Les hubs sont au cœur du concept d'entreprise de base, tel que client, fournisseur, vente ou produit. La table hub est formée autour de la clé métier (nom ou emplacement du magasin) lorsqu'une nouvelle instance de cette clé métier est introduite pour la première fois dans l'entrepôt de données.
Le hub ne contient aucune information descriptive et aucune clé étrangère (FK). Il comprend uniquement la clé métier, une séquence générée par l'entrepôt de clés d'identification ou de hachage, l'horodatage de chargement et la source d'enregistrement.
#2. Liens
Les liens établissent des relations entre les clés métier. Chaque entrée dans un lien modélise les relations n:m d'un nombre quelconque de hubs. Il permet au coffre-fort de données de s'adapter avec souplesse aux modifications de la logique métier des systèmes sources, telles que les modifications de la cardinalité des relations. Comme le hub, le lien ne contient aucune information descriptive. Il se compose des ID de séquence des hubs auxquels il fait référence, d'un ID de séquence généré par l'entrepôt, d'un horodatage de chargement et d'une source d'enregistrement.
#3. Satellites
Les satellites contiennent les informations descriptives (contexte) d'une clé métier stockée dans un hub ou d'une relation stockée dans un lien. Les satellites fonctionnent selon le principe "insertion uniquement", ce qui signifie que l'historique complet des données est conservé dans le satellite. Plusieurs satellites peuvent décrire une seule clé métier (ou relation). Cependant, un satellite ne peut décrire qu'une seule clé (hub ou lien).
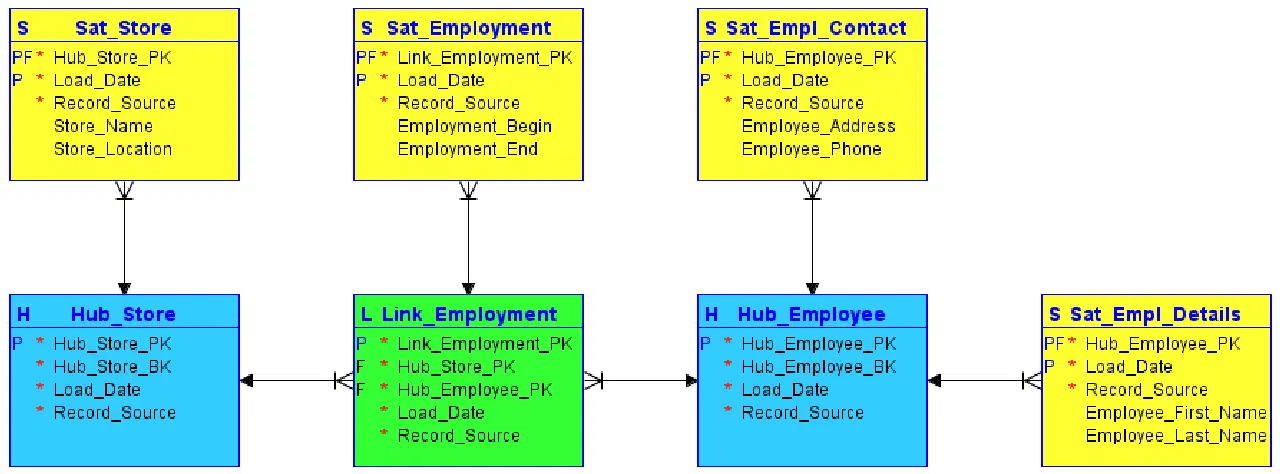
Source de l'image : Carbidfischer
Comment créer un modèle Data Vault
La construction d'un modèle Data Vault implique plusieurs étapes, chacune étant essentielle pour assurer la capacité du modèle à évoluer, sa flexibilité et sa capacité à répondre aux besoins de l'entreprise :
#1. Identifier les entités et les attributs
Identifiez les entités commerciales et leurs attributs correspondants. Cela implique de travailler en étroite collaboration avec les parties prenantes de l'entreprise pour comprendre leurs besoins et les données qu'elles doivent capturer. Une fois ces entités et attributs identifiés, séparez-les en hubs, liens et satellites.
#2. Définir les relations entre entités et créer des liens
Après avoir identifié les entités et les attributs, les relations entre les entités sont définies et des liens sont créés pour représenter ces relations. Chaque lien reçoit une clé métier identifiant la relation entre les entités. Des satellites sont ensuite ajoutés pour capturer les attributs et les relations des entités.
#3. Établir des règles et des normes
Après la création des liens, un ensemble de règles et de normes de modélisation de coffre-fort de données doit être établi pour s'assurer que le modèle est flexible et peut gérer les changements au fil du temps. Ces règles et normes doivent être examinées et mises à jour régulièrement pour garantir leur pertinence et leur alignement sur les besoins de l'entreprise.
#4. Remplir le modèle
Une fois le modèle créé, il doit être alimenté en données en utilisant une approche de chargement incrémentiel. Cela implique de charger les données dans les hubs, les liens et les satellites en utilisant des chargements delta. Le chargement delta permet de garantir que seules les modifications apportées aux données sont chargées, ce qui réduit le temps et les ressources nécessaires à l'intégration des données.
#5. Tester et valider le modèle
Enfin, le modèle doit être testé et validé pour s'assurer qu'il répond aux exigences de l'entreprise et qu'il est suffisamment évolutif et flexible pour gérer les changements futurs. Une maintenance et des mises à jour régulières doivent être effectuées pour garantir que le modèle reste aligné sur les besoins de l'entreprise et continue de fournir une vue unifiée des données.
Ressources d'apprentissage Data Vault
La maîtrise de Data Vault peut apporter des compétences et des connaissances précieuses, très recherchées dans les secteurs actuels axés sur les données. Voici une liste complète de ressources, comprenant des cours et des ouvrages, qui peuvent vous aider à appréhender les subtilités de Data Vault :
#1. Modélisation d'un entrepôt de données avec Data Vault 2.0

Ce cours Udemy est une introduction complète à l'approche de modélisation Data Vault 2.0, à la gestion de projet Agile et à l'intégration Big Data. Le cours couvre les bases et les principes fondamentaux de Data Vault 2.0, y compris son architecture et ses couches, les coffres-forts commerciaux et d'informations, ainsi que les techniques de modélisation avancées.
Il vous apprend à concevoir un modèle Data Vault de A à Z, à convertir des modèles traditionnels tels que 3NF et des modèles dimensionnels en Data Vault, et à comprendre les principes de la modélisation dimensionnelle dans Data Vault. Le cours nécessite une connaissance de base des bases de données et des fondamentaux du SQL.
Avec une note élevée de 4,4 sur 5 et plus de 1 700 avis, ce cours, qui est un best-seller, est adapté à tous ceux qui souhaitent construire une base solide en Data Vault 2.0 et en intégration Big Data.
#2. Modélisation du Data Vault expliquée avec un cas d'utilisation

Ce cours Udemy a pour but de vous guider dans la création d'un modèle Data Vault en utilisant un exemple commercial concret. Il sert de guide pour débutants à la modélisation de Data Vault, couvrant des concepts clés tels que les scénarios appropriés pour l'utilisation des modèles Data Vault, les limites de la modélisation OLAP conventionnelle, ainsi qu'une approche systématique pour la construction d'un modèle Data Vault. Le cours est accessible aux personnes ayant une connaissance minimale des bases de données.
#3. Le Data Vault Guru : un guide pragmatique
Le Data Vault Guru de M. Patrick Cuba est un guide complet de la méthodologie Data Vault, qui offre une occasion unique de modéliser l'entrepôt de données d'entreprise en utilisant des principes d'automatisation similaires à ceux utilisés dans la livraison de logiciels.
L'ouvrage présente une vue d'ensemble de l'architecture moderne, puis propose un guide complet sur la manière de fournir un modèle de données flexible, capable de s'adapter aux changements de l'entreprise, à savoir le coffre-fort de données.
De plus, le livre élargit la méthodologie Data Vault en fournissant une correction automatisée de la chronologie, des pistes d'audit, un contrôle des métadonnées et une intégration avec des outils de livraison agiles.
#4. Construire un entrepôt de données évolutif avec Data Vault 2.0
Ce livre fournit aux lecteurs un guide complet pour créer un entrepôt de données évolutif du début à la fin en utilisant la méthodologie Data Vault 2.0.
Il aborde tous les aspects essentiels de la construction d'un entrepôt de données évolutif, y compris la technique de modélisation Data Vault, conçue pour prévenir les défaillances typiques de l'entrepôt de données.
L'ouvrage présente de nombreux exemples pour aider les lecteurs à comprendre clairement les concepts. Avec ses idées pratiques et ses exemples concrets, ce livre constitue une ressource essentielle pour toute personne s'intéressant à l'entreposage de données.
#5. L'éléphant dans le réfrigérateur : étapes guidées pour réussir Data Vault
The Elephant in the Fridge de John Giles est un guide pratique qui vise à aider les lecteurs à réussir Data Vault en partant de l'entreprise pour arriver à l'entreprise.
L'ouvrage met l'accent sur l'importance de l'ontologie d'entreprise et de la modélisation des concepts d'entreprise, et fournit des conseils étape par étape sur la manière d'appliquer ces concepts pour créer un modèle de données robuste.
Grâce à des conseils pratiques et à des exemples de modèles, l'auteur propose une explication claire et simple de sujets complexes, faisant de ce livre un excellent guide pour ceux qui découvrent le Data Vault.
Derniers mots
Data Vault représente l'avenir de l'entreposage de données, offrant aux entreprises des avantages significatifs en termes d'agilité, d'évolutivité et d'efficacité. Il est particulièrement bien adapté aux entreprises ayant besoin de charger rapidement de grands volumes de données, et à celles qui cherchent à développer leurs applications de business intelligence de manière agile.
De plus, les entreprises possédant une architecture en silo existante peuvent grandement bénéficier de la mise en œuvre d'un entrepôt de données central en amont à l'aide de Data Vault.
Vous pourriez également être intéressé à en savoir davantage sur la lignée des données.