Éléments Clés
- De grandes entreprises telles qu’Open AI, Google, Microsoft et Meta investissent massivement dans les MPL.
- Les MPL gagnent du terrain dans le secteur et se positionnent favorablement pour l’avenir de l’IA.
- Parmi les exemples de MPL, on trouve Google Nano, Phi-3 de Microsoft et GPT-4o mini d’Open AI.
Les modèles de langage de grande envergure (MLG) ont émergé lors du lancement de ChatGPT par Open AI. Depuis, de nombreuses sociétés ont développé leurs propres MLG, mais un nombre croissant d’entre elles se tournent désormais vers les modèles de langage plus petits (MPL).
Les MPL prennent de l’ampleur, mais que sont-ils vraiment et quelle est leur différence avec les MLG ?
Qu’est-ce qu’un Petit Modèle de Langage ?
Un petit modèle de langage (MPL) est un type de modèle d’intelligence artificielle doté d’un nombre réduit de paramètres (considérez-les comme des valeurs apprises par le modèle durant sa phase d’entraînement). Tout comme leurs homologues plus volumineux, les MPL peuvent générer du texte et exécuter diverses autres tâches. Cependant, les MPL utilisent moins de données pour leur entraînement, ont moins de paramètres et requièrent une puissance de calcul moindre pour leur entraînement et leur fonctionnement.
Les MPL se concentrent sur des fonctionnalités essentielles, leur taille réduite leur permettant d’être déployés sur divers appareils, y compris ceux qui ne disposent pas de matériel haut de gamme, tels que les appareils mobiles. Par exemple, Google Nano est un MPL spécialement conçu pour fonctionner sur des appareils mobiles. Grâce à sa petite taille, Nano peut fonctionner localement avec ou sans connexion réseau, selon les indications de l’entreprise.
Outre Nano, de nombreux autres MPL sont proposés par des entreprises leaders et émergentes dans le domaine de l’IA. Parmi les MPL populaires, citons Phi-3 de Microsoft, GPT-4o mini d’OpenAI, Claude 3 Haiku d’Anthropic, Llama 3 de Meta et Mixtral 8x7B de Mistral AI.
D’autres options sont également disponibles, que l’on pourrait croire être des MLG mais qui sont en réalité des MPL. Cela est d’autant plus vrai que la plupart des entreprises adoptent une approche multi-modèle en lançant plusieurs modèles de langage dans leur portefeuille, offrant à la fois des MLG et des MPL. Un exemple est GPT-4, qui propose différents modèles, dont GPT-4, GPT-4o (Omni) et GPT-4o mini.
Petits Modèles de Langage vs Grands Modèles de Langage
Lorsque nous parlons de MPL, il est impossible d’ignorer leurs grands homologues : les MLG. La principale distinction entre un MPL et un MLG réside dans la taille du modèle, mesurée par le nombre de paramètres.
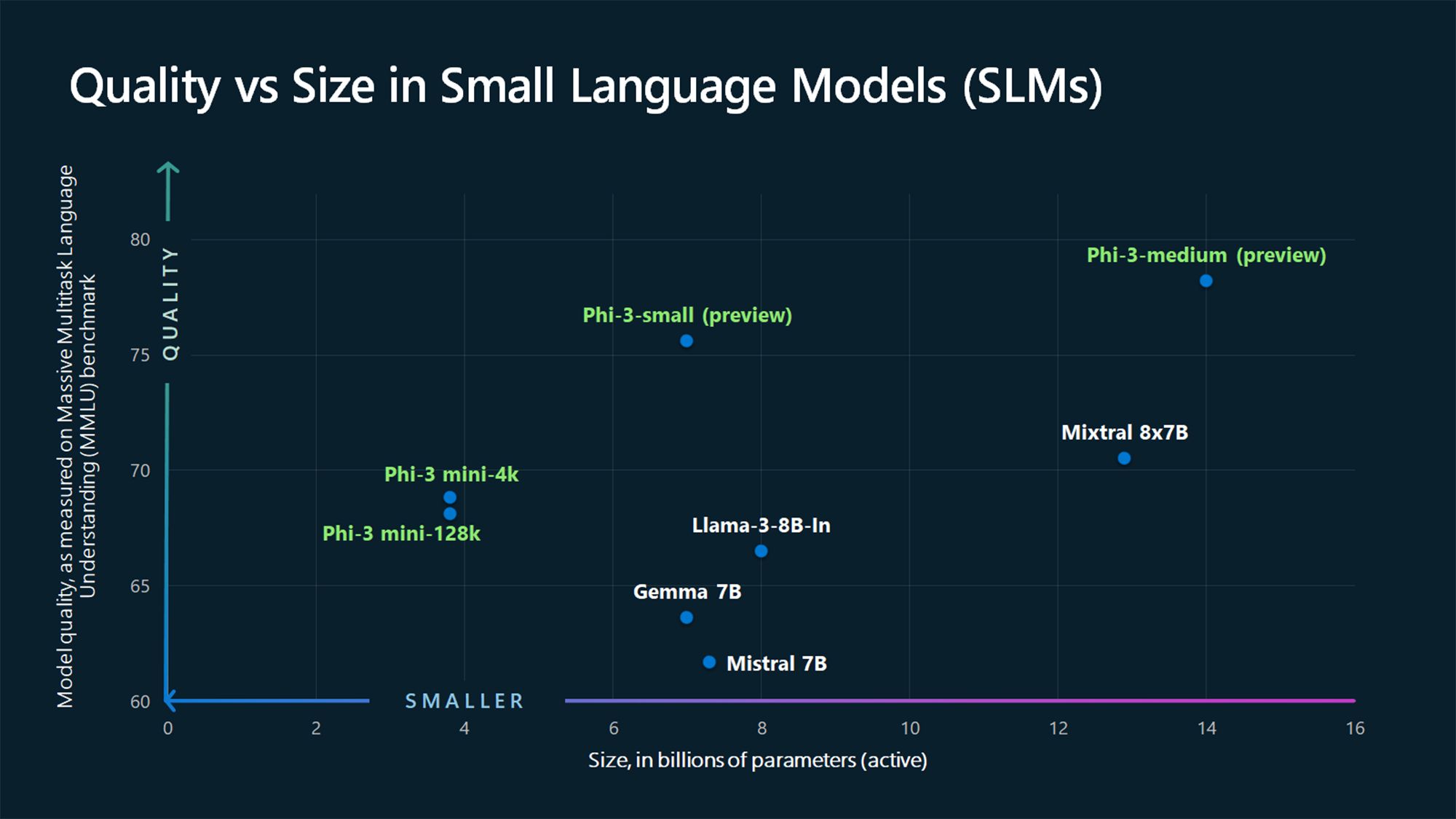
À l’heure actuelle, il n’existe pas de consensus dans l’industrie de l’IA quant au nombre maximal de paramètres qu’un modèle ne doit pas dépasser pour être considéré comme un MPL, ni quant au nombre minimal requis pour être classé comme un MLG. Cependant, les MPL ont généralement de quelques millions à quelques milliards de paramètres, tandis que les MLG en comptent un nombre bien supérieur, atteignant même des trillions.
Par exemple, GPT-3, lancé en 2020, compte 175 milliards de paramètres (et le modèle GPT-4 en aurait environ 1,76 trillion), alors que les MPL Phi-3-mini, Phi-3-small et Phi-3-medium de Microsoft en mesurent respectivement 3,8, 7 et 14 milliards.
Un autre facteur qui distingue les MPL des MLG est la quantité de données utilisées pour l’entraînement. Les MPL sont formés à partir de quantités de données plus réduites, tandis que les MLG exploitent de vastes ensembles de données. Cette différence a également un impact sur la capacité du modèle à résoudre des tâches complexes.
En raison de l’énorme volume de données utilisé pour leur entraînement, les MLG sont plus aptes à résoudre divers types de tâches complexes nécessitant un raisonnement avancé, tandis que les MPL sont plus adaptés aux tâches plus simples. Contrairement aux MLG, les MPL utilisent moins de données d’entraînement, mais les données utilisées doivent être de meilleure qualité pour atteindre un grand nombre des capacités observées chez les MLG, le tout dans un format plus compact.
Pourquoi les Petits Modèles de Langage Sont l’Avenir
Dans la majorité des cas d’utilisation, les MPL sont mieux placés pour devenir les modèles grand public employés par les entreprises et les particuliers afin de réaliser une multitude de tâches. Certes, les MLG ont leurs avantages et sont plus adaptés à certaines utilisations spécifiques, comme la résolution de problèmes complexes. Toutefois, les MPL représentent l’avenir pour la plupart des cas d’utilisation, pour les raisons suivantes.
1. Coûts de Formation et d’Entretien Moins Élevés
 Timofeev Vladimir/Shutterstock
Timofeev Vladimir/Shutterstock
Les MPL nécessitent moins de données pour leur entraînement que les MLG, ce qui en fait une option plus réaliste pour les particuliers et les petites et moyennes entreprises disposant de données de formation limitées, de budgets restreints, ou les deux. Les MLG nécessitent de grandes quantités de données d’entraînement et, par conséquent, des ressources informatiques colossales pour s’entraîner et fonctionner.
Pour illustrer cela, le PDG d’OpenAI, Sam Altman, a confirmé qu’il leur avait fallu plus de 100 millions de dollars pour former GPT-4 lors d’un événement au MIT (selon Wired). Autre exemple, le MLG OPT-175B de Meta. Meta affirme qu’il a été entraîné en utilisant 992 GPU NVIDIA A100 80 Go, qui coûtent environ 10 000 $ chacun, d’après CNBC. Cela représente un coût d’environ 9 millions de dollars, sans compter d’autres dépenses telles que l’énergie, les salaires, etc.
Avec de tels chiffres, il est hors de portée pour les petites et moyennes entreprises de former un MLG. En revanche, les MPL ont une barrière d’entrée plus basse en termes de ressources et leur fonctionnement coûte moins cher, ce qui les rend plus intéressants pour de nombreuses entreprises.
2. Meilleure Performance
 GBJSTOCK / Shutterstock
GBJSTOCK / Shutterstock
La performance est un autre domaine où les MPL surpassent les MLG, en raison de leur taille compacte. Les MPL ont une latence moindre et sont plus adaptés aux scénarios nécessitant des réponses plus rapides, comme dans les applications en temps réel. Par exemple, une réponse plus rapide est préférable dans les systèmes de réponse vocale comme les assistants numériques.
Fonctionner directement sur l’appareil (nous y reviendrons) signifie également que votre requête n’a pas besoin de faire un aller-retour vers des serveurs en ligne pour être traitée, ce qui se traduit par des réponses plus rapides.
3. Plus Précis
 ZinetroN / Shutterstock
ZinetroN / Shutterstock
Dans le domaine de l’IA générative, une constante demeure : des données de mauvaise qualité entraînent des résultats de mauvaise qualité. Les MLG actuels ont été entraînés à partir de vastes ensembles de données provenant d’Internet. Par conséquent, ils peuvent manquer de précision dans certaines situations. C’est l’un des problèmes de ChatGPT et de modèles similaires, et c’est pourquoi il ne faut pas faire confiance aveuglément à tout ce qu’un chatbot IA affirme. À l’inverse, les MPL sont entraînés à partir de données de meilleure qualité que les MLG, ce qui leur confère une plus grande précision.
Les MPL peuvent également être ajustés davantage grâce à un entraînement ciblé sur des tâches ou des domaines spécifiques, ce qui améliore leur précision dans ces domaines, comparativement aux modèles plus vastes et plus généralistes.
4. Peut Fonctionner Sur Appareil
 Pete Hansen/Shutterstock
Pete Hansen/Shutterstock
Les MPL nécessitent moins de puissance de calcul que les MLG et sont donc parfaitement adaptés aux cas d’utilisation en informatique de pointe (edge computing). Ils peuvent être déployés sur des appareils de périphérie tels que les smartphones et les véhicules autonomes, qui ne disposent pas de ressources ou de puissance de calcul importantes. Le modèle Nano de Google est capable de fonctionner sur l’appareil, ce qui lui permet de fonctionner même sans connexion internet active.
Cette capacité représente une situation gagnant-gagnant pour les entreprises et les consommateurs. Tout d’abord, cela est bénéfique pour la confidentialité, car les données des utilisateurs sont traitées localement au lieu d’être envoyées vers le cloud, ce qui est important à mesure que de plus en plus d’IA sont intégrées dans nos smartphones, contenant presque toutes les informations nous concernant. C’est également un avantage pour les entreprises, car elles n’ont pas besoin de déployer et d’exploiter de grands serveurs pour gérer les tâches d’IA.
Les MPL gagnent en popularité, les plus grands acteurs du secteur, tels qu’Open AI, Google, Microsoft, Anthropic et Meta, lançant ce type de modèles. Ces modèles sont mieux adaptés aux tâches plus simples, qui sont celles pour lesquelles la plupart d’entre nous utilisons les MLG; ainsi, ils représentent l’avenir.
Toutefois, les MLG ne disparaîtront pas. Au contraire, ils seront utilisés pour des applications de pointe qui combinent des informations provenant de différents domaines pour créer quelque chose de nouveau, comme dans la recherche médicale.
Résumé
En conclusion, les petits modèles de langage (MPL) représentent une avancée majeure dans le domaine de l’intelligence artificielle. Grâce à leurs coûts de formation réduits, leurs performances supérieures et leur capacité à fonctionner localement sur des appareils moins puissants, ils sont bien placés pour remplacer progressivement les modèles de langage de grande envergure (MLG) dans de nombreux cas d’utilisation. Les entreprises peuvent tirer parti de ces modèles pour réaliser des tâches variées tout en garantissant la confidentialité des données et en optimisant les ressources. Bien que les MLG continueront de jouer un rôle dans des applications de pointe, l’accent croissant mis sur les MPL pourrait bien façonner l’avenir de l’IA pour le grand public.