Comment installer Beautiful Soup et l'utiliser pour des projets Web Scraping ?
À l'ère du numérique, où les données sont reines, la collecte manuelle d'informations est devenue une approche dépassée. L'omniprésence des ordinateurs connectés à Internet a transformé le web en une source inépuisable de données. Ainsi, le *web scraping* s'est imposé comme la méthode moderne la plus rapide et efficace pour la collecte de données. Et dans ce domaine, Python se distingue grâce à un outil puissant : Beautiful Soup. Cet article vous guidera à travers les étapes nécessaires pour installer Beautiful Soup et commencer vos propres projets de *web scraping*.
Avant de nous plonger dans l'installation et l'utilisation de Beautiful Soup, examinons les raisons qui justifient son adoption.
Qu'est-ce que Beautiful Soup ?
Imaginez que vous effectuez des recherches sur les "conséquences du COVID sur la santé publique" et que vous trouvez plusieurs pages web contenant des données pertinentes. Cependant, ces sites ne proposent pas d'option de téléchargement direct de ces informations. C'est là que Beautiful Soup entre en jeu.
Beautiful Soup est une bibliothèque Python conçue pour extraire des données à partir de sites web. Elle facilite la récupération de données à partir de pages HTML ou XML.
Leonard Richardson a introduit le concept de Beautiful Soup en 2004 pour faciliter le *web scraping*. Il continue de contribuer au projet, en publiant régulièrement les nouvelles versions sur son compte Twitter.
Bien que Beautiful Soup ait été initialement développé pour Python 3.8, il fonctionne parfaitement avec Python 3 et Python 2.4.
Il arrive souvent que les sites web utilisent des systèmes de protection captcha pour protéger leurs données contre les outils d'intelligence artificielle. Dans ces cas, des ajustements de l'en-tête "user-agent" dans Beautiful Soup, ou l'utilisation d'API de résolution de Captcha, permettent de simuler un navigateur légitime et de contourner ces systèmes de détection.
Si vous manquez de temps pour explorer toutes les fonctionnalités de Beautiful Soup, ou si vous souhaitez un processus de scraping simple et efficace, il existe des API de web scraping qui vous permettent d'obtenir les données souhaitées en fournissant simplement une URL.
Pour les programmeurs, l'utilisation de Beautiful Soup ne sera pas intimidante en raison de sa syntaxe simple pour naviguer et extraire des données à partir de pages web en fonction de critères d'analyse conditionnelle. De plus, elle est accessible aux débutants.
Bien que Beautiful Soup ne soit pas conçu pour le *web scraping* avancé, il est particulièrement adapté pour extraire des données de fichiers écrits en langages de balisage.
Sa documentation claire et détaillée est un autre avantage majeur de Beautiful Soup.
Voyons maintenant comment installer facilement Beautiful Soup sur votre ordinateur.
Comment installer Beautiful Soup pour le Web Scraping ?
Pip, un gestionnaire de paquets Python développé en 2008, est devenu l'outil standard pour les développeurs pour installer des bibliothèques et dépendances Python.
Pip est généralement inclus dans les versions récentes de Python. Par conséquent, si vous avez installé une version récente de Python sur votre système, vous êtes déjà prêt à démarrer.
Ouvrez l'invite de commande et entrez la commande pip suivante pour installer Beautiful Soup instantanément.
pip install beautifulsoup4
Vous devriez voir un résultat similaire à la capture d'écran suivante :
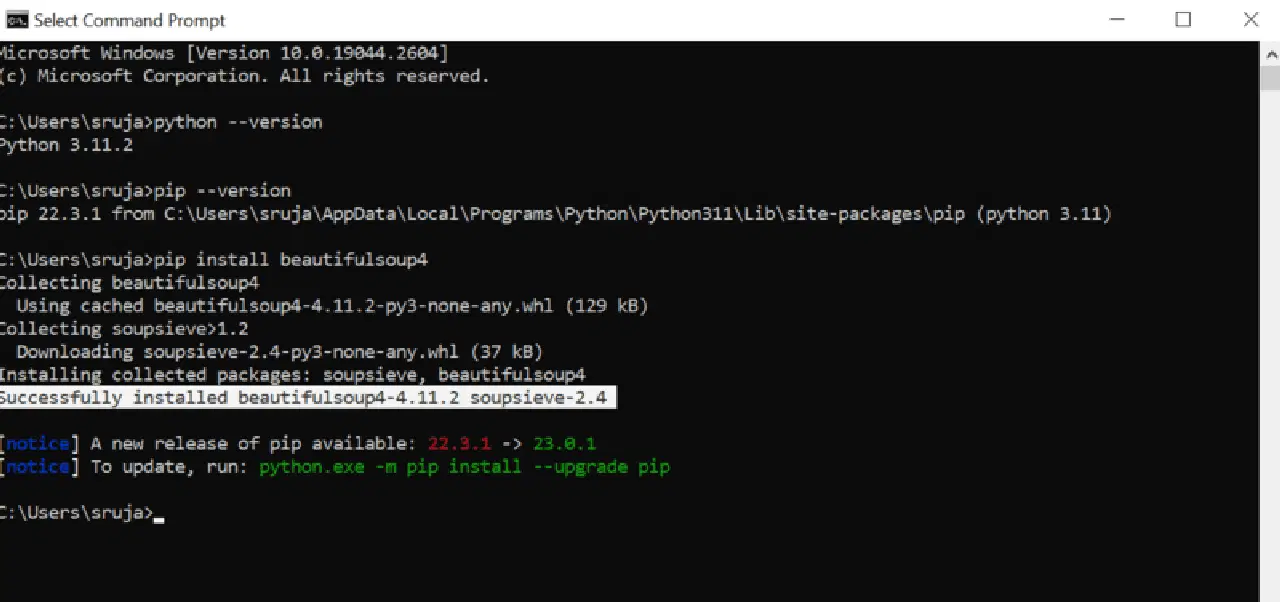
Assurez-vous que votre programme d'installation PIP est à jour pour éviter les erreurs fréquentes.
La commande pour mettre à jour PIP est :
pip install --upgrade pip
Nous avons franchi une étape importante. Beautiful Soup est désormais installé sur votre machine. Voyons comment l'utiliser pour le *web scraping*.
Comment importer et travailler avec Beautiful Soup pour le Web Scraping ?
Pour importer Beautiful Soup dans votre script Python, entrez la commande suivante dans votre IDE :
from bs4 import BeautifulSoup
Beautiful Soup est maintenant disponible dans votre fichier Python pour être utilisé pour le *web scraping*.
Illustrons par un exemple de code comment extraire des données avec Beautiful Soup.
Nous pouvons demander à Beautiful Soup de rechercher des balises HTML spécifiques dans le code source du site web et d'extraire les informations contenues dans ces balises.
Dans cet article, nous utiliserons marketwatch.com, un site qui affiche les cours des actions en temps réel pour diverses entreprises. Extrayons quelques données de ce site pour vous familiariser avec la bibliothèque Beautiful Soup.
Importez les packages "requests", qui permet de gérer les requêtes HTTP et "urllib" pour charger la page web à partir de son URL.
from urllib.request import urlopen import requests
Stockez l'URL de la page web dans une variable afin de pouvoir y accéder plus facilement :
url="https://www.marketwatch.com/investing/stock/amzn"
Utilisez la méthode "urlopen" de la bibliothèque "urllib" pour stocker le code HTML de la page dans une variable. Transmettez l'URL à la fonction "urlopen" et stockez le résultat dans une variable.
page = urlopen(url)
Créez un objet Beautiful Soup et analysez le contenu de la page web à l'aide de "html.parser".
soup_obj = BeautifulSoup(page, 'html.parser')
Le code HTML de la page web ciblée est maintenant stocké dans la variable "soup_obj".
Avant de continuer, examinons le code source de la page ciblée pour mieux comprendre sa structure et ses balises.
Faites un clic droit n'importe où sur la page web avec votre souris. Ensuite, vous trouverez une option "Inspecter" ou similaire, comme indiqué ci-dessous.
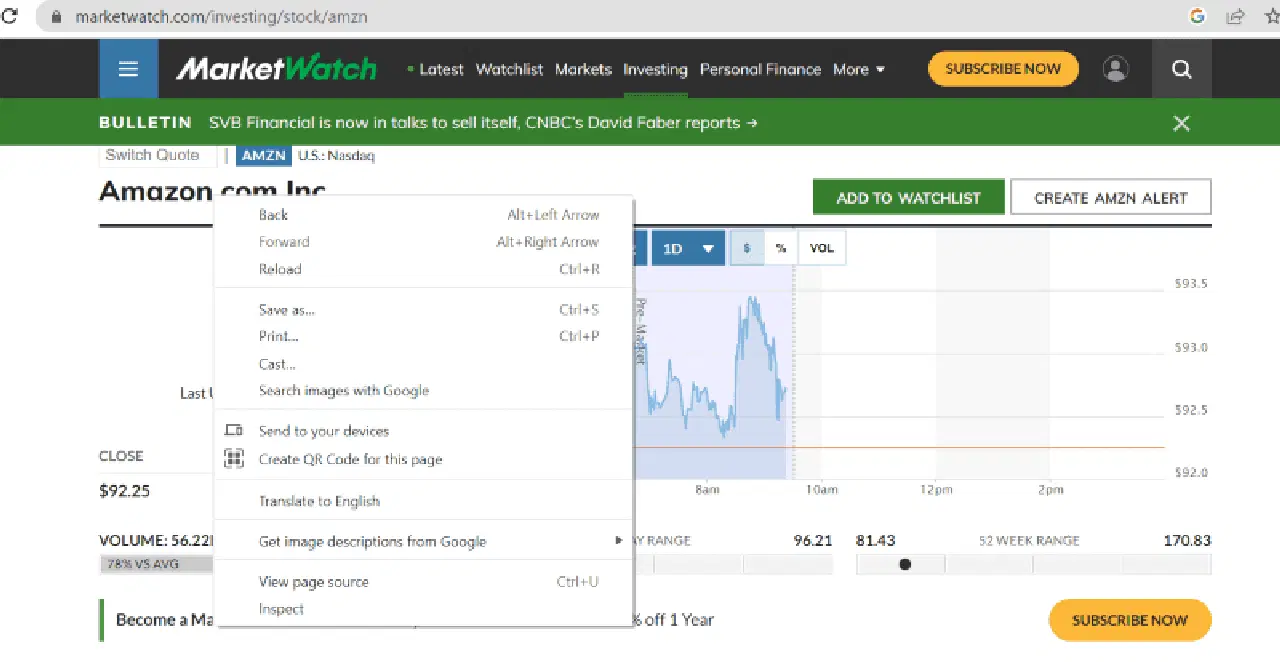
Cliquez sur "Inspecter" pour afficher le code source.
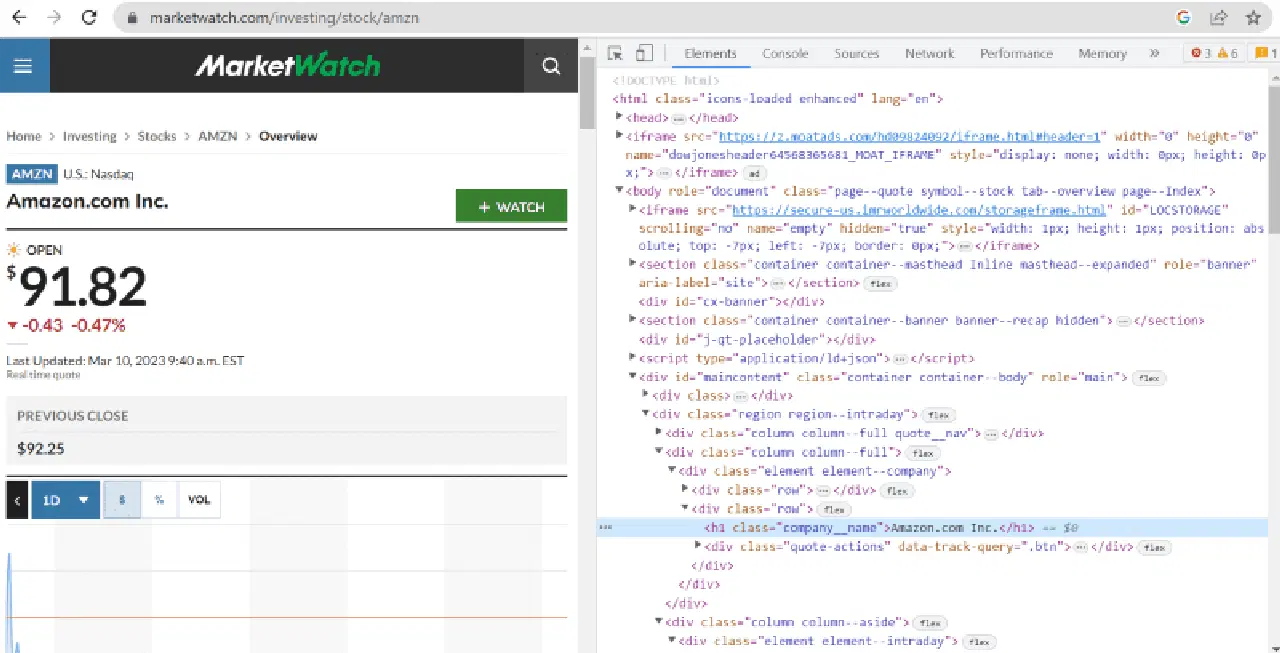
Le code source révèle les balises, les classes et d'autres détails concernant chaque élément visible sur l'interface du site web.
La méthode "find" de Beautiful Soup permet de rechercher les balises HTML demandées et d'en extraire les données. Pour cela, il faut indiquer le nom de la classe et les balises à la méthode. Elle extraira alors l'élément de code HTML qui correspond à la requête.
Par exemple, "Amazon.com Inc." affiché sur la page web a le nom de classe "company__name" et est étiqueté sous la balise "h1". Nous pouvons spécifier ces informations à la méthode "find" pour extraire l'extrait de code HTML pertinent et le stocker dans une variable.
name = soup_obj.find('h1', attrs={'class': 'company__name'})
Affichons le contenu HTML stocké dans la variable "name" et le texte correspondant.
print(name) print(name.text)

Les données extraites sont affichées à l'écran.
Web Scraping du site web IMDb
Beaucoup d'entre nous consultent le site IMDb avant de regarder un film. Cet exemple vous permettra de récupérer une liste des films les mieux notés et de vous familiariser avec Beautiful Soup pour le *web scraping*.
Étape 1 : Importez les bibliothèques Beautiful Soup et Requests.
from bs4 import BeautifulSoup import requests
Étape 2 : Stockez l'URL de la page web à récupérer dans une variable nommée "url".
Le package "requests" permet d'obtenir le code HTML de la page web à partir de l'URL.
url = requests.get('https://www.imdb.com/search/title/?count=100&groups=top_1000&sort=user_rating')
Étape 3 : Analysons le code HTML de la page web à l'aide de Beautiful Soup pour créer un objet de type Beautiful Soup.
soup_obj = BeautifulSoup(url.text, 'html.parser')
La variable "soup_obj" contient maintenant le code HTML de la page web, comme l'illustre l'image suivante :
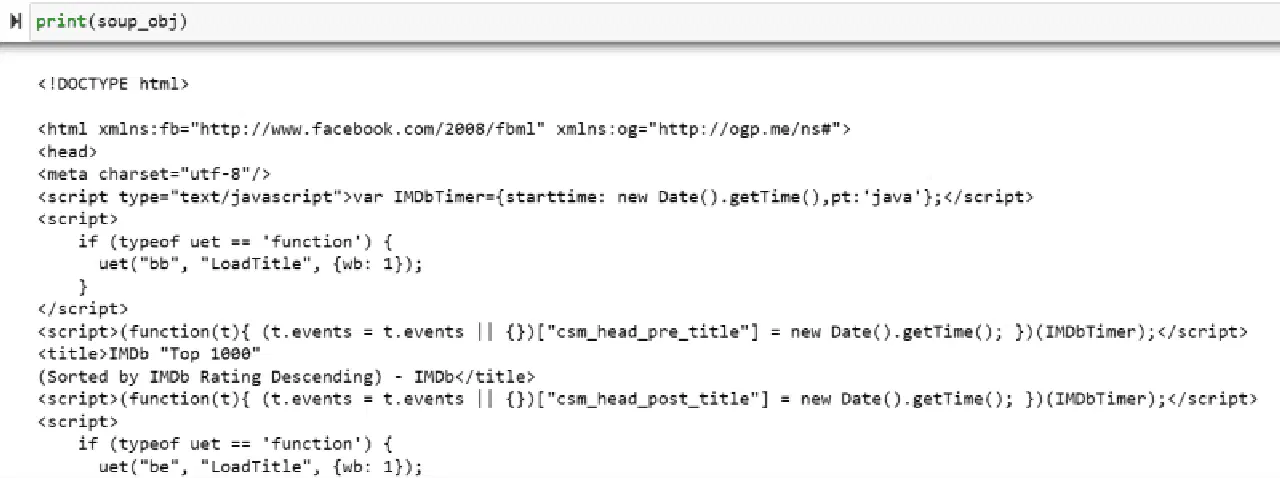
Examinons le code source de la page web pour identifier les balises HTML contenant les données à extraire.
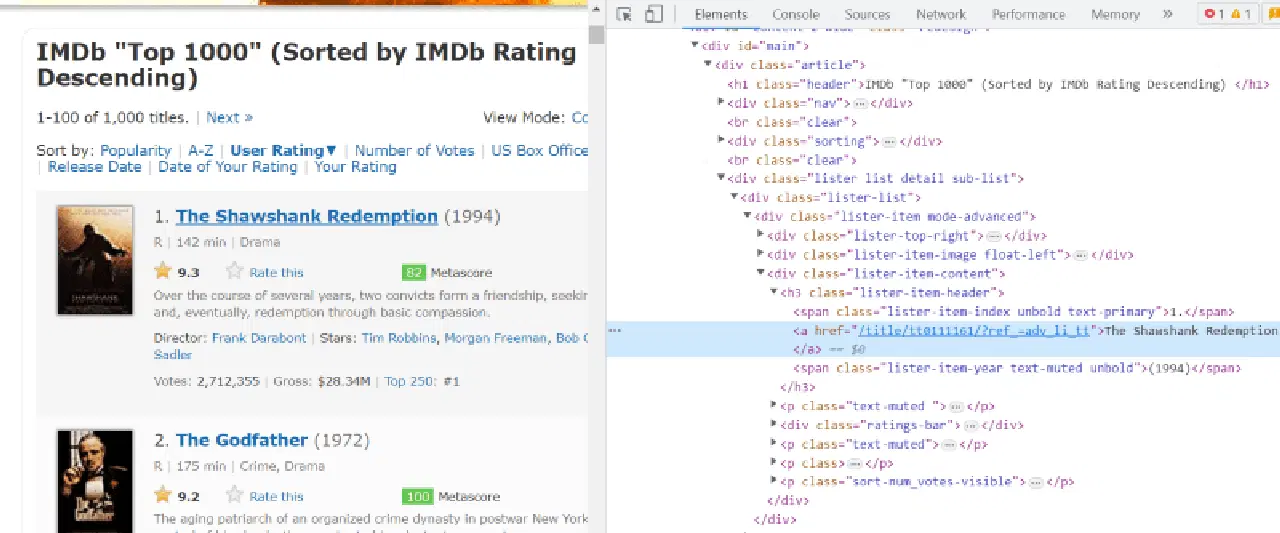
Passez le curseur sur l'élément de la page web que vous souhaitez extraire. Faites un clic droit et accédez à l'option "Inspecter" pour afficher le code source de cet élément. Les images suivantes vous guideront :
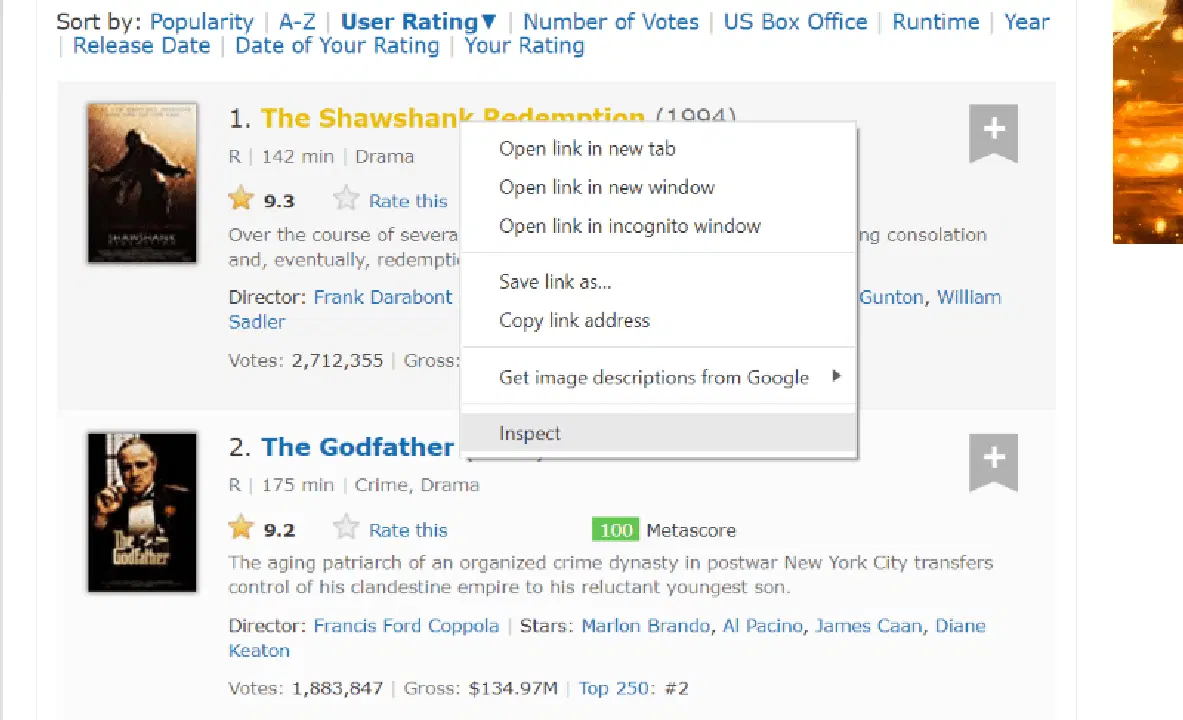
La classe "lister-list" contient toutes les données des films les mieux notés, sous forme de divisions imbriquées.
Dans le code HTML de chaque carte de film, sous la classe "lister-item mode-advanced", il y a une balise "h3" qui stocke le nom, le classement et l'année de sortie du film, comme illustré ci-dessous :
Remarque : La méthode "find" dans Beautiful Soup recherche la première balise qui correspond au nom d'entrée spécifié. À l'inverse, la méthode "find_all" recherche toutes les balises qui correspondent à l'entrée fournie.
Étape 4 : Utilisez les méthodes "find" et "find_all" pour stocker le code HTML du nom, du classement et de l'année de chaque film dans une variable de type liste.
top_movies = soup_obj.find('div',attrs={'class': 'lister-list'}).find_all('h3')
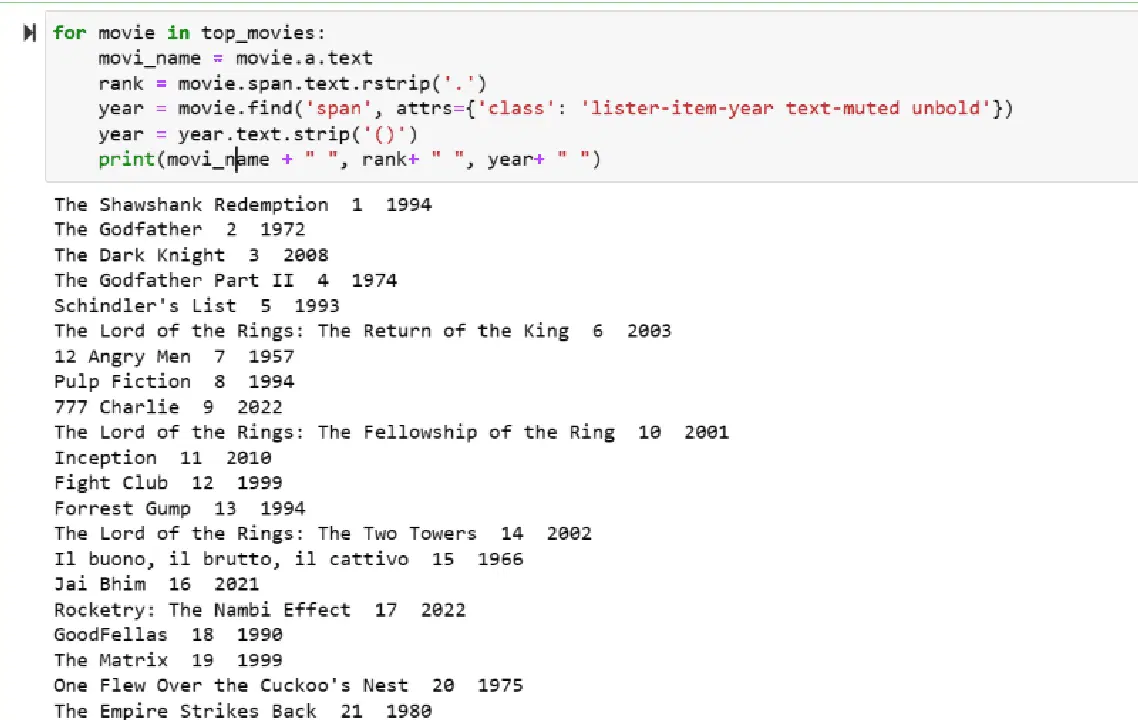
Étape 5 : Parcourez la liste des films stockés dans la variable "top_movies" et extrayez le nom, le classement et l'année de chaque film en format texte, à partir de son code HTML, en utilisant le code ci-dessous.
for movie in top_movies:
movi_name = movie.a.text
rank = movie.span.text.rstrip('.')
year = movie.find('span', attrs={'class': 'lister-item-year text-muted unbold'})
year = year.text.strip('()')
print(movi_name + " ", rank+ " ", year+ " ")
La sortie affiche une liste des films avec leur nom, leur classement et leur année de sortie.
Vous pouvez facilement exporter ces données dans une feuille Excel avec un script Python et les utiliser pour votre analyse.
Conclusion
Cet article vous a guidé à travers l'installation de Beautiful Soup pour le *web scraping*. De plus, les exemples de scraping que nous avons présentés devraient vous aider à démarrer vos propres projets avec Beautiful Soup.
Si l'installation de Beautiful Soup pour le *web scraping* vous intéresse, je vous recommande vivement de consulter un guide plus complet afin d'approfondir vos connaissances en matière de *web scraping* avec Python.