Désirez-vous explorer vos informations à l’aide du langage naturel ? Découvrez comment réaliser cela grâce à la bibliothèque Python PandasAI.
Dans un univers où les données sont d’une importance capitale, leur interprétation et leur analyse constituent des étapes indispensables. Toutefois, l’analyse de données traditionnelle peut s’avérer ardue. C’est là que PandasAI entre en jeu. Cet outil facilite l’analyse de données en vous permettant de dialoguer avec celles-ci via le langage naturel.
PandasAI fonctionne en convertissant vos interrogations en code pour l’analyse des données. Il est basé sur la bibliothèque Python pandas, très répandue. PandasAI est une bibliothèque Python qui étend les capacités de pandas, l’outil d’analyse et de manipulation de données par excellence, grâce à des fonctions d’IA générative. Il vise à enrichir pandas, non à le remplacer.
PandasAI ajoute un aspect conversationnel à pandas (ainsi qu’à d’autres bibliothèques d’analyse de données populaires), vous donnant la possibilité d’interagir avec vos données par le biais de requêtes en langage naturel.
Ce tutoriel vous guidera à travers les étapes de configuration de PandasAI, son utilisation avec un ensemble de données réel, la création de graphiques, l’exploration des raccourcis et l’analyse des forces et des limites de cet outil performant.
Après avoir terminé ce tutoriel, vous serez en mesure de réaliser des analyses de données plus simples et intuitives grâce au langage naturel.
Alors, plongeons dans le monde fascinant de l’analyse de données en langage naturel avec PandasAI !
Configuration de votre environnement
Pour commencer avec PandasAI, vous devrez d’abord installer la bibliothèque PandasAI.
Pour ce projet, j’utilise un Jupyter Notebook. Cependant, vous pouvez opter pour Google Collab ou VS Code, selon vos préférences.
Si vous prévoyez d’utiliser les modèles LLM (Large Language Models) d’OpenAI, il est également essentiel d’installer le SDK Open AI Python afin de garantir une expérience fluide.
# Installation de Pandas AI !pip install pandas-ai # Pandas AI utilise les modèles de langage d'OpenAI, il faut donc installer le SDK Python d'OpenAI !pip install openai
À présent, importons toutes les bibliothèques indispensables :
# Importation des bibliothèques nécessaires import pandas as pd import numpy as np # Importation de PandasAI et de ses composants from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
Un élément clé de l’analyse de données avec PandasAI est la clé API. Cet outil prend en charge plusieurs modèles LLM (Large Language Models) et LangChains, qui sont utilisés pour générer du code à partir de requêtes en langage naturel. Cela rend l’analyse de données plus abordable et conviviale.
PandasAI est adaptable et fonctionne avec différents types de modèles, parmi lesquels les modèles Hugging Face, Azure OpenAI, Google PALM et Google VertexAI. Chaque modèle apporte ses propres atouts, améliorant ainsi les capacités de PandasAI.
N’oubliez pas que pour utiliser ces modèles, vous aurez besoin des clés API correspondantes. Ces clés authentifient vos requêtes et vous permettent d’exploiter la puissance de ces modèles de langage avancés dans vos tâches d’analyse de données. Assurez-vous donc d’avoir vos clés API à disposition lors de la configuration de PandasAI pour vos projets.
Vous pouvez récupérer la clé API et l’exporter en tant que variable d’environnement.
Dans la prochaine étape, vous apprendrez à utiliser PandasAI avec divers types de grands modèles de langage (LLM) d’OpenAI et de Hugging Face Hub.
Utilisation de grands modèles de langage
Vous pouvez soit choisir un LLM en l’instanciant et en le transmettant au constructeur SmartDataFrame ou SmartDatalake, soit en en spécifier un dans le fichier pandasai.json.
Si le modèle attend un ou plusieurs paramètres, vous pouvez les transmettre au constructeur ou les spécifier dans le fichier pandasai.json dans le paramètre llm_options, comme ceci :
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Comment utiliser les modèles OpenAI ?
Pour utiliser les modèles OpenAI, vous devez posséder une clé API OpenAI. Vous pouvez en obtenir une ici.
Une fois en possession d’une clé API, vous pouvez l’utiliser pour instancier un objet OpenAI :
#Nous avons importé toutes les bibliothèques nécessaires à l'étape précédente
llm = OpenAI(api_token="ma-clé-api")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Veillez à remplacer « ma-clé-api » par votre clé API personnelle
Autre solution, vous pouvez définir la variable d’environnement OPENAI_API_KEY et instancier l’objet OpenAI sans transmettre la clé API :
# Définir la variable d'environnement OPENAI_API_KEY
llm = OpenAI() # il n'est pas nécessaire de fournir la clé API, elle sera lue à partir de la variable d'environnement
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Si vous utilisez un proxy explicite, vous pouvez spécifier openai_proxy lors de l’instanciation de l’objet OpenAI ou définir la variable d’environnement OPENAI_PROXY à transmettre.
Remarque importante : lorsque vous utilisez la bibliothèque PandasAI pour l’analyse de données avec votre clé API, il est essentiel de surveiller l’utilisation de vos jetons pour maîtriser les coûts.
Vous vous demandez comment faire ? Il vous suffit d’exécuter le code de compteur de jetons suivant pour obtenir un aperçu clair de votre utilisation de jetons et des dépenses correspondantes. Cela vous permettra de gérer efficacement vos ressources et d’éviter toute surprise au niveau de votre facturation.
Vous pouvez calculer le nombre de jetons utilisés par une invite comme ceci :
"""Exemple d'utilisation de PandasAI avec un dataframe pandas"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False est censé afficher une utilisation et un coût moindres
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculez la somme du PIB des pays nord-américains")
print(response)
print(cb)
Vous obtiendrez des résultats similaires à ceux-ci :
# La somme du PIB des pays nord-américains est de 19 294 482 071 552 $. # Jetons utilisés : 375 # Jetons d'invite : 210 # Jetons de fin : 165 # Coût total (USD) : 0,000750 $
N’oubliez pas de tenir compte de votre coût total si votre crédit est limité !
Comment utiliser les modèles de visage câlins ?
Pour utiliser les modèles HuggingFace, vous devez avoir une clé API HuggingFace. Vous pouvez créer un compte HuggingFace ici et obtenir une clé API ici.
Une fois en possession d’une clé API, vous pouvez l’utiliser pour instancier l’un des modèles HuggingFace.
Actuellement, PandasAI prend en charge les modèles HuggingFace suivants :
- Starcoder : bigcode/starcoder
- Falcon : tiiuae/falcon-7b-instruct
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="ma-clé-api-huggingface")
# ou
llm = Falcon(api_token="ma-clé-api-huggingface")
df = SmartDataframe("data.csv", config={"llm": llm})
Autre solution, vous pouvez définir la variable d’environnement HUGGINGFACE_API_KEY et instancier l’objet HuggingFace sans transmettre la clé API :
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # il n'est pas nécessaire de fournir la clé API, elle sera lue à partir de la variable d'environnement
# ou
llm = Falcon() # il n'est pas nécessaire de fournir la clé API, elle sera lue à partir de la variable d'environnement
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder et Falcon sont deux modèles LLM disponibles sur Hugging Face.
Nous avons configuré avec succès notre environnement et exploré comment utiliser les modèles OpenAI et Hugging Face LLM. Passons maintenant à notre parcours d’analyse de données.
Nous allons utiliser l’ensemble de données Big Mart Sales data, qui contient des informations sur les ventes de différents produits dans différents points de vente de Big Mart. L’ensemble de données comprend 12 colonnes et 8 524 lignes. Vous trouverez le lien à la fin de l’article.
Analyse des données avec PandasAI
Maintenant que nous avons installé et importé avec succès toutes les bibliothèques indispensables, nous pouvons procéder au chargement de notre ensemble de données.
Chargement de l’ensemble de données
Vous pouvez choisir un LLM en l’instanciant et en le transmettant au SmartDataFrame. Vous trouverez le lien vers l’ensemble de données à la fin de l’article.
#Chargement de l'ensemble de données depuis le périphérique path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Utilisation du modèle LLM d’OpenAI
Après le chargement de nos données. Je vais utiliser le modèle LLM d’OpenAI pour utiliser PandasAI
llm = OpenAI(api_token="Clé_API") pandas_ai = PandasAI(llm, conversational=False)
C’est parti ! Essayons d’utiliser les invites.
Affichage des 6 premières lignes de notre ensemble de données
Essayons de charger les 6 premières lignes, en fournissant des instructions :
Result = pandas_ai(df, "Affiche les 6 premières lignes de données sous forme de tableau") Result
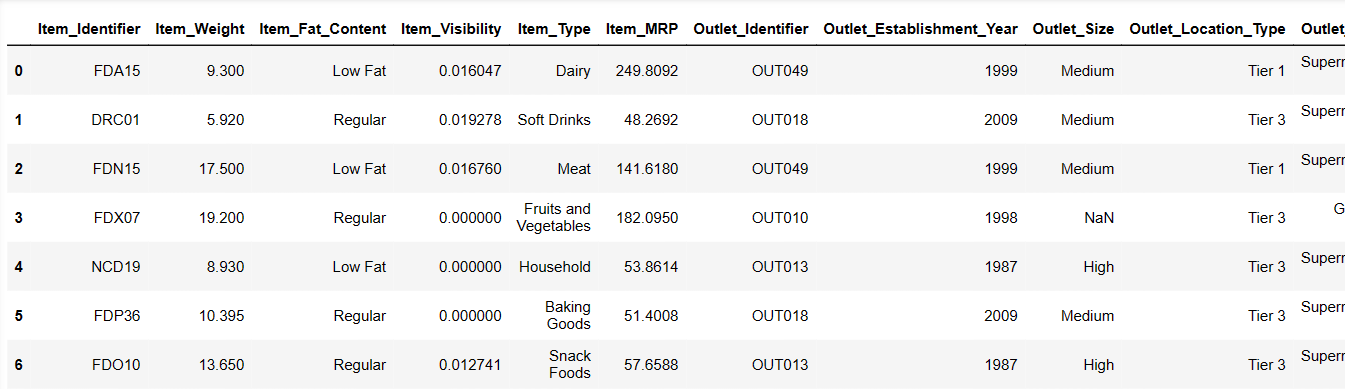 Les 6 premières lignes de l’ensemble de données
Les 6 premières lignes de l’ensemble de données
C’était vraiment rapide ! Tentons de comprendre notre ensemble de données.
Génération de statistiques descriptives de DataFrame
# Pour obtenir des statistiques descriptives Result = pandas_ai(df, "Affiche la description des données sous forme de tableau") Result
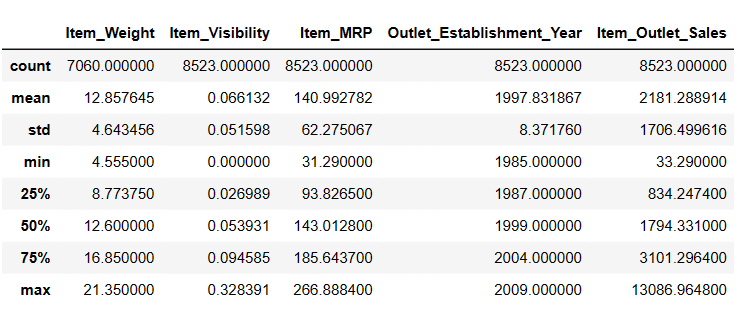 Description
Description
Il y a 7 060 valeurs dans Item_Weigth ; il se peut qu’il y ait des valeurs manquantes.
Recherche des valeurs manquantes
Il existe deux manières de trouver les valeurs manquantes à l’aide de pandas ai.
#Recherche des valeurs manquantes Result = pandas_ai(df, "Affiche les valeurs manquantes des données sous forme de tableau") Result
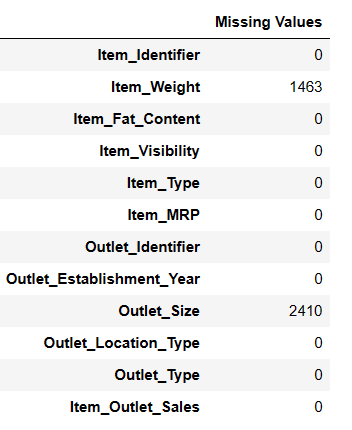 Recherche des valeurs manquantes
Recherche des valeurs manquantes
# Raccourci pour le nettoyage des données
df = SmartDataframe('data.csv')
df.clean_data()
Ce raccourci effectuera un nettoyage des données sur le bloc de données.
À présent, remplissons les valeurs nulles manquantes.
Remplissage des valeurs manquantes
#Remplissage des valeurs manquantes result = pandas_ai(df, "Remplir Item Weight avec la médiane et les valeurs nulles de Item outlet size avec le mode et afficher les valeurs manquantes des données sous forme de tableau") result
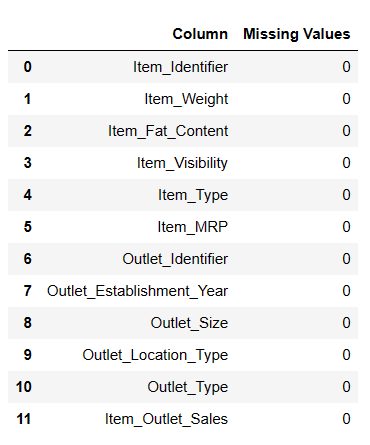 Valeurs nulles remplies
Valeurs nulles remplies
Il s’agit d’une méthode efficace pour remplir des valeurs nulles, mais j’ai rencontré quelques difficultés lors du remplissage de valeurs nulles.
# Raccourci pour remplir les valeurs nulles
df = SmartDataframe('data.csv')
df.impute_missing_values()
Ce raccourci imputera les valeurs manquantes dans le bloc de données.
Suppression des valeurs nulles
Si vous souhaitez supprimer toutes les valeurs nulles de votre df, vous pouvez essayer cette méthode.
result = pandas_ai(df, "Supprimer la ligne avec les valeurs manquantes avec inplace=True") result
L’analyse des données est essentielle pour identifier les tendances, à court et à long terme, ce qui peut s’avérer inestimable pour les entreprises, les gouvernements, les chercheurs et les particuliers.
Essayons d’identifier la tendance globale des ventes au fil des ans depuis sa création.
Découverte de la tendance des ventes
# découverte de la tendance des ventes result = pandas_ai(df, "Quelle est la tendance générale des ventes au fil des ans depuis la création du point de vente ?") result
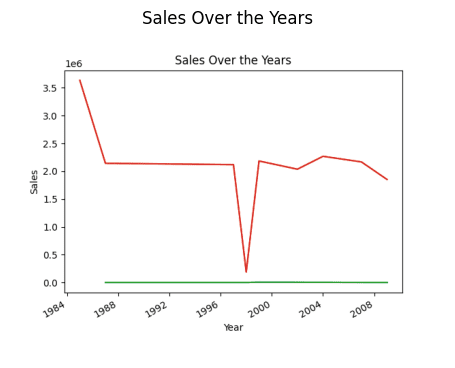 Ventes sur l’année (Graphique linéaire)
Ventes sur l’année (Graphique linéaire)
Le processus initial de création de graphique était un peu lent, mais après le redémarrage du noyau et l’exécution de l’ensemble, il est devenu plus rapide.
# Raccourci pour tracer des graphiques linéaires
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Ce raccourci tracera un graphique linéaire du bloc de données.
Vous vous demandez peut-être pourquoi la tendance est à la baisse. Cela est dû au fait que nous ne disposons pas de données de 1989 à 1994.
Recherche de l’année des ventes les plus élevées
Voyons maintenant quelle année affiche les ventes les plus élevées.
# recherche de l'année des ventes les plus élevées result = pandas_ai(df, "Explique quelles années ont les ventes les plus élevées") result

Ainsi, l’année où les ventes sont les plus élevées est 1985.
Mais je veux savoir quel type d’article génère les ventes moyennes les plus élevées et quel type génère les ventes moyennes les plus faibles.
Ventes moyennes les plus élevées et les plus basses
# découverte des ventes moyennes les plus élevées et les plus basses result = pandas_ai(df, "Quel type d'article génère les ventes moyennes les plus élevées et quel est celui qui génère les plus faibles ?") result

Les féculents affichent les ventes moyennes les plus élevées et les autres, les ventes moyennes les plus faibles. Si vous ne souhaitez pas que les autres ventes soient les plus faibles, vous pouvez améliorer l’invite en fonction de vos besoins.
Excellent ! À présent, je souhaite connaître la répartition des ventes entre les différents points de vente.
Répartition des ventes entre les différents points de vente
Il existe quatre types de points de vente : les supermarchés de type 1/2/3 et les épiceries.
# répartition des ventes entre les différents types de points de vente depuis la création response = pandas_ai(df, "Visualiser la répartition des ventes entre les différents types de points de vente depuis leur création à l'aide d'un graphique à barres, taille du graphique =(13,10)") response
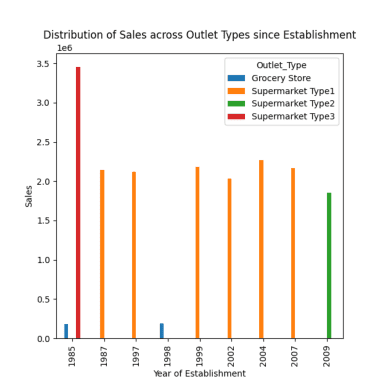 Répartition des ventes entre les différents points de vente
Répartition des ventes entre les différents points de vente
Comme observé dans les invites précédentes, les ventes maximales ont eu lieu en 1985, et ce graphique met en évidence les ventes les plus élevées en 1985 dans les supermarchés de type 3.
# Raccourci vers le graphique à barres
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Ce raccourci tracera un graphique à barres du bloc de données.
# Raccourci pour tracer l’histogramme
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Ce raccourci tracera un histogramme du bloc de données.
Voyons maintenant quelles sont les ventes moyennes des articles à teneur en matières grasses « faible en matières grasses » et « ordinaire ».
Découverte des ventes moyennes des articles contenant des matières grasses
# recherche de l'index d'une ligne à l'aide de la valeur d'une colonne result = pandas_ai(df, "Quelles sont les ventes moyennes des articles avec une teneur en matières grasses 'faible en matières grasses' et 'ordinaire' ?") result
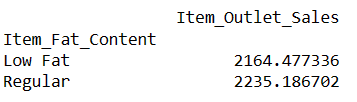
L’écriture d’invites comme celle-ci vous permet de comparer deux produits ou plus.
Ventes moyennes de chaque type d’article
Je souhaite comparer tous les produits avec leurs ventes moyennes.
#Ventes moyennes de chaque type d'article result = pandas_ai(df, "Quelles sont les ventes moyennes de chaque type d'article au cours des 5 dernières années ?, utiliser un diagramme circulaire, taille=(6,6)") result
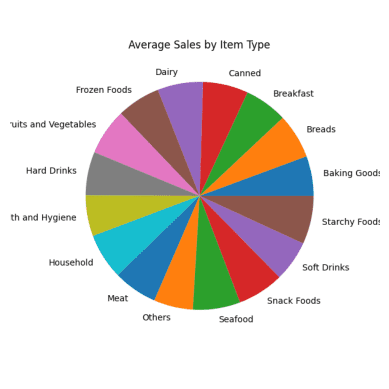 Graphique circulaire des ventes moyennes
Graphique circulaire des ventes moyennes
Toutes les sections du diagramme circulaire semblent similaires car elles présentent des chiffres de vente presque identiques.
# Raccourci pour tracer un diagramme circulaire
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Ce raccourci tracera un diagramme circulaire du bloc de données.
Top 5 des types d’articles les plus vendus
Bien que nous ayons déjà comparé tous les produits en fonction des ventes moyennes, j’aimerais à présent identifier les 5 articles les plus vendus.
#Découverte des 5 articles les plus vendus result = pandas_ai(df, "Quels sont les 5 types d'articles les plus vendus en fonction des ventes moyennes ? Les indiquer sous forme de tableau") result
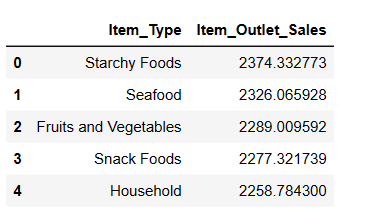
Comme prévu, les féculents sont les articles les plus vendus en termes de ventes moyennes.
Top 5 des types d’articles les moins vendus
result = pandas_ai(df, "Quels sont les 5 types d'articles les moins vendus en fonction des ventes moyennes ?") result
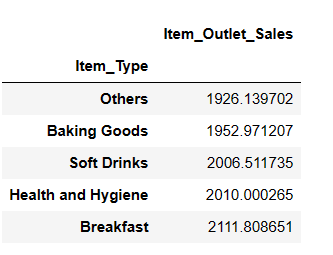
Vous pourriez être surpris de voir les boissons gazeuses dans la catégorie des articles les moins vendus. Toutefois, il est important de préciser que ces données ne remontent qu’à 2008 et que la tendance des boissons gazeuses s’est envolée quelques années plus tard.
Ventes des catégories de produits
Ici, j’ai utilisé le terme « catégorie de produit » au lieu de « type d’article », et PandasAI a quand même généré les graphiques, ce qui montre sa compréhension des termes similaires.
result = pandas_ai(df, "Générer un graphique à barres empilées de grande taille des ventes des différentes catégories de produits pour le dernier exercice financier") result
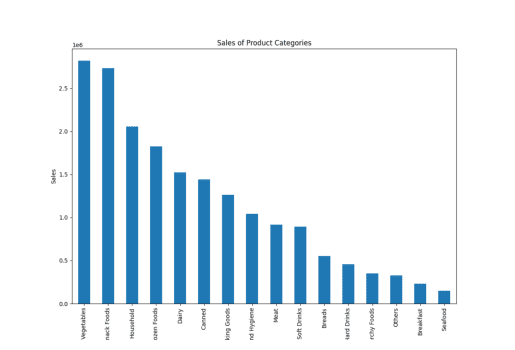 Ventes de type d’article
Ventes de type d’article
Vous pouvez trouver nos raccourcis restants ici.
Vous remarquerez peut-être que lorsque nous écrivons une invite et fournissons des instructions à un PandasAI, celui-ci fournit des résultats basés uniquement sur cette invite spécifique. Il n’analyse pas vos invites précédentes pour proposer des réponses plus précises.
Cependant, avec l’aide d’un agent de discussion, vous pouvez également bénéficier de cette fonctionnalité.
Agent de discussion
Avec l’agent de discussion, vous pouvez participer à des conversations dynamiques dans lesquelles l’agent conserve le contexte tout au long de la discussion. Cela vous permet d’avoir des échanges plus interactifs et significatifs.
Les fonctionnalités clés qui permettent cette interaction incluent la conservation du contexte, où l’agent se souvient de l’historique de la conversation, permettant des interactions transparentes et sensibles au contexte. Vous pouvez utiliser la méthode des questions de clarification pour demander des éclaircissements sur n’importe quel aspect de la conversation, ce qui garantit votre bonne compréhension des informations fournies.
De plus, la méthode Explain est disponible pour obtenir des explications détaillées sur la manière dont l’agent est parvenu à une solution ou une réponse particulière, ce qui offre une transparence et un aperçu du processus de décision de l’agent.
N’hésitez pas à engager des conversations, à demander des éclaircissements et à explorer des explications pour améliorer vos interactions avec l’agent de discussion !
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Quels sont les 5 articles avec le MRP le plus élevé ?")
result
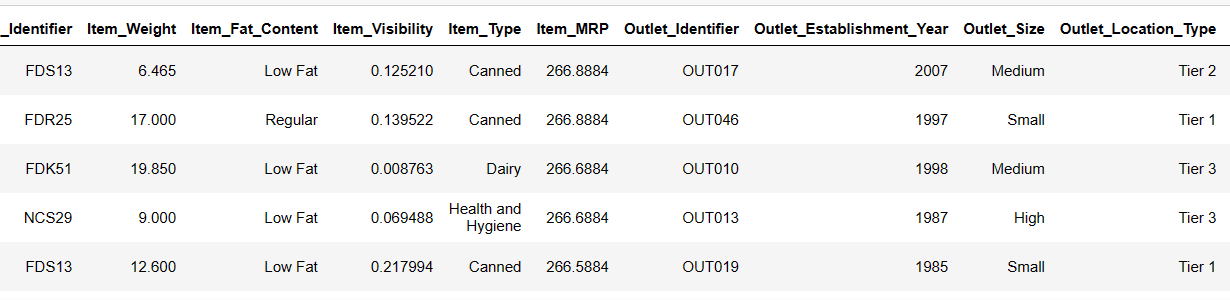
Contrairement à un SmartDataframe ou un SmartDatalake, un agent gardera une trace de l’état de la conversation et pourra répondre aux conversations à plusieurs tours.
Passons aux avantages et aux limites de PandasAI
Avantages de PandasAI
L’utilisation de Pandas AI offre plusieurs avantages qui en font un outil précieux pour l’analyse des données, tels que :
- Accessibilité : PandasAI simplifie l’analyse des données, ce qui la rend accessible à un large éventail d’utilisateurs. Toute personne, quelle que soit sa formation technique, peut l’utiliser pour extraire des informations à partir de données et répondre à des questions liées à l’activité.
- Requêtes en langage naturel : la possibilité de poser directement des questions et de recevoir des réponses à partir de données grâce à des requêtes en langage naturel rend l’exploration et l’analyse des données plus conviviales. Cette fonctionnalité permet même aux utilisateurs non techniques d’interagir efficacement avec les données.
- Fonctionnalité de discussion avec agent : la fonction de discussion permet aux utilisateurs d’interagir avec les données de manière interactive, tandis que la fonction de discussion avec agent exploite l’historique des discussions précédentes pour fournir des réponses contextuelles. Cela favorise une approche dynamique et conversationnelle de l’analyse des données.
- Visualisation des données : PandasAI offre un éventail d’options de visualisation de données, notamment des cartes thermiques, des nuages de points, des graphiques à barres, des diagrammes circulaires, des graphiques linéaires, etc. Ces visualisations aident à comprendre et à présenter les modèles et les tendances des données.
- Raccourcis permettant de gagner du temps : la disponibilité de raccourcis et de fonctionnalités permettant de gagner du temps rationalise le processus d’analyse des données, ce qui aide les utilisateurs à travailler plus efficacement.
- Compatibilité des fichiers : PandasAI prend en charge divers formats de fichiers, notamment CSV, Excel, Google Sheets, etc. Cette flexibilité permet aux utilisateurs de travailler avec des données provenant d’une multitude de sources et de formats.
- Invites personnalisées : les utilisateurs peuvent créer des invites personnalisées à l’aide d’instructions simples et de code Python. Cette fonctionnalité permet aux utilisateurs d’adapter leurs interactions avec les données en fonction de besoins et de requêtes spécifiques.
- Enregistrement des modifications : la possibilité d’enregistrer les modifications apportées aux dataframes garantit la conservation de votre travail et vous permet de revoir et de partager votre analyse à tout moment.
- Réponses personnalisées : l’option permettant de créer des réponses personnalisées offre la possibilité aux utilisateurs de définir des comportements ou des interactions spécifiques, ce qui rend l’outil encore plus polyvalent.
- Intégration de modèles : PandasAI prend en charge différents modèles de langage, notamment ceux des modèles Hugging Face, Azure, Google Palm, Google VertexAI et LangChain. Cette intégration améliore les capacités de l’outil et permet un traitement et une compréhension avancés du langage naturel.
- Prise en charge LangChain intégrée : la prise en charge intégrée des modèles LangChain étend encore la gamme de modèles et de fonctionnalités disponibles, ce qui améliore la profondeur de l’analyse et les informations pouvant être tirées des données.
- Compréhension des noms : PandasAI montre qu’il est capable de comprendre la corrélation entre les noms de colonnes et la terminologie réelle. Par exemple, même si vous utilisez des termes tels que « catégorie de produit » au lieu de « type d’article » dans vos invites, l’outil peut quand même fournir des résultats pertinents et précis. Cette flexibilité dans la reconnaissance des synonymes et leur mise en correspondance avec les colonnes de données appropriées améliore la commodité de l’utilisateur et l’adaptabilité de l’outil aux requêtes en langage naturel.
Bien que PandasAI offre plusieurs avantages, il présente également certaines limites et difficultés que les utilisateurs doivent connaître :
Limites de PandasAI
Voici quelques limites que j’ai observées :
- Exigence de clé API : pour utiliser PandasAI, il est indispensable de posséder une clé API. Si vous n’avez pas suffisamment de crédit sur votre compte OpenAI, vous ne pourrez peut-être pas utiliser le service. Cependant, il convient de noter qu’OpenAI offre un crédit de 5 $ aux nouveaux utilisateurs, ce qui le rend accessible aux personnes qui découvrent la plateforme.
- Temps de traitement : parfois, le service peut présenter des retards dans la communication des résultats, qui peuvent être imputés à une utilisation élevée ou à une charge du serveur. Les utilisateurs doivent être préparés aux temps d’attente potentiels lorsqu’ils interrogent le service.
- Interprétation des invites : bien que vous puissiez poser des questions via des invites, la capacité du système à expliquer les réponses n’est peut-être pas entièrement aboutie et la qualité des explications peut varier. Cet aspect de PandasAI pourrait être amélioré à l’avenir grâce à de nouveaux développements.
- Sensibilité des invites : les utilisateurs doivent être prudents lors de la création d’invites, car même de légers changements peuvent conduire à des résultats différents. Cette sensibilité à la formulation et à la structure des invites peut avoir un impact sur la cohérence des résultats, en particulier lorsque vous travaillez avec des graphiques de données ou des requêtes plus complexes.
- Limitations des invites complexes : PandasAI peut ne pas gérer les invites ou les requêtes très complexes aussi efficacement que les plus simples. Les utilisateurs doivent être conscients de la complexité de leurs questions et s’assurer que l’outil est adapté à leurs besoins spécifiques.
- Modifications incohérentes des DataFrame : les utilisateurs ont signalé des problèmes lors de la modification des DataFrames, tels que le remplissage des valeurs nulles ou la suppression des lignes de valeurs nulles, même en spécifiant « Inplace = True ». Cette incohérence peut s’avérer frustrante pour les utilisateurs qui essaient de modifier leurs données.
- Résultats variables : lors du redémarrage d’un noyau ou de la réexécution des invites, il est possible de recevoir des résultats ou des interprétations des données différents des exécutions précédentes. Cette