Comment créer un chatbot à l'aide de Streamlit et Llama 2
Llama 2 représente un modèle de langage étendu (MLE) en source ouverte, conçu par Meta. Ce modèle, particulièrement performant, se positionne comme une alternative crédible, voire supérieure, à certains modèles propriétaires tels que GPT-3.5 et PaLM 2. Il se décline en trois versions, variant selon le nombre de paramètres : 7 milliards, 13 milliards et 70 milliards, toutes pré-entrainées et affinées pour la génération de texte.
Nous allons explorer les capacités conversationnelles de Llama 2 en construisant un agent conversationnel, ou chatbot, à l'aide de Streamlit et de Llama 2.
Comprendre Llama 2 : Fonctionnalités et Avantages
En quoi Llama 2 se distingue-t-il de son prédécesseur, le modèle de langage Llama 1 ?
- Modèle de taille accrue : Llama 2 offre des modèles avec un maximum de 70 milliards de paramètres, permettant d'établir des relations plus complexes entre les mots et les phrases.
- Amélioration des capacités conversationnelles : L'apprentissage par renforcement à partir de la rétroaction humaine (RLHF) optimise ses aptitudes pour les interactions conversationnelles, générant un contenu d’apparence humaine, même dans des échanges complexes.
- Inférence plus rapide : Une nouvelle méthode, l'attention aux requêtes groupées, permet d'accélérer le processus d'inférence, ouvrant la voie à des applications pratiques telles que les chatbots et les assistants virtuels.
- Efficacité accrue : Llama 2 est plus efficace en termes d'utilisation de la mémoire et des ressources de calcul que son prédécesseur.
- Licence en source ouverte et non commerciale : Llama 2 est accessible en source ouverte. Cela permet aux chercheurs et développeurs d’utiliser et de modifier ce modèle sans contraintes.
Llama 2 surpasse son prédécesseur dans tous les aspects significatifs. Ces attributs font de ce modèle un outil puissant pour un éventail d'applications comme les chatbots, les assistants virtuels et la compréhension du langage naturel.
Mise en place d'un environnement Streamlit pour le développement de chatbot
Avant de commencer le développement de votre application, vous devez configurer un environnement de développement isolé afin d'éviter les conflits avec d'autres projets sur votre machine.
Pour commencer, créez un environnement virtuel en utilisant la bibliothèque Pipenv de cette manière :
pipenv shell
Ensuite, installez les bibliothèques nécessaires à la création du chatbot :
pipenv install streamlit replicate
Streamlit est un framework d'applications web open source qui permet de déployer rapidement des applications de science des données et d’apprentissage automatique.
Replicate est une plateforme cloud qui donne accès à des modèles d'apprentissage automatique en source ouverte pour le déploiement.
Obtenir votre jeton API Llama 2 à partir de Replicate
Pour obtenir un jeton API de Replicate, vous devez d'abord créer un compte sur Replicate en utilisant votre compte GitHub.
Une fois connecté, accédez au bouton "Explorer" et recherchez "Llama 2 Chat" pour trouver le modèle "llama-2-70b-chat".
Cliquez sur le modèle "llama-2-70b-chat" pour afficher les points d'accès à l'API Llama 2. Cliquez ensuite sur le bouton "API" dans la barre de navigation. Sur la partie droite de la page, sélectionnez l'onglet "Python". Cela vous donnera accès au jeton API pour les applications Python.
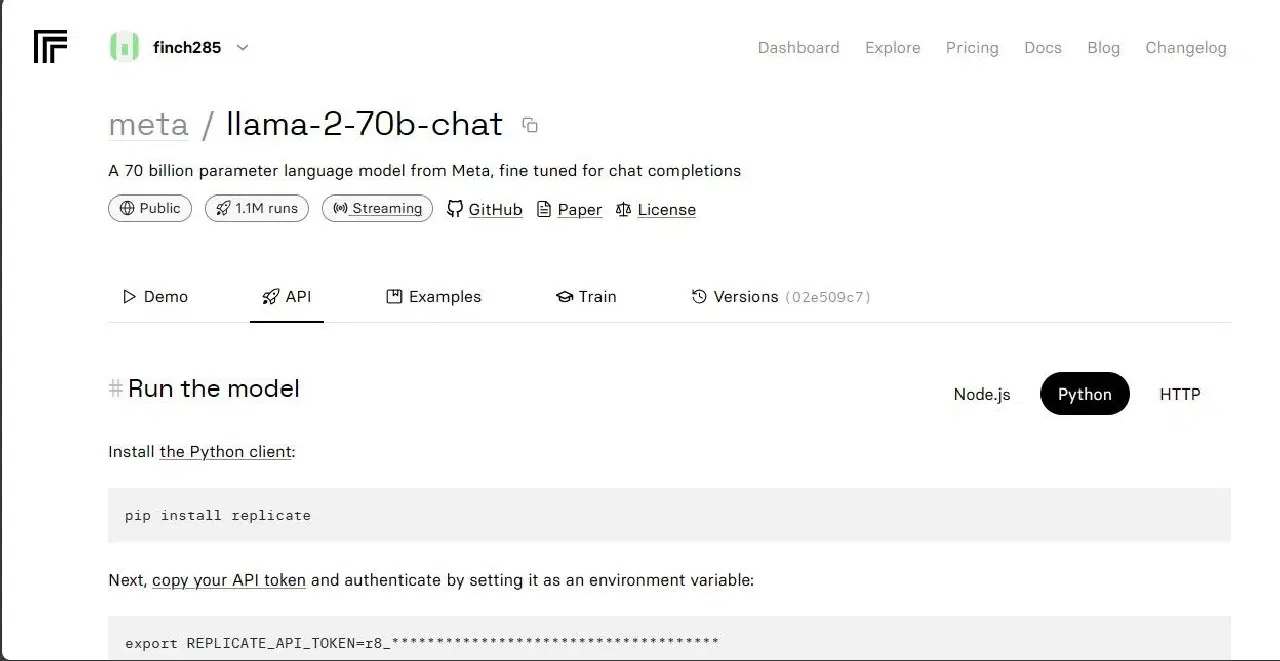
Copiez le `REPLICATE_API_TOKEN` et conservez-le en lieu sûr pour une utilisation ultérieure.
Construction du Chatbot
Commencez par créer un fichier Python nommé `llama_chatbot.py` et un fichier `.env`. Votre code sera écrit dans `llama_chatbot.py`, et vos clés secrètes et jetons API seront stockés dans le fichier `.env`.
Dans le fichier `llama_chatbot.py`, importez les bibliothèques comme ceci :
import streamlit as st
import os
import replicate
Définissez ensuite les variables globales pour le modèle `llama-2-70b-chat` :
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
Dans le fichier `.env`, ajoutez le jeton Replicate et les points d'accès du modèle au format suivant :
REPLICATE_API_TOKEN='Votre_Jeton_Replicate'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Remplacez `Votre_Jeton_Replicate` par votre jeton et enregistrez le fichier `.env`.
Conception du flux conversationnel du chatbot
Créez une invite pré-définie pour initialiser le modèle Llama 2 en fonction de la tâche que vous souhaitez qu’il effectue. Dans ce cas, nous voulons que le modèle agisse comme un assistant.
PRE_PROMPT = "Vous êtes un assistant serviable. Ne répondez jamais en tant que 'Utilisateur' et ne faites pas semblant d'être l' 'Utilisateur'. " \
"Répondez uniquement en une seule fois comme Assistant."
Configurez les paramètres de la page pour votre chatbot comme ceci :
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Écrivez une fonction pour initialiser et configurer les variables d'état de la session :
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choisissez un modèle LLaMA2 :', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Cette fonction définit des variables clés telles que `chat_dialogue`, `pre_prompt`, `llm`, `top_p`, `max_seq_len` et `temperature` dans l'état de la session. Elle gère également la sélection du modèle Llama 2 en fonction du choix de l'utilisateur.
Créez une fonction pour afficher le contenu de la barre latérale dans l'application Streamlit :
def render_sidebar():
st.sidebar.header("Chatbot LLaMA2")
st.session_state['temperature'] = st.sidebar.slider('Température :',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P :', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Longueur maximale de la séquence :',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Invite avant le début du chat. Modifier ici si souhaité :',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Cette fonction affiche l'en-tête et les options de réglage du chatbot Llama 2 pour les ajustements.
Écrivez la fonction qui affiche l'historique des discussions dans la zone de contenu principale de l'application Streamlit :
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
La fonction parcourt le `chat_dialogue` enregistré dans l'état de la session, en affichant chaque message avec son rôle correspondant (utilisateur ou assistant).
Gérez la saisie de l'utilisateur avec la fonction ci-dessous :
def handle_user_input():
user_input = st.chat_input(
"Saisissez votre question ici pour parler à LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Cette fonction fournit à l'utilisateur un champ de saisie où il peut entrer ses messages et questions. Le message est ajouté au `chat_dialogue` dans l'état de la session avec le rôle "utilisateur" après sa soumission.
Créez une fonction qui génère des réponses du modèle Llama 2 et les affiche dans la zone de discussion :
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "Utilisateur" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Cette fonction crée une chaîne d'historique de conversation comprenant les messages de l'utilisateur et de l'assistant, puis appelle la fonction `debounce_replicate_run` pour obtenir la réponse de l'assistant. Elle met à jour dynamiquement la réponse dans l'interface utilisateur pour une expérience de chat en temps réel.
Créez une fonction principale pour gérer l'affichage de l'intégralité de l'application Streamlit :
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Cette fonction appelle toutes les fonctions précédemment définies pour configurer l'état de la session, afficher la barre latérale, l'historique des discussions, gérer la saisie de l'utilisateur et générer les réponses de l'assistant dans un ordre logique.
Créez une fonction pour appeler la fonction `render_app` et démarrer l'application lorsque le script est exécuté :
def main():
render_app()if __name__ == "__main__":
main()
Votre application est maintenant prête à être exécutée.
Gestion des requêtes API
Créez un fichier `utils.py` dans le répertoire de votre projet et ajoutez la fonction suivante :
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("Heure du dernier appel : ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Anti-rebond activé")
return "Bonjour ! Vos requêtes sont trop rapides. Veuillez patienter quelques secondes avant d'envoyer une nouvelle requête."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Cette fonction met en œuvre un mécanisme d'anti-rebond pour éviter les requêtes API fréquentes et excessives provenant de l'utilisateur.
Ensuite, importez la fonction d'anti-rebond dans votre fichier `llama_chatbot.py` comme suit :
from utils import debounce_replicate_run
Exécutez maintenant l'application :
streamlit run llama_chatbot.py
Résultat attendu :
Le résultat montre une conversation entre le modèle et un humain.
Applications concrètes des Chatbots Streamlit et Llama 2
Voici quelques applications concrètes de Llama 2 :
- Chatbots : Il peut servir à la création de chatbots aux réponses semblables à celles d’humains, capables de tenir des conversations en temps réel sur divers sujets.
- Assistants virtuels : Llama 2 peut être utilisé pour développer des assistants virtuels qui comprennent et répondent aux questions en langage naturel.
- Traduction linguistique : Son utilisation est appropriée pour les tâches de traduction linguistique.
- Résumé de texte : Il peut résumer des textes volumineux en textes plus courts pour une compréhension facilitée.
- Recherche : Llama 2 est applicable dans le domaine de la recherche en répondant à des questions sur un grand éventail de sujets.
L’avenir de l’IA
Avec des modèles fermés tels que GPT-3.5 et GPT-4, il est difficile pour les plus petites organisations de créer des applications significatives à l'aide de modèles de langage, en raison du coût élevé de l'accès à l'API du modèle GPT.
L'ouverture de modèles de langage avancés comme Llama 2 à la communauté des développeurs marque le début d'une nouvelle ère pour l'IA. Cela favorisera une mise en œuvre plus créative et novatrice de ces modèles dans des applications concrètes, stimulant une course accélérée vers la super intelligence artificielle (ASI).