Bright Data Collector facilite le scraping Web [No-Code Solution]
L'Extraction de Données Web : Une Nécessité pour les Entreprises Modernes
De nombreuses entités recourent au *web scraping* pour extraire des informations disponibles en ligne. Ces données sont ensuite organisées et analysées afin d'optimiser leurs activités commerciales.
Cependant, effectuer cette opération manuellement, en parcourant un grand nombre de sites et en collectant des données en continu, peut s'avérer fastidieux et risqué.
En effet, vous pourriez rencontrer des blocages géographiques ou être banni des sites web, car chaque entité souhaite protéger ses données.
C'est pourquoi l'utilisation d'un outil spécifique, comme un collecteur de données, peut être une alternative judicieuse.
Un bon collecteur de données vous permettra de récupérer les informations de manière rapide, sécurisée et fiable. Ainsi, vous pourrez utiliser des données de qualité pour effectuer des prédictions, optimiser vos processus et améliorer vos opérations.
Dans cet article, nous allons explorer la notion de collecte de données, ses différentes approches et techniques, et nous vous présenterons quelques-uns des meilleurs outils disponibles.
Entamons notre discussion !
Qu'est-ce que la Collecte de Données ?
La collecte de données est un processus consistant à rassembler et analyser des informations spécifiques pour répondre à des questions et évaluer des résultats. L'objectif est d'obtenir une compréhension exhaustive d'un sujet donné. Une fois les données collectées, elles sont soumises à des tests d'hypothèses afin d'expliquer un phénomène ou un événement.
La collecte de données peut être motivée par diverses raisons, comme la prévision de tendances ou de probabilités futures.
Le collecteur de données est l'outil qui facilite ce processus. Il offre des fonctionnalités et des avantages significatifs pour simplifier l'ensemble de la procédure de collecte.
Les Différentes Approches de Collecte de Données
La collecte de données se divise en deux grandes catégories : la collecte de données primaires et secondaires.
Collecte de Données Primaires

La collecte de données primaires implique l'obtention de données brutes à la source, que ce soit par le *web scraping*, des études ou tout autre objectif spécifique. Elle se subdivise en deux types :
- Collecte de données quantitatives: De nombreuses méthodes sont utilisées pour la collecte de données quantitatives, comme les sondages téléphoniques, par e-mail, en ligne ou en face à face. Ces méthodes nécessitent un calcul mathématique pour être interprétées et sont présentées sous forme de chiffres. Des exemples incluent les questionnaires avec des questions fermées, les régressions, les médianes, les moyennes et les modes.
- Recherche qualitative: Cette approche ne nécessite pas de calculs mathématiques ni de données chiffrées. Elle se base sur des éléments non quantifiables comme les émotions ou les sentiments du chercheur. Les techniques peuvent inclure des questionnaires ouverts, des entretiens approfondis, des enquêtes en ligne et les données collectées à partir de communautés virtuelles, de forums, de groupes de discussion, etc.
Collecte de Données Secondaires
La collecte de données secondaires repose sur l'utilisation d'informations déjà collectées par une autre entité que l'utilisateur final. Cela signifie que l'on exploite des données existantes issues de livres publiés, de portails en ligne, de revues spécialisées, etc. Cette méthode est plus simple et moins onéreuse.
Dans ce type de collecte, vous accédez à des informations déjà analysées par d'autres. La collecte de données secondaires englobe deux types de données :
- Données publiées : Cela peut inclure les publications gouvernementales, les podcasts, les sites web, les documents publics, les documents statistiques et historiques, les revues spécialisées, les rapports techniques, les documents commerciaux, etc.
- Données non publiées : Il s'agit notamment de lettres, de journaux intimes et de biographies non publiées.
Le choix entre les données primaires et secondaires dépend de votre domaine de recherche spécifique, du type de marché, des opportunités, de l'objectif du projet, etc. Choisissez l'approche la plus adaptée pour prendre des décisions éclairées.
Avantages d'un Outil de Collecte de Données
Comme mentionné précédemment, un outil de collecte de données est un logiciel utilisé pour collecter des informations par le biais de questionnaires papier, d'enquêtes, d'études de cas, de recherches, d'observations, etc.
Puisqu'une étude, une analyse, une recherche ou un *web scraping* sont effectués dans divers objectifs, il est essentiel de garantir la collecte de données authentiques et de qualité afin d'obtenir des solutions crédibles à un problème. C'est là que l'utilisation d'un bon outil de collecte devient indispensable. Il offre de nombreuses fonctionnalités et avantages pour simplifier le processus et le rendre plus efficace.
Voici quelques avantages à utiliser un outil de collecte de données :
Précision

Les outils modernes de collecte de données disposent d'une importante base d'informations fiables. Cette base est mise à jour fréquemment pour fournir des données récentes et pertinentes, non seulement pour votre organisation, mais aussi d'une grande exactitude.
Rapidité
Les collecteurs de données permettent d'accélérer le processus de *web scraping* ou de recherche. Ils sont connectés à une base de données contenant de nombreuses informations utiles, accessibles en quelques clics, où que vous soyez. Vous pouvez ainsi effectuer vos recherches lors de vos déplacements, au bureau ou à domicile. Cela améliore l'efficacité globale de la collecte de données et vous fait gagner un temps précieux.
Moins d'Erreurs
Bien que la collecte manuelle soit possible, elle peut entraîner des erreurs humaines. L'utilisation d'un outil dédié vous fournira des informations précises et cohérentes pour alimenter vos processus et atteindre vos objectifs. Cela vous aidera également à maintenir l'intégrité de vos recherches, études ou *web scraping*.
Meilleurs Résultats
En utilisant un outil de collecte de données fiable, vous obtenez des informations complètes, exactes et pertinentes. Cela vous permet d'obtenir de meilleurs résultats et d'éviter les erreurs pouvant entraîner des problèmes supplémentaires. Des données précises, pertinentes et fiables vous aideront à prendre des décisions commerciales plus judicieuses et à améliorer vos prévisions.
Collecte de Données Vs. Solutions Traditionnelles de *Web Scraping*

Les outils de *web scraping* traditionnels peuvent être polyvalents, mais ils nécessitent souvent beaucoup de temps et d'efforts, surtout lorsqu'il s'agit de volumes importants de données. Internet contenant des milliards de données (enquêtes, forums, sites en ligne, rapports, etc.), l'extraction d'informations utiles et pertinentes peut s'avérer complexe.
Cependant, un outil avancé comme le Bright Data Collector permet de collecter des données rapidement et facilement, de manière plus efficace et passionnante.
Avec la multitude de collecteurs de données disponibles, le choix peut s'avérer difficile. Voici donc quelques critères à considérer pour choisir l'outil le plus adapté à vos besoins.
Comment Choisir le Bon Outil de Collecte de Données ?

Lors du choix d'un outil de collecte, voici les aspects à rechercher :
- Fonctionnalités Utiles: Choisissez un outil disposant de fonctionnalités adaptées à vos besoins. Évaluez vos exigences, puis sélectionnez celui qui vous offre les options dont vous avez réellement besoin. Il doit également pouvoir s'intégrer à d'autres outils pour faciliter votre travail.
- Facilité d'Utilisation: Pour tirer le meilleur parti d'un collecteur de données, optez pour un outil simple à utiliser. Son interface doit être intuitive, avec une navigation facile et une accessibilité sans effort.
- Abordabilité: Investissez dans un outil qui correspond à votre budget tout en proposant un ensemble de fonctionnalités utiles. Trouvez le bon équilibre. Vérifiez également la possibilité d'un essai gratuit pour évaluer son fonctionnement.
Si vous recherchez un bon outil de collecte de données, le Bright Data Collector est une option intéressante. Examinons ses caractéristiques pour évaluer s'il peut répondre à vos besoins.
Comment Bright Data Peut-il Vous Aider ?

Bright Data Collector est une plateforme de choix pour la collecte de données et le *web scraping*. Elle permet de récupérer des informations en ligne à grande échelle sans nécessiter d'infrastructure complexe. Cet outil extrait instantanément les données accessibles au public depuis n'importe quel site, vous permettant ainsi de répondre à vos besoins de recherche.
Vous avez la possibilité de collecter les données web par lots ou en temps réel. Évaluez vos besoins et utilisez le Bright Data Collector pour les satisfaire.
Bright Data Collector : Principales Fonctionnalités
Voici quelques fonctionnalités clés du Bright Data Collector :
Plateforme Sans Code
Simplifiez vos efforts de *web scraping* avec la plateforme sans code de Bright Data Collector. Vous n'avez pas besoin de coder pour utiliser cette solution et effectuer un *scraping*.
Auparavant, ce processus était complexe et nécessitait l'intervention de développeurs pour configurer l'outil. Cela exigeait également des experts en acquisition de données pour le *web scraping* et la gestion des *proxies*.
Grâce à sa plateforme sans code, Bright Data Collector devient accessible à tous, que vous soyez un développeur ou un expert en extraction de données. Vous économiserez ainsi du temps, des ressources et des heures précieuses, que vous pourrez consacrer à d'autres tâches importantes.
Modèles et Fonctions de Codage Prédéfinis
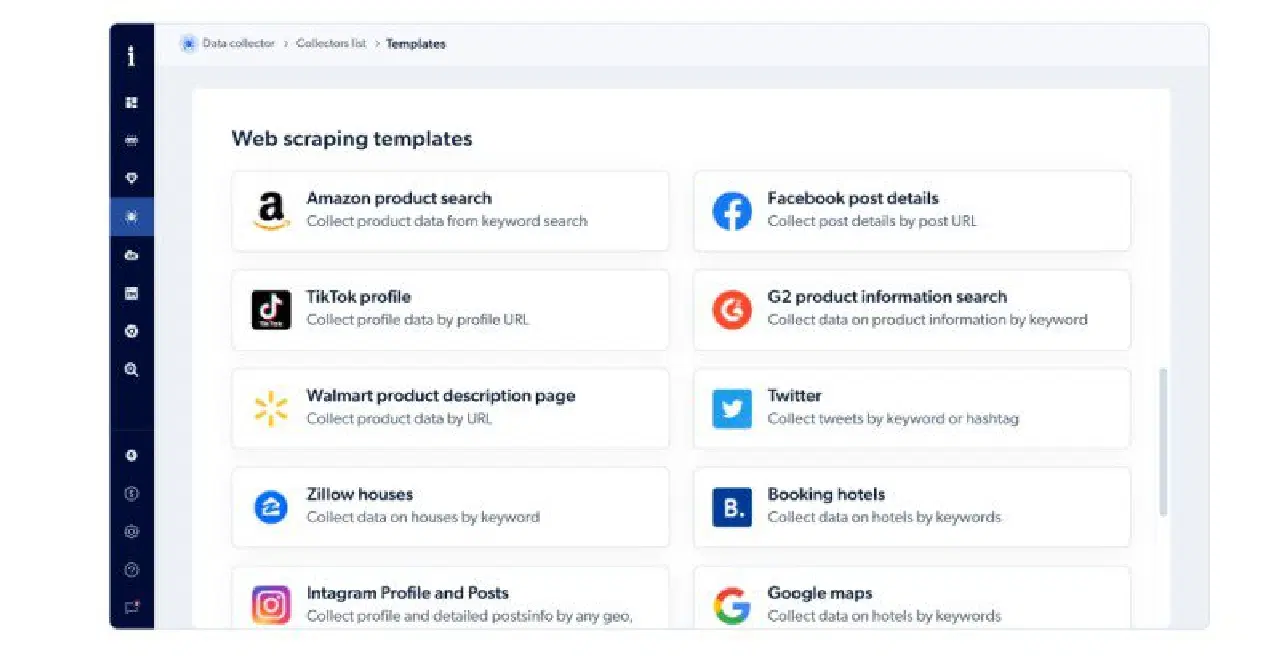
La solution hébergée de Bright Data offre des modèles et des fonctions de codage prédéfinis, ce qui facilite la création d'un outil de *web scraping* à grande échelle. Vous pouvez ainsi collecter des données publiques plus rapidement en temps réel grâce à son IDE JavaScript. Vous pouvez également connecter leur API à un flux de travail pour une procédure de collecte de données simplifiée.
Bright Data Collector propose des modèles de *web scraping* pour les recherches de produits Amazon, les maisons Zillow, les profils et publications Instagram, Google Maps, Twitter, les informations sur les publications Facebook, les pages de description de produits Walmart, etc.
Structuration Transparente
Bright Data Collector utilise des algorithmes d'intelligence artificielle pour associer, nettoyer, traiter, structurer et synthétiser de manière transparente les données non structurées d'un site avant leur livraison. Les ensembles de données obtenus sont ainsi prêts pour l'analyse plus rapidement.
Flexibilité Automatisée

Les structures de page web sont en constante évolution. Extraire des données de ces sites peut donc s'avérer difficile. Mais pas d'inquiétude, Bright Data Collector offre une excellente solution à ce problème. Il s'adapte rapidement aux changements structurels des sites et extrait les données utiles pour alimenter votre processus d'analyse.
Évolutivité au Niveau Entreprise
La collecte de données à grande échelle nécessite une infrastructure matérielle et logicielle robuste, ainsi que du temps et des ressources. Cela peut s'avérer coûteux et constituer un obstacle pour les organisations avec des budgets limités.
Bright Data Collector peut vous aider. Il collectera de manière fiable des données précises et utiles, à grande échelle. Vous n'aurez pas à investir dans une infrastructure coûteuse, ce qui vous permettra d'économiser de l'argent.
Conformité

Il est important de respecter les règles et réglementations applicables dans votre région ou pays. Cela vous évitera non seulement des sanctions, mais renforcera également la confiance de vos clients, partenaires et employés.
Bright Data Collector est entièrement conforme aux réglementations sur la protection des données, notamment le RGPD, les normes de l'UE et le CCPA. Vous pouvez ainsi effectuer du *web scraping* en toute sérénité. Cette approche de la protection des données vous aidera également à réussir rapidement vos audits.
Polyvalence
Bright Data Collector a mis en place des directives et les meilleures pratiques sur l'utilisation de sa plateforme tout en assurant la protection des données. C'est pourquoi les entreprises de toute taille, les gouvernements et les universités lui font confiance.
Infrastructure Réseau Proxy Robuste
Bright Data dispose d'une infrastructure de réseau *proxy* brevetée et à la pointe de l'industrie. Le Data Collector est construit sur cette infrastructure. Vous n'aurez ainsi aucune difficulté à accéder à n'importe quel site web public. Il surmontera les obstacles tels que les blocages géographiques, les problèmes d'accessibilité, etc. Vous pouvez donc extraire des informations de n'importe quel endroit accessible au public.
Fonctionne comme un Partenaire Commercial
Vous pouvez utiliser la plateforme en libre-service ou faire appel à ses ressources de développement. Ses développeurs, chefs de produit et gestionnaires de compte peuvent vous accompagner à chaque étape du processus pour résoudre vos problèmes commerciaux et répondre à vos besoins afin de stimuler votre croissance.
Comment Fonctionne Bright Data Collector ?
L'utilisation de Bright Data Collector ne nécessite pas de compétences en codage ou en *web scraping*. Vous pouvez installer et utiliser cette plateforme facilement, sans aide extérieure.
Voici les trois étapes simples à suivre :
Choisir un Modèle
Sélectionnez un modèle prédéfini parmi les options proposées, en fonction de vos besoins. Vous avez également la possibilité d'en créer un à partir de zéro.
Par exemple, si vous recherchez des listes de produits sur Amazon, vous pouvez utiliser le modèle de recherche de produits Amazon.
Personnaliser

La prochaine étape consiste à personnaliser ou à développer votre outil de *web scraping* à l'aide des fonctions de *scraping* prédéfinies de Bright Data Collector.
Si vous n'avez pas de connaissances en codage, ce n'est pas un problème. Cette solution sans code est idéale pour créer un outil de *web scraping* à partir de zéro. Cependant, si vous savez coder, vous pouvez aller plus loin et modifier le code pour l'adapter à vos besoins spécifiques.
Temps Réel ou Batch
Après avoir créé votre *web scraper*, choisissez comment vous souhaitez recevoir les données : par lots ou en temps réel. La fréquence des données dépend entièrement de vos besoins. Évaluez-les attentivement, puis choisissez une option.
Format et Livraison
Ici, choisissez le format de fichier pour récupérer vos données : CSV, JSON, XLSX ou NDJSON.
Sélectionnez ensuite le moyen de réception des données : e-mail, *webhook*, API, Google Cloud, Amazon S3, MS Azure et SFTP.
Service Client

En cas de besoin, l'assistance technique de Bright Data est disponible 24h/24 et 7j/7 pour répondre à vos questions et résoudre vos problèmes.
Tarification du Bright Data Collector
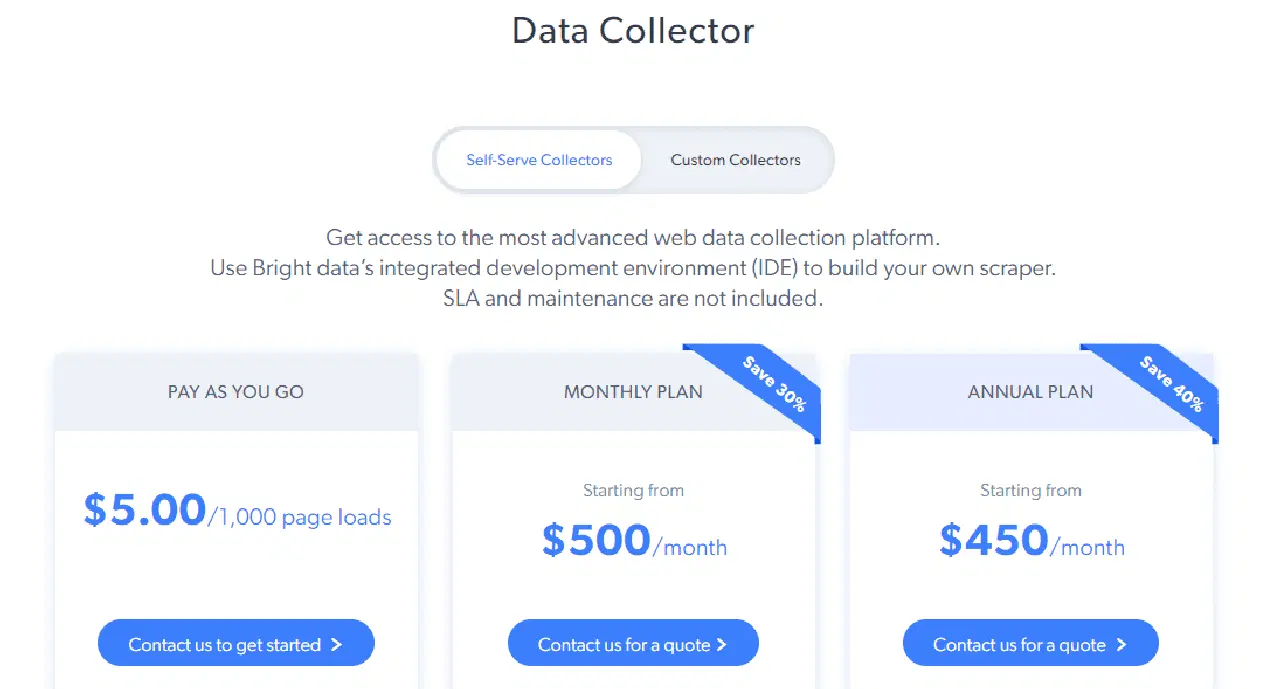
Bright Data Collector propose deux types de tarification : les collecteurs autonomes et les collecteurs personnalisés.
Collecteur en libre-service : Vous bénéficiez de fonctionnalités avancées telles que l'IDE de Bright Data pour créer votre *web scraper*, des alertes, un suivi du taux de réussite, des performances plus rapides, un *proxy* de qualité industrielle, etc. Voici les options tarifaires :
- Paiement à l'utilisation : 5 $ pour 1 000 pages chargées
- Abonnement mensuel : à partir de 500 $ par mois
- Abonnement annuel : à partir de 450 $ par mois
Pour les collecteurs personnalisés, le prix de départ est de 1 000 $ par mois.
Une option d'essai GRATUIT est également disponible pour une durée limitée afin de vérifier si la solution convient à votre cas d'utilisation.
Alternatives au Bright Data Collector
Tous les produits ne conviennent pas à tout le monde. Que ce soit en raison du prix, des fonctionnalités ou des politiques, certaines personnes pourraient ne pas apprécier le Bright Data Collector. Voici quelques alternatives intéressantes :
Oxylabs

La plateforme Oxylabs offre une excellente API de *web scraping* pour une collecte de données facile.
Principales caractéristiques :
- Collecte de données de qualité à partir de n'importe quel site avec son rotateur de *proxy* breveté.
- Collecte de données depuis 195 pays.
- Contournement facile des blocages géographiques.
- Sans entretien.
- Paiement uniquement pour les données livrées avec succès.
Vous pouvez l'essayer gratuitement pendant 7 jours ou choisir un forfait à partir de 99 $ par mois.
Smartproxy
Si vous recherchez une plateforme sans code autre que Bright Data, essayez Smartproxy. Il permet de planifier vos tâches de *web scraping* et de stocker vos données en toute sécurité sans codage.
Principales caractéristiques :
- Modèles de *scraping* prêts à l'emploi.
- Configuration en un seul clic.
- Exportation des données en CSV ou JSON.
- Stockage de données dans le *cloud*.
- Extension Chrome gratuite.
Essayez Smartproxy GRATUITEMENT pendant 3 jours, ou choisissez un forfait à partir de 50 $ par mois.
Zyte
Zyte propose une API d'extraction de données automatisée pour collecter des informations de manière fiable, plus rapide et sécurisée, sans risque de blocage. Il utilise une technologie d'IA brevetée pour l'extraction automatisée, ce qui vous garantit des données de qualité avec une structure claire.

Principales caractéristiques :
- Réponses rapides.
- Données de haute qualité de dix types différents.
- API HTTP simplifiée.
- Prise en charge de plus de 40 langues.
- Adaptation aux évolutions des sites.
- Gestion anti-blocage intégrée.
- Échelle illimitée.
Son plan tarifaire commence à 60 $ par mois et l'essai GRATUIT est disponible pendant 14 jours.
Conclusion
L'utilisation d'un outil de collecte de données comme Bright Data Collector facilite le *web scraping* grâce à son interface intuitive, ses performances fiables et ses fonctionnalités utiles.
Que vous soyez une organisation, une université ou une entreprise de recherche, cette plateforme pourrait être un excellent choix. Cependant, si vous recherchez des alternatives, les options présentées ci-dessus devraient répondre à vos besoins.
N'hésitez pas à explorer d'autres solutions de *web scraping* basées sur le *cloud*.