Comment gratter une liste de sujets à partir d'un sous-reddit à l'aide de Bash
Extraire des données de Reddit via des flux JSON avec un script Bash
Reddit met à disposition des flux JSON pour chaque sous-reddit, offrant ainsi une source d'informations précieuse. Ce guide explique comment élaborer un script Bash capable de télécharger et d'analyser une liste de publications à partir de n'importe quel sous-reddit de votre choix. Cette fonctionnalité illustre l'une des nombreuses possibilités qu'offrent les flux JSON de Reddit.
Installation de Curl et JQ
Pour mener à bien cette tâche, nous utiliserons curl pour récupérer les flux JSON de Reddit et jq pour analyser ces données et extraire les champs spécifiques qui nous intéressent. Sur Ubuntu et les distributions Linux basées sur Debian, vous pouvez installer ces deux outils à l'aide d'apt-get. Sur d'autres distributions, adaptez la commande en utilisant le gestionnaire de paquets correspondant à votre système.
sudo apt-get install curl jq
Obtenir des données JSON depuis Reddit
Avant de commencer, examinons de plus près la structure du flux de données. Pour ce faire, employons curl pour récupérer les derniers messages du sous-reddit r/MildlyInteresting :
curl -s -A “outil d'extraction Reddit” https://www.reddit.com/r/MildlyInteresting.json
Analysons les options utilisées avant l'URL : -s force curl à fonctionner en mode silencieux, ne laissant apparaître que les données renvoyées par Reddit. Ensuite, -A "outil d'extraction Reddit" définit un agent utilisateur personnalisé, permettant à Reddit d'identifier le service qui accède aux données. Cette pratique est essentielle, car l'API de Reddit applique des limitations de débit basées sur l'agent utilisateur. En définissant une valeur personnalisée, vous isolez votre limite de débit des autres utilisateurs, réduisant ainsi le risque d'obtenir une erreur HTTP 429 (dépassement de limite de débit).
Le résultat affiché dans votre terminal devrait ressembler à ceci :
La quantité de champs dans les données de sortie peut sembler importante, mais seuls le titre, le lien permanent et l'URL nous concernent. Vous trouverez une description complète des types et de leurs champs sur la page de documentation de l'API Reddit : https://github.com/reddit-archive/reddit/wiki/JSON
Extraction des données pertinentes du flux JSON
Notre objectif est d'extraire le titre, le lien permanent et l'URL des données de sortie et de les sauvegarder dans un fichier séparé par des tabulations. Bien qu'il soit possible d'utiliser des outils de traitement de texte comme sed et grep, nous avons à notre disposition un outil plus adapté aux structures de données JSON : jq. Dans un premier temps, nous allons utiliser jq pour imprimer et coloriser la sortie de manière lisible. Reprenons la commande précédente, en redirigeant la sortie vers jq pour qu'il analyse et affiche les données JSON.
curl -s -A “outil d'extraction Reddit” https://www.reddit.com/r/MildlyInteresting.json | jq .
Notez le point qui suit la commande. Cette simple expression permet à jq d'analyser l'entrée et de l'imprimer telle quelle. La sortie sera alors formatée et colorisée de manière claire et agréable.
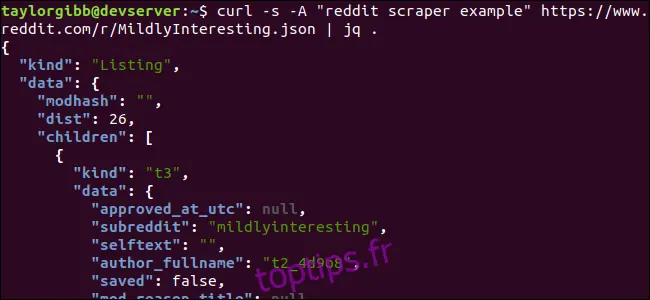
En examinant la structure des données JSON que nous recevons de Reddit, on constate que l'objet racine comporte deux propriétés : kind et data. La propriété data contient une autre propriété nommée children, qui est un tableau contenant les publications du sous-reddit.
Chaque élément de ce tableau est également un objet contenant deux champs, kind et data. Les propriétés que nous souhaitons extraire se trouvent dans l'objet data. jq attend une expression pouvant être appliquée aux données d'entrée et produire le résultat souhaité. Cette expression doit décrire le contenu en termes de hiérarchie et d'appartenance à un tableau, ainsi que la transformation à effectuer sur les données. Exécutons de nouveau la commande avec l'expression correcte :
curl -s -A “outil d'extraction Reddit” https://www.reddit.com/r/MildlyInteresting.json | jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
Le résultat affichera le titre, l'URL et le lien permanent, chacun sur une ligne différente :
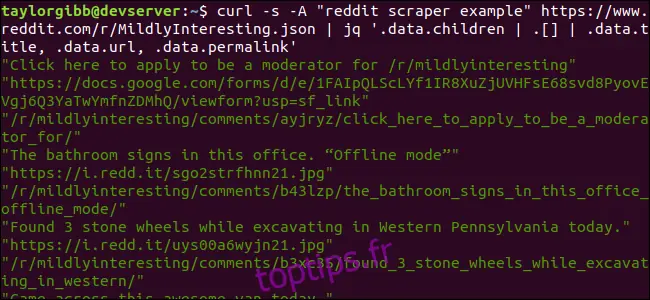
Décortiquons la commande jq que nous avons utilisée :
jq '.data.children | .[] | .data.title, .data.url, .data.permalink'
Cette commande comporte trois expressions séparées par le caractère pipe (|). Le résultat de chaque expression est transmis à la suivante pour être évalué. La première expression filtre tout sauf le tableau des listes Reddit. Cette sortie est envoyée à la deuxième expression qui va la transformer en tableau. La troisième expression agit sur chaque élément du tableau pour extraire les trois propriétés. Pour une compréhension plus approfondie de jq et de sa syntaxe, consultez le manuel officiel de jq.
Assembler le tout dans un script
Intégrons désormais l'appel API et le traitement JSON dans un script qui générera un fichier avec les publications désirées. Nous ajouterons également la capacité de récupérer les messages de n'importe quel sous-reddit, et non seulement /r/MildlyInteresting.
Ouvrez votre éditeur et copiez le code ci-dessous dans un fichier nommé scrape-reddit.sh :
#!/bin/bash
if [ -z "$1" ]
then
echo "Veuillez spécifier un sous-reddit"
exit 1
fi
SUBREDDIT=$1
NOW=$(date +"%m_%d_%y-%H_%M")
OUTPUT_FILE="${SUBREDDIT}_${NOW}.txt"
curl -s -A "script-extraction-bash" https://www.reddit.com/r/${SUBREDDIT}.json |
jq '.data.children | .[] | .data.title, .data.url, .data.permalink' |
while read -r TITLE; do
read -r URL
read -r PERMALINK
echo -e "${TITLE}t${URL}t${PERMALINK}" | tr --delete " >> ${OUTPUT_FILE}
done
Ce script vérifie d'abord si l'utilisateur a spécifié un nom de sous-reddit. Si ce n'est pas le cas, il affiche un message d'erreur et se termine avec un code de retour différent de zéro.
Ensuite, il stocke le premier argument en tant que nom de sous-reddit et crée un nom de fichier horodaté pour enregistrer la sortie.
L'action principale commence avec l'appel à curl, utilisant un en-tête personnalisé et l'URL du sous-reddit cible. La sortie est redirigée vers jq qui analyse et réduit les données aux trois champs désirés : titre, URL et lien permanent. Ces lignes sont lues une par une et stockées dans des variables grâce à la commande read, le tout dans une boucle while qui se poursuit tant qu'il reste des lignes à lire. La dernière ligne de la boucle while affiche les trois champs, séparés par une tabulation, puis les redirige vers la commande tr pour supprimer les guillemets. Enfin, la sortie est ajoutée au fichier.
Avant d'exécuter le script, il faut s'assurer qu'il possède les permissions d'exécution. Utilisez la commande chmod pour appliquer ces autorisations au fichier :
chmod u+x scrape-reddit.sh
Vous pouvez ensuite exécuter le script en fournissant le nom d'un sous-reddit :
./scrape-reddit.sh MildlyInteresting
Un fichier de sortie sera créé dans le même répertoire, et son contenu ressemblera à ceci :
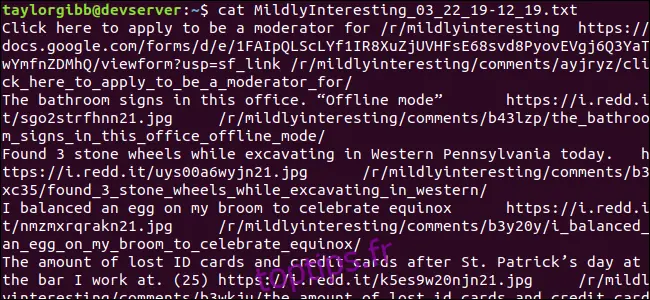
Chaque ligne contient les trois champs que nous souhaitions extraire, séparés par un caractère de tabulation.
Aller plus loin
Reddit est une source inépuisable de contenu et de médias intéressants, tous facilement accessibles grâce à son API JSON. Maintenant que vous disposez d'un moyen d'accéder à ces données et de traiter les résultats, vous pouvez entreprendre des actions telles que :
- Récupérer les titres les plus récents de /r/WorldNews et les afficher sur votre bureau en utilisant notify-send
- Intégrer les meilleures blagues de /r/DadJokes dans le message du jour de votre système.
- Récupérer l'image la plus appréciée de /r/aww et l'utiliser comme fond d'écran.
Toutes ces possibilités sont à votre portée en utilisant les données fournies et les outils disponibles sur votre système. N'hésitez pas à explorer, à expérimenter, et bon développement !