Ce que vous ne saviez pas sur AWS Glue
La popularité d'Amazon Glue ne cesse de croître, car de plus en plus d'entreprises adoptent des services d'intégration de données gérés.
Le processus ETL, consistant à transférer des données d'une source vers un entrepôt, est reconnu pour sa complexité, notamment lorsqu'il s'agit de gérer de gros volumes de données d'entreprise. C'est pourquoi Amazon a mis en place AWS Glue, pour simplifier cette tâche.
Développeurs ETL et ingénieurs de données s'appuient sur Glue pour la création, la surveillance et l'exécution de leurs flux de travail ETL.
Qu'est-ce qu'AWS Glue ?
AWS Glue, un service d'intégration de données sans serveur, facilite la découverte, la préparation, le déplacement et l'intégration de données issues de diverses sources. Il est particulièrement utile pour l'apprentissage automatique (ML) et l'analyse.
Ce service réduit considérablement le temps nécessaire à la préparation des données pour l'analyse. Il automatise la découverte et le catalogage des données, génère du code en Scala ou Python pour le transfert depuis la source, et prend en charge le chargement et la transformation des données en fonction d'événements planifiés.
Glue permet une planification flexible et fournit un environnement Apache Spark adaptable pour le chargement de données. De plus, AWS Glue offre une surveillance et une modification sophistiquée des flux de données. Ce service sans serveur simplifie grandement le développement d'applications complexes.
Il permet une intégration rapide de multiples données validées, tout en assurant une décomposition et une autorisation efficaces des données.
À quoi sert AWS Glue ?
Il est essentiel de connaître les cas d'utilisation optimum d'Amazon Glue. Voici quelques exemples de situations où son utilisation est particulièrement pertinente :
- Glue permet d'effectuer des requêtes sans serveur sur les lacs de données Amazon S3. C'est un outil excellent pour débuter, car il centralise l'accès à toutes vos données sur une seule interface, facilitant ainsi leur analyse sans nécessiter de déplacement.
- Amazon Glue est utile pour une meilleure compréhension de vos actifs de données. Son catalogue de données permet de parcourir facilement différents ensembles de données AWS. Vous pouvez également enregistrer des données provenant de divers services AWS tout en conservant une vue cohérente grâce à ce catalogue.
- Glue est précieux lors de la création de workflows ETL basés sur des événements. Vous pouvez lancer des opérations ETL depuis Amazon S3 en déclenchant vos tâches ETL Glue via un service AWS Lambda.
- AWS Glue est également efficace pour le nettoyage, la validation, le formatage et l'organisation des données en vue de leur stockage dans un lac de données ou un entrepôt.
Quels sont les composants d'AWS Glue ?
Voici les principaux composants d'AWS Glue :
- Catalogue de données : Ce catalogue centralise les métadonnées et la structure des données.
- Base de données : Il s'agit du point d'accès pour créer et gérer les bases de données pour les sources et les cibles.
- Table : Une ou plusieurs tables sont créées dans la base de données, utilisables à la fois par la source et la cible.
- Robot d'exploration et classificateur : Le robot d'exploration extrait les données de la source en utilisant des classifications intégrées ou personnalisées. Il crée ou utilise des tables de métadonnées prédéfinies dans le catalogue de données.
- Travail : Il s'agit du travail de la logique métier pour effectuer une tâche ETL. Cette logique est écrite en interne par Apache Spark à l'aide des langages Python et Scala.
- Déclencheur : Un déclencheur ETL initie l'exécution d'une tâche ETL, soit à la demande, soit à un moment planifié.
- Point de terminaison pour le développement : Il fournit un environnement pour tester, développer et déboguer les scripts de travail ETL.
Avantages d'AWS Glue
Voici les avantages majeurs de l'intégration d'AWS Glue dans votre environnement professionnel ou votre organisation :
- AWS Glue effectue l'analyse de toutes les données disponibles grâce à un analyseur performant.
- Les données traitées peuvent être stockées à divers emplacements (Amazon RDS, Amazon Redshift, Amazon S3, etc.).
- En tant que service cloud, il élimine les dépenses liées aux infrastructures sur site.
- C'est une solution rentable grâce à son approche ETL sans serveur.
- La rapidité est un atout, car il fournit instantanément le code ETL en Python/Scala.
Principales fonctionnalités d'AWS Glue ?
Amazon Glue offre toutes les fonctionnalités nécessaires à l'intégration de données, permettant d'obtenir de meilleures informations et de progresser plus rapidement. Voici quelques fonctionnalités clés à connaître :
- Interface glisser-déposer : Un éditeur de tâches intuitif permet de concevoir des processus ETL. AWS Glue génère automatiquement le code nécessaire pour l'extraction, la transformation et le chargement des données.
- Découverte automatique de schéma : Le service Glue permet de créer des robots d'exploration qui se connectent à diverses sources de données. Il organise les données et extrait les informations pertinentes, qui peuvent être utilisées pour surveiller les processus ETL via des tâches.
- Planification des travaux : Glue peut être utilisé à la demande ou selon un calendrier programmé. Le planificateur permet la création de pipelines ETL complexes, établissant des dépendances entre les tâches.
- Génération de code : Glue Elastic Views facilite la création de vues matérialisées, combinant et répliquant des données provenant de différentes sources sans codage personnalisé.
- Apprentissage automatique intégré : Glue inclut une fonction d'apprentissage automatique nommée "FindMatches", qui permet de dédupliquer des enregistrements même s'ils ne sont pas des copies exactes.
- Points de terminaison de développeur : Pour un développement actif du code ETL, Glue propose des points de terminaison qui permettent de modifier, déboguer et tester le code généré.
- Glue DataBrew : Cet outil de préparation de données permet aux analystes et data scientists de nettoyer et normaliser les données. Il utilise une interface visuelle et interactive.
Comment fonctionne la tarification AWS Glue ?
AWS Glue fonctionne avec une facturation horaire, calculée à la seconde pour les robots d'exploration (découverte des données) et les tâches ETL (traitement et chargement). Un forfait mensuel simple couvre l'accès et le stockage des métadonnées dans le catalogue de données AWS Glue.
Les tarifs d'Amazon Glue commencent à 0,44 $. Vous avez le choix entre quatre forfaits :
- Les tâches ETL, les points de terminaison de développement et d'autres tâches ETL sont à 0,44 $.
- Les sessions interactives des robots d'exploration sont également à 0,44 $.
- Les travaux DataBrew commencent à 0,48 $.
- Le stockage mensuel et les demandes au catalogue de données coûtent 1,00 $.
Il n'existe pas de forfait gratuit pour Glue. Chaque heure coûte 0,44 $ par DPU. En moyenne, cela représente un coût de 21 $ par jour. Ces prix peuvent varier selon la région.
Étapes pour configurer AWS Glue
Le catalogue de données facilite la localisation et la recherche de divers ensembles de données AWS sans qu'il soit nécessaire de déplacer les données. Une fois cataloguées, les données sont immédiatement accessibles pour des requêtes et des analyses via Amazon Athena et Amazon EMR.
Réf : https://aws.amazon.com/glue/
- Découvrez vos données provenant d'Amazon Redshift, Amazon S3, Amazon RDS, et de bases de données sur Amazon EC2. Stockez les métadonnées dans le catalogue de données AWS Glue.
- Le catalogue de données AWS Glue centralise la gestion des données en agissant comme un référentiel central pour les métadonnées.
- AWS Glue ETL permet de lire et écrire des métadonnées dans votre catalogue de données.
- Utilisez le catalogue de données pour l'ETL, l'analyse et plus encore, avec Amazon Athena, Amazon Redshift, Amazon EMR et Amazon ETL.
Comment configurer AWS Glue ?
Tout d'abord, connectez-vous à la console de gestion AWS et ouvrez la console IAM. Cliquez sur "Créer un rôle". Ensuite, choisissez "Glue" pour le type de rôle et sélectionnez les autorisations.
Nous choisissons "AWSGlueServiceRole" pour les autorisations générales d'AWS Glue Studio et AWS Glue, ainsi que la stratégie gérée par AWS "AmazonS3FullAccess" pour l'accès aux ressources Amazon S3.
Donnez un nom à votre rôle.
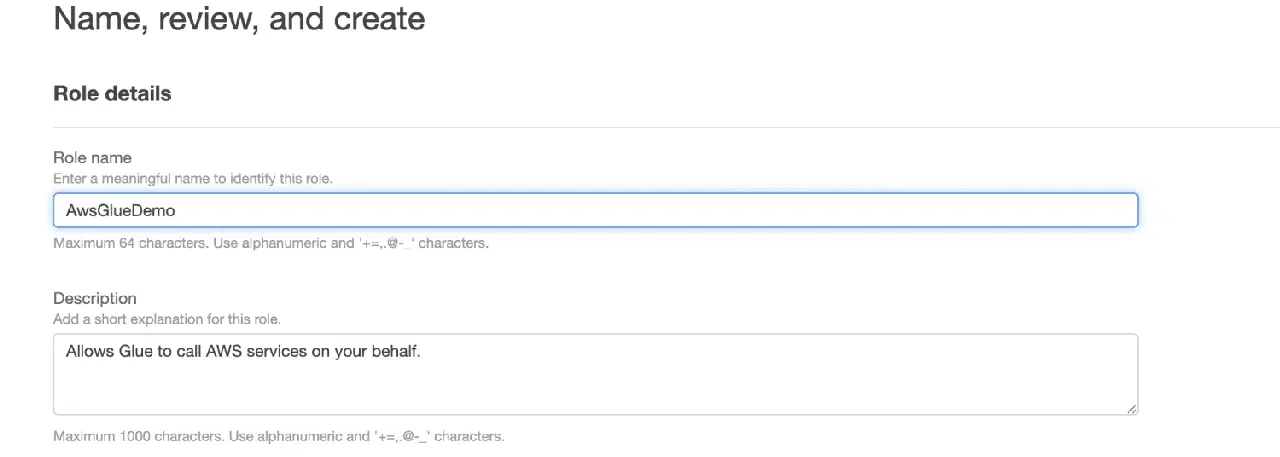
Cliquez sur "Créer un rôle".
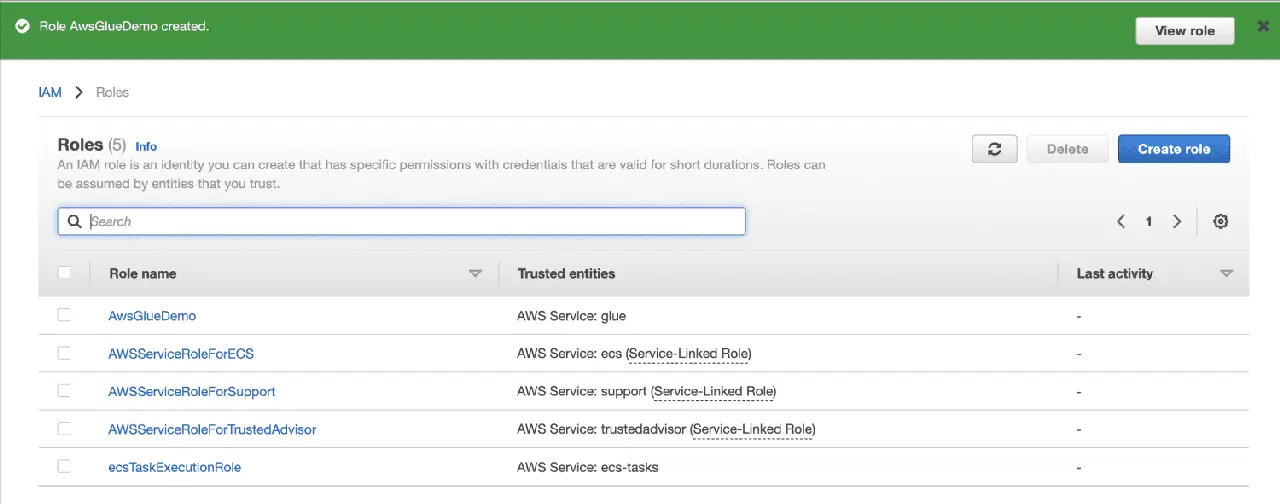
Créez un compartiment Amazon S3.
Créez un dossier dans votre compartiment S3.
Sélectionnez le fichier à télécharger.
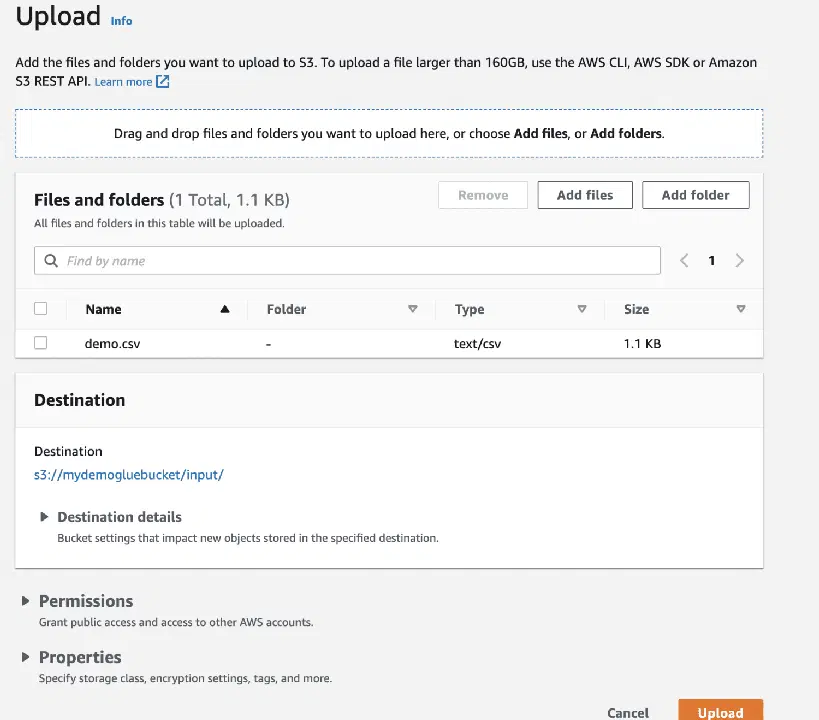
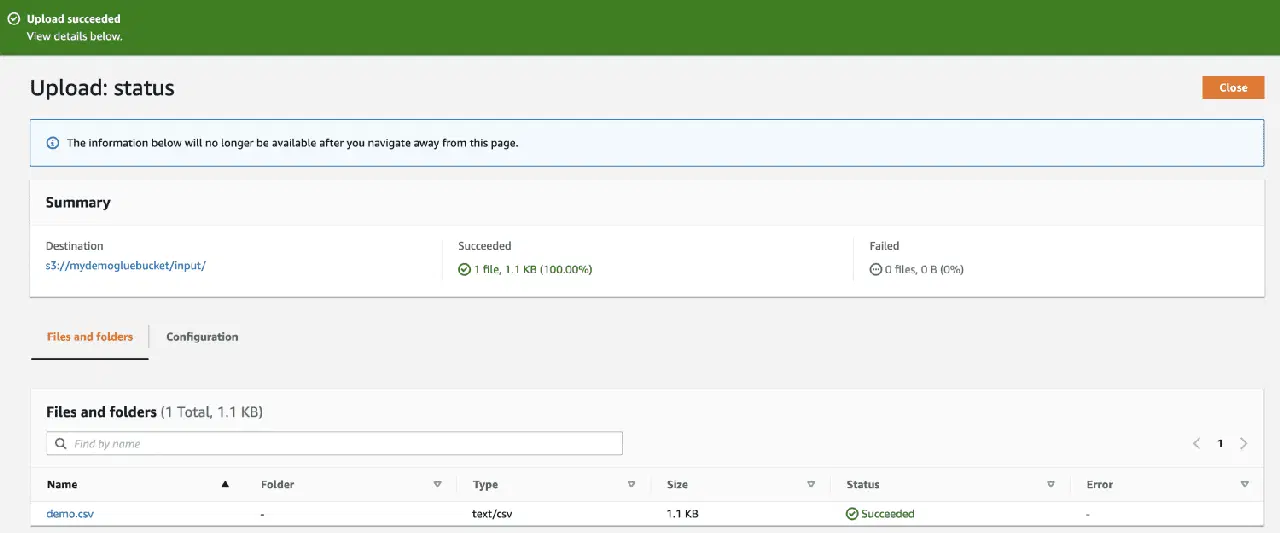
Téléchargez enfin le fichier dans le compartiment.
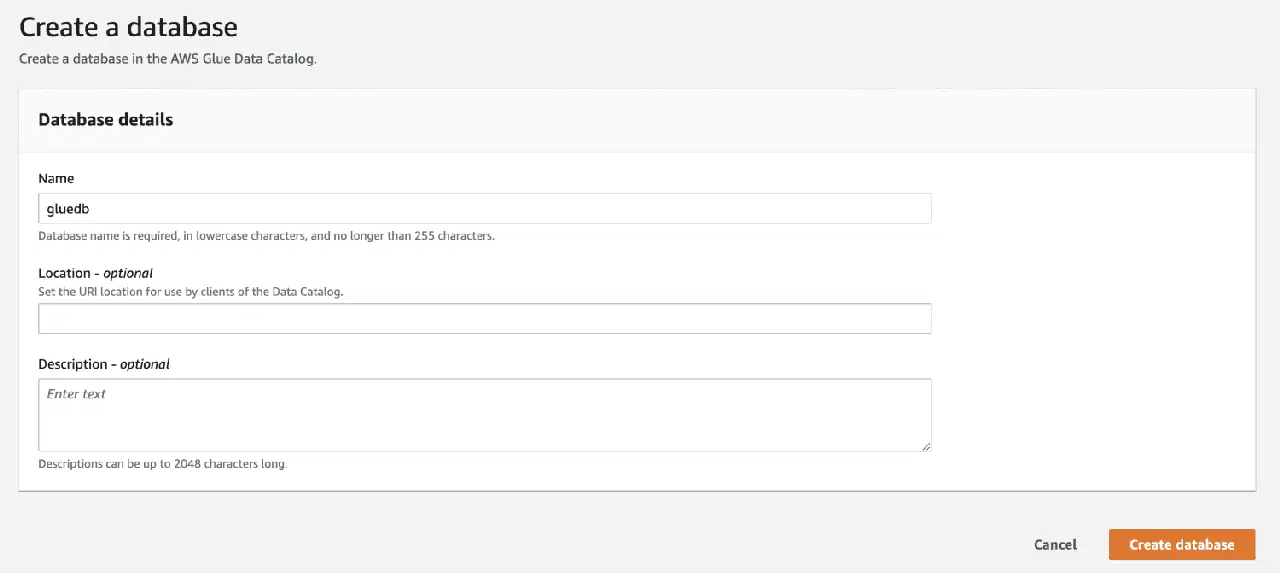
Ensuite, ouvrez AWS Glue depuis la console de gestion AWS et créez une base de données.
Maintenant que vous avez une base de données dans AWS Glue, créez un analyseur.
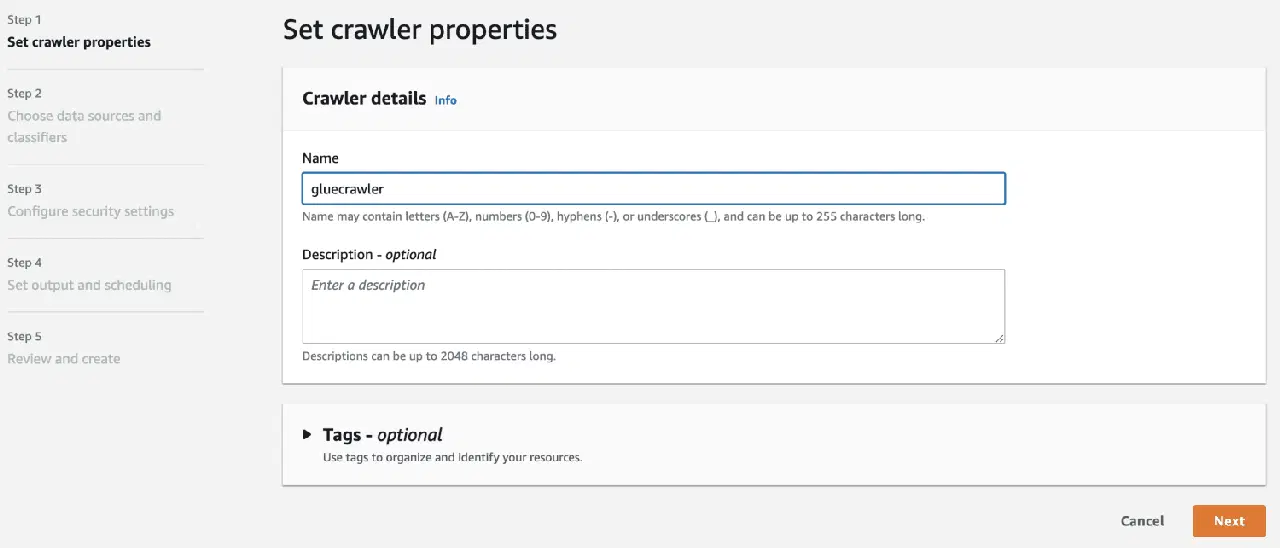
Dans la source de données, sélectionnez le compartiment S3 que vous avez créé.
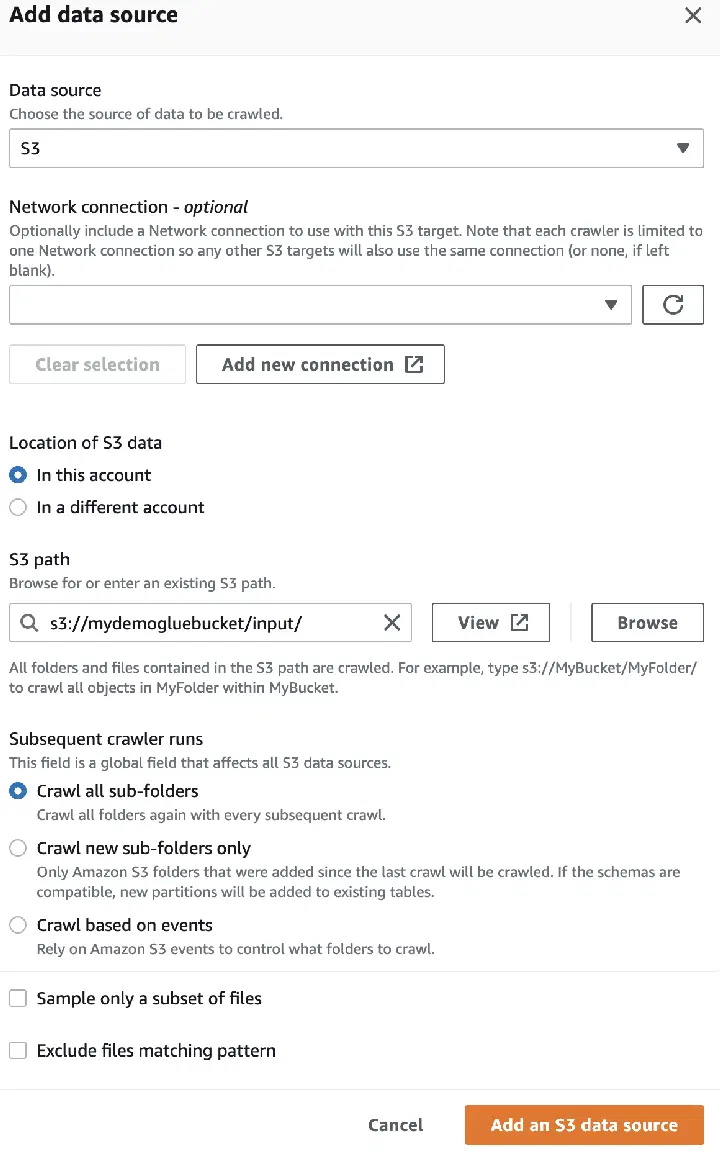
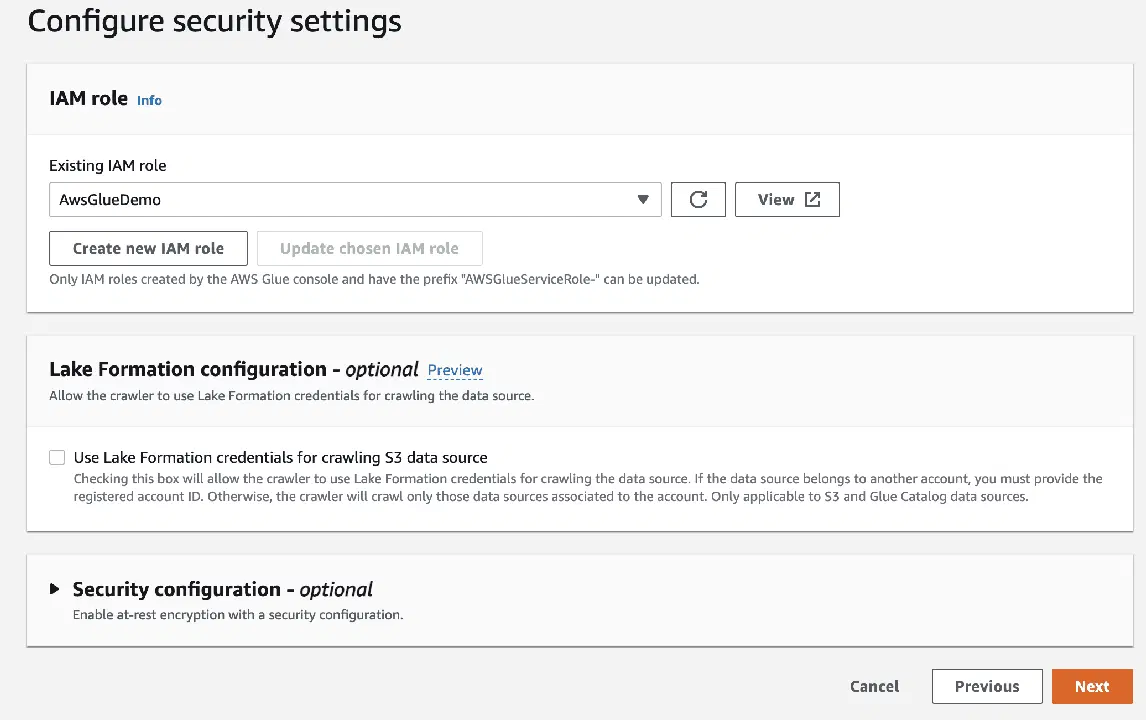
Puis sélectionnez le rôle IAM pour AWS Glue que vous avez créé précédemment.
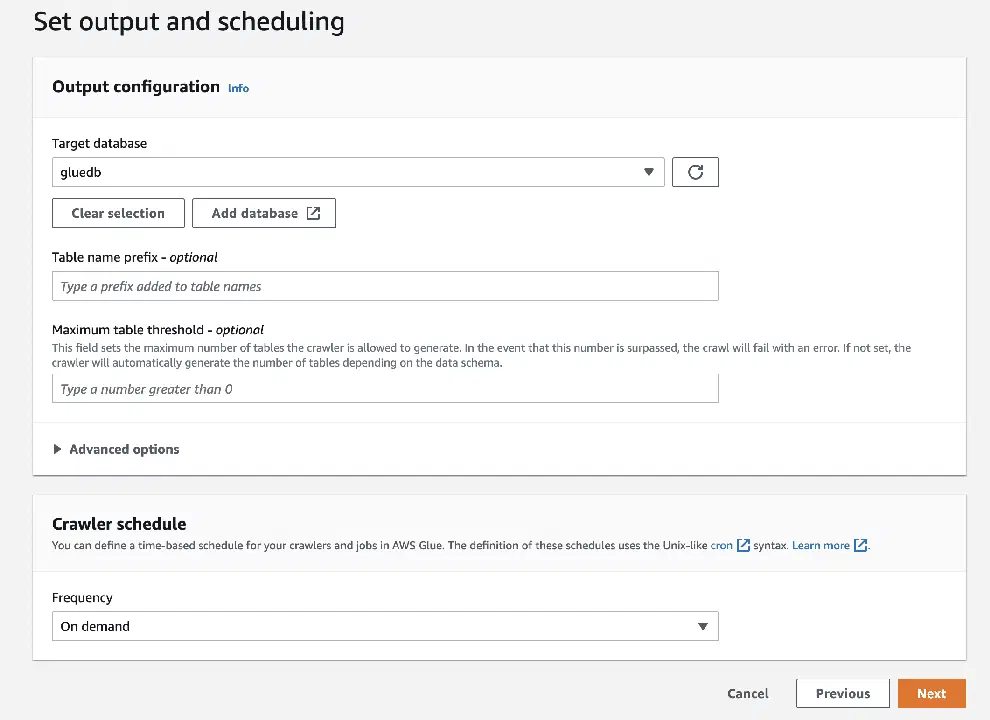
Enfin, dans la sortie, choisissez la base de données "gluedb" que vous avez créée.
Vérifiez tous les paramètres et créez le robot d'exploration.
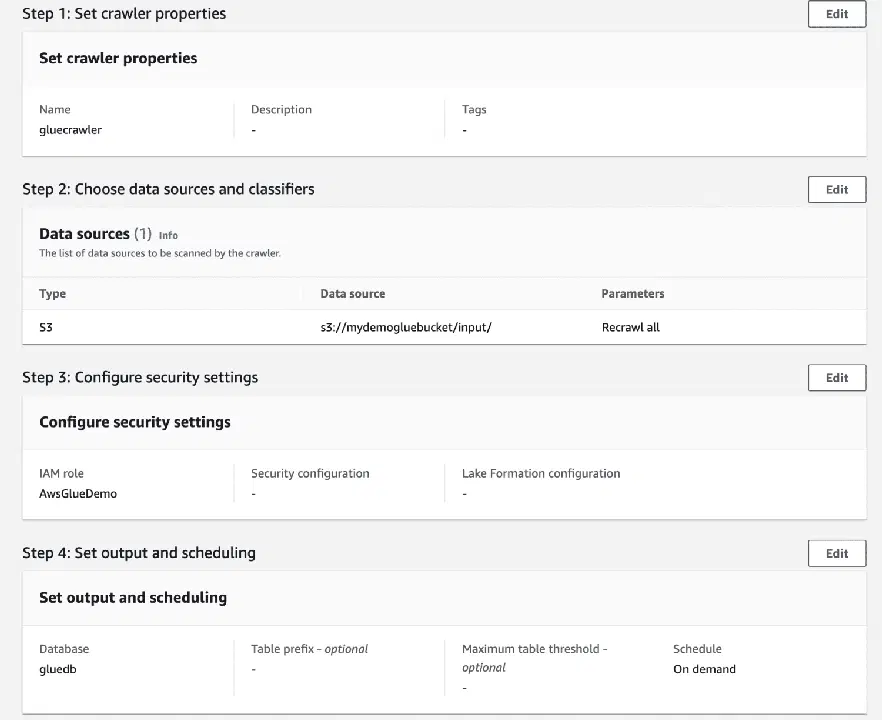
Une fois le robot créé, sélectionnez-le et cliquez sur "Exécuter". Après un certain temps, son statut deviendra "prêt".
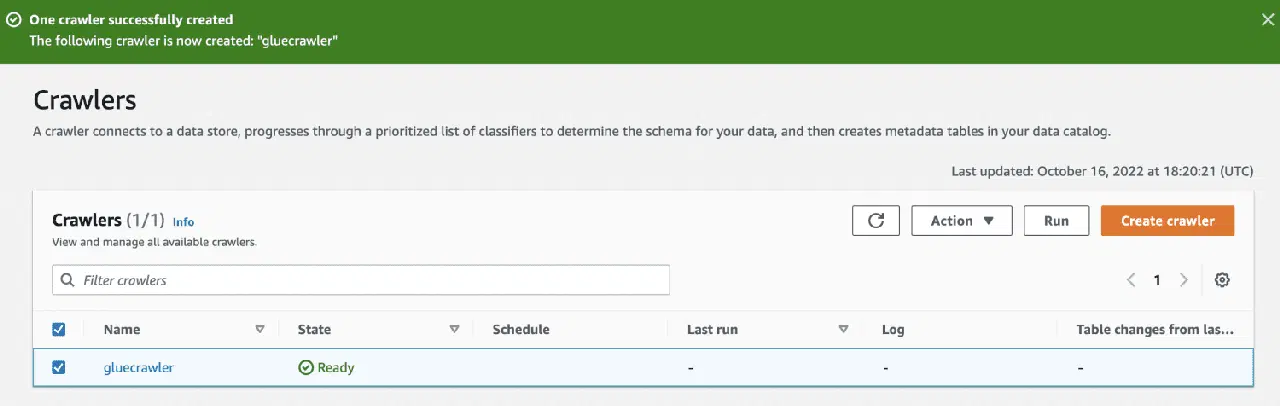
En exécutant le robot, la base de données inclura une table avec toutes les données du fichier CSV.
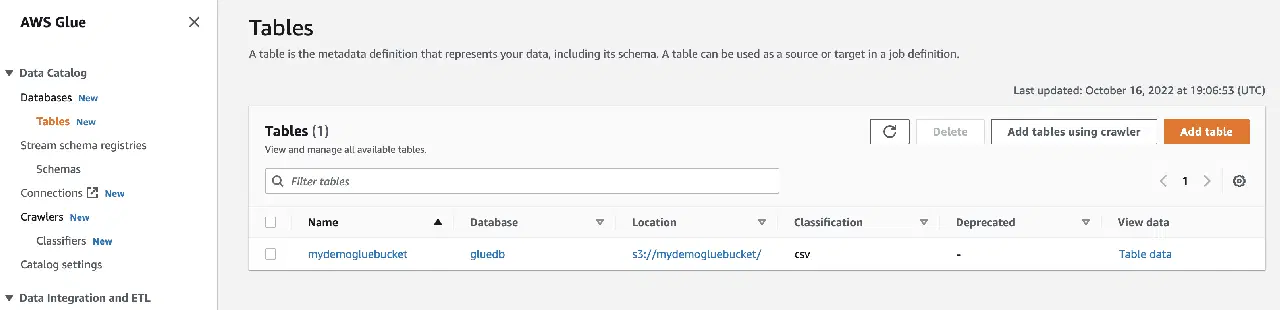
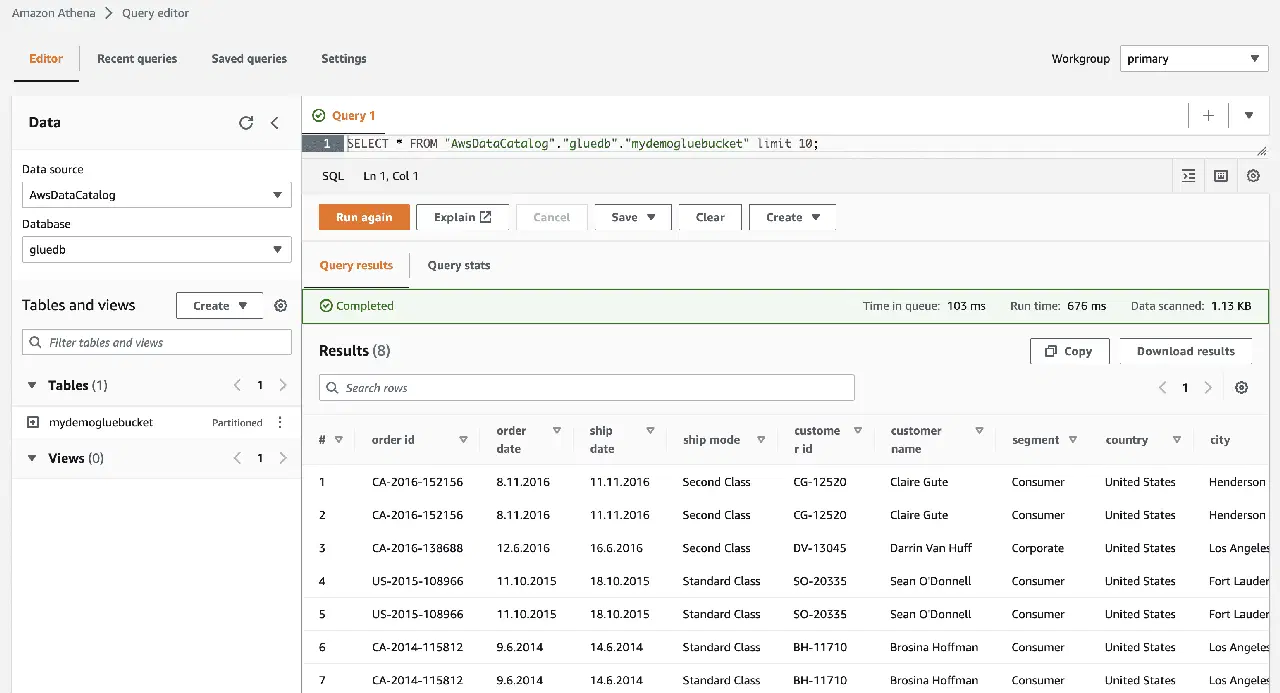
En cliquant sur "afficher les données", vous serez redirigé vers Amazon Athena (éditeur de requête). L'exécution de la requête vous permettra de visualiser les données de la table.
Votre robot d'exploration AWS Glue est maintenant configuré et prêt à être utilisé dans toute tâche ETL.
Qu'est-ce qu'AWS Glue Databrew ?
AWS Glue DataBrew permet aux utilisateurs de normaliser et de nettoyer les données sans écrire de code. DataBrew peut réduire jusqu'à 80% le temps de préparation des données pour l'apprentissage automatique et l'analyse, comparativement aux méthodes de développement sur mesure.
Il propose plus de 250 transformations de données prédéfinies, utiles pour automatiser des tâches telles que le filtrage des anomalies, la correction des valeurs incorrectes et la conversion de données dans des formats standard.
DataBrew facilite la collaboration entre scientifiques des données, analystes métier et ingénieurs pour extraire des informations à partir de données brutes. DataBrew étant sans serveur, il n'est pas nécessaire de gérer l'infrastructure ou de créer des clusters pour explorer et transformer des téraoctets de données brutes.
Fonctionnalités DataBrew pour les entreprises
Préparation des données visualisée
DataBrew offre une représentation visuelle des données, habituellement affichées sous forme de colonnes de nombres et de lettres dans les bases de données. DataBrew visualise toutes les sources de données chargées afin d'aider à comprendre les relations et la hiérarchie des données.
Plus de 250 automatisations de préparation de données
Les scientifiques de données doivent souvent effectuer des workflows reproductibles et isolés. AWS a modélisé ces workflows et processus sous forme de modules indépendants du langage et des données. Cette bibliothèque contient des actions utilisables par les utilisateurs finaux.
Lignage des données
À l'image des journaux d'audit qui suivent l'activité des clients dans un réseau informatique, le lignage des données permet de suivre les opérations de transformation des données dans AWS DataBrew. Ces informations incluent la source des données, les transformations appliquées et les données de sortie, y compris l'emplacement de destination.
Correspondance des données
DataBrew permet d'identifier les champs correspondants dans deux sources de données. Une fois identifiés, ces champs peuvent être chargés dans un schéma.
AWS Glue DataBrew : avantages
Voici les avantages d'AWS Glue DataBrew :
- Réduction des barrières à l'entrée pour la préparation des données
- Génération automatisée de profils de données
- Automatisation de plus de 250 processus de préparation de données
- Suggestions prescriptives intelligentes
Alternatives à AWS Glue
Airflow

Airflow appartient à la catégorie des gestionnaires de workflow. C'est un outil open source, qui bénéficie d'une communauté active sur GitHub. Airflow permet de créer des workflows via des graphes acycliques dirigés (DAG). Le planificateur Airflow exécute les tâches en utilisant un ensemble de travailleurs et en suivant les dépendances spécifiées.
Matillion

Matillion ETL est un outil ETL/ELT conçu pour les plateformes de bases de données cloud telles qu'Amazon Redshift et Google BigQuery. Il dispose d'une interface utilisateur moderne basée sur navigateur, avec de puissantes fonctionnalités ETL/ELT push-down. Sa configuration rapide permet une mise en route en quelques minutes.
Stitch
Stitch est un service ETL open source qui connecte de nombreuses sources de données et les réplique vers les destinations choisies. Il est simple d'utilisation car aucun codage n'est requis pour déplacer des données entre les sources et les destinations. Son interface graphique conviviale le rend rapide et accessible.
Contrairement à d'autres outils ETL, Stitch ne propose pas de tableau de bord prédéfini. Il est nécessaire d'intégrer les données dans des entrepôts de données ouverts. La navigation dans les inventaires peut parfois s'avérer complexe.
Alteryx

Alteryx est une plateforme d'automatisation analytique qui facilite la préparation et le mélange de données. Ces données peuvent être utilisées pour accélérer les processus et obtenir des informations commerciales. Grâce à son interface de type glisser-déposer, aucune connaissance en programmation n'est nécessaire. Alteryx offre un bon espace pour échanger avec des professionnels du secteur.
Conclusion
Ce texte a présenté AWS Glue, une solution cloud pour la gestion des pipelines ETL. En résumé, l'interaction utilisateur avec AWS Glue se déroule en trois phases : d'abord, la création d'un catalogue de données à l'aide de robots d'exploration ; ensuite, la création du code ETL pour le pipeline de données ; et enfin, la planification de l'ETL. J'espère que ce billet de blog vous a donné un bon aperçu d'Amazon Glue.
N'hésitez pas à explorer les meilleures pratiques pour sécuriser le stockage AWS S3.