Imaginez que vous gérez une vaste infrastructure composée de divers types d’équipements, nécessitant une maintenance régulière ou une surveillance pour garantir leur sécurité et leur respect de l’environnement.
Une approche pourrait consister à envoyer périodiquement des équipes sur chaque site pour effectuer des contrôles. Bien que réalisable, cette méthode s’avère chronophage et coûteuse. De plus, si l’infrastructure est étendue, il pourrait être difficile de la couvrir entièrement en un an.
Une alternative consiste à automatiser ce processus, en laissant des systèmes basés sur le cloud effectuer les vérifications à votre place. Pour mettre en place une telle solution, il faut procéder comme suit :
👉 Un processus rapide pour capturer des images des équipements. Cela peut être effectué par des opérateurs, car la prise d’une photo est plus rapide que le processus de vérification complet. Il est également possible d’utiliser des photos prises depuis des véhicules ou des drones, ce qui automatise et accélère davantage la collecte d’images.
👉 Ensuite, il faut transférer toutes les images obtenues vers un emplacement dédié dans le cloud.
👉 Dans le cloud, un processus automatisé doit récupérer et traiter les images à l’aide de modèles d’apprentissage automatique entraînés à identifier les défauts ou les anomalies.
👉 Enfin, les résultats doivent être accessibles aux utilisateurs concernés afin que les réparations puissent être planifiées pour les équipements présentant des problèmes.
Explorons comment réaliser une détection d’anomalies à partir d’images à l’aide du cloud AWS. Amazon propose des modèles d’apprentissage automatique préconfigurés que nous pouvons utiliser à cette fin.
Comment développer un modèle pour la détection d’anomalies visuelles
Le développement d’un modèle de détection d’anomalies visuelles comprend plusieurs étapes clés :
Étape 1 : Définissez clairement le problème que vous souhaitez résoudre et les types d’anomalies à détecter. Cela vous guidera dans le choix du jeu de données d’entraînement approprié.
Étape 2 : Rassemblez un vaste ensemble d’images représentant des conditions normales et anormales. Étiquetez ces images pour indiquer celles qui sont normales et celles qui présentent des anomalies.
Étape 3 : Sélectionnez une architecture de modèle adaptée à la tâche. Vous pouvez choisir un modèle pré-entraîné et l’adapter à votre cas d’utilisation spécifique, ou concevoir un modèle personnalisé à partir de zéro.
Étape 4 : Entraînez le modèle en utilisant le jeu de données préparé et l’algorithme choisi. Vous pouvez recourir à l’apprentissage par transfert pour exploiter des modèles pré-entraînés ou entraîner le modèle à partir de rien en utilisant des techniques telles que les réseaux neuronaux convolutifs (CNN).
Comment entraîner un modèle d’apprentissage automatique
Source : aws.amazon.com
L’entraînement de modèles d’apprentissage automatique AWS pour la détection d’anomalies visuelles se décompose généralement en plusieurs étapes importantes.
#1. Collecte des données
Il est primordial de collecter et d’étiqueter un grand volume d’images représentant des conditions normales et anormales. Plus l’ensemble de données est important, plus le modèle pourra être entraîné avec précision. Toutefois, cela implique également un temps d’entraînement plus long.
Il est conseillé de disposer d’au moins 1000 images dans un ensemble de test pour démarrer correctement.
#2. Préparation des données
Les données d’images doivent être prétraitées pour être utilisables par les modèles d’apprentissage automatique. Le prétraitement peut impliquer différentes actions, telles que :
- Organiser les images d’entrée dans des sous-dossiers distincts, corriger les métadonnées, etc.
- Redimensionner les images pour respecter les exigences de résolution du modèle.
- Diviser les images en fragments plus petits pour un traitement plus efficace et parallèle.
#3. Sélection du modèle
Choisissez le modèle le plus approprié pour la tâche à accomplir. Optez pour un modèle pré-entraîné ou développez un modèle personnalisé adapté à la détection d’anomalies visuelles spécifique.
#4. Évaluation des résultats
Après le traitement de votre jeu de données par le modèle, validez ses performances. Vérifiez si les résultats obtenus répondent à vos exigences. Par exemple, assurez-vous que les résultats sont exacts sur plus de 99% des données d’entrée.
#5. Déploiement du modèle
Si vous êtes satisfait des performances et des résultats, déployez le modèle avec une version spécifique dans l’environnement de votre compte AWS afin que les processus et les services puissent commencer à l’utiliser.
#6. Surveillance et amélioration
Testez en continu le modèle avec différents jeux de données d’images et évaluez si les critères d’exactitude de la détection sont toujours satisfaisants. Si ce n’est pas le cas, réentraînez le modèle en intégrant les nouveaux ensembles de données ayant généré des résultats incorrects.
Modèles d’apprentissage automatique AWS
Examinons quelques modèles concrets que vous pouvez utiliser dans le cloud Amazon.
AWS Rekognition
Source : aws.amazon.com
Rekognition est un service d’analyse d’images et de vidéos polyvalent qui peut être utilisé pour diverses applications, telles que la reconnaissance faciale, la détection d’objets et la reconnaissance de texte. Il est souvent utilisé pour une première analyse brute des résultats de détection afin de construire un lac de données d’anomalies identifiées.
Il propose une gamme de modèles pré-entraînés qui peuvent être utilisés sans entraînement supplémentaire. Rekognition offre également une analyse en temps réel des images et des vidéos avec une grande précision et une faible latence.
Voici quelques cas d’utilisation courants où Rekognition est un bon choix pour la détection d’anomalies :
- Détection d’anomalies à usage général dans des images ou des vidéos.
- Détection d’anomalies en temps réel.
- Intégration du modèle de détection d’anomalies aux services AWS tels qu’Amazon S3, Amazon Kinesis ou AWS Lambda.
Voici quelques exemples d’anomalies que vous pouvez détecter avec Rekognition :
- Anomalies faciales, telles que des expressions faciales ou des émotions en dehors de la plage normale.
- Objets manquants ou mal placés dans une scène.
- Mots mal orthographiés ou schémas de texte inhabituels.
- Conditions d’éclairage inhabituelles ou objets inattendus dans une scène.
- Contenu inapproprié ou offensant dans des images ou des vidéos.
- Changements soudains ou schémas de mouvement inattendus.
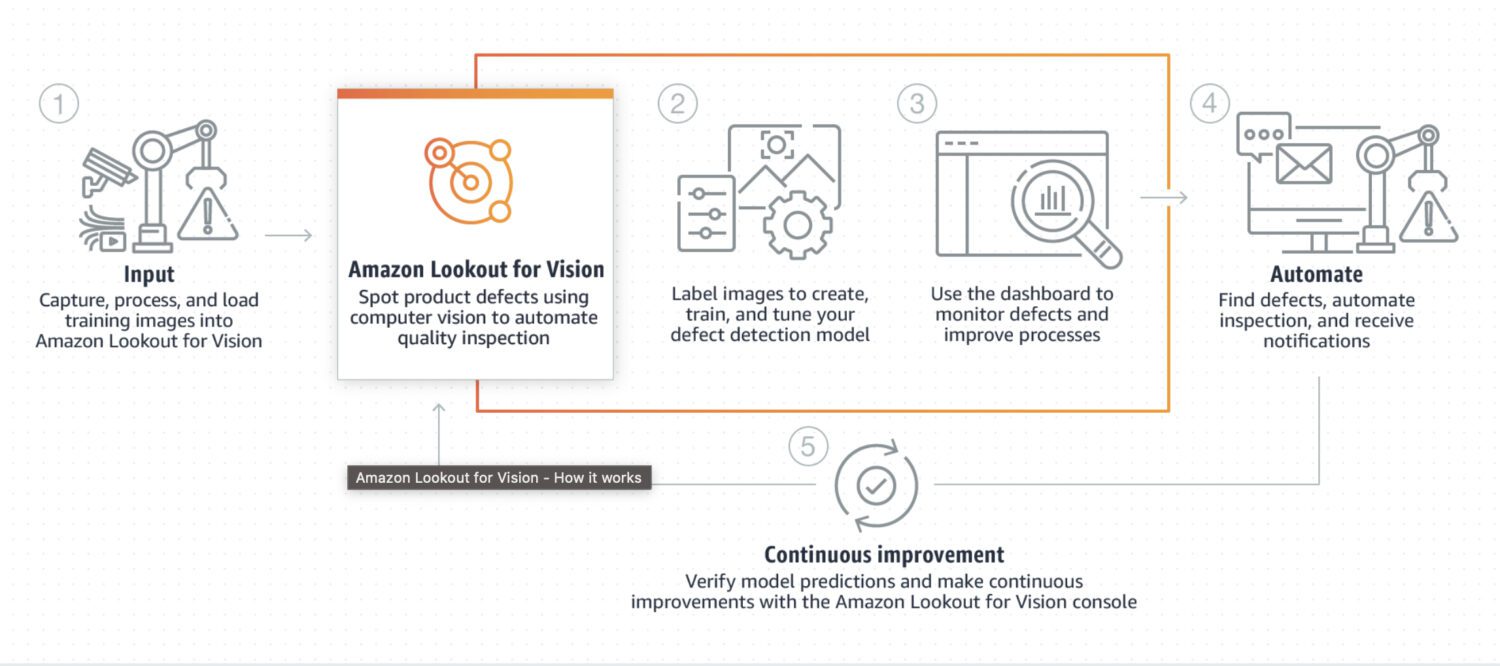
AWS Lookout for Vision
Source : aws.amazon.com
Lookout for Vision est spécialement conçu pour la détection d’anomalies dans les processus industriels, tels que les chaînes de fabrication et de production. Il nécessite généralement un prétraitement et un post-traitement de code personnalisé pour une image ou une zone spécifique, souvent effectués en Python. Il est principalement utilisé pour des problèmes d’image très particuliers.
Il nécessite un entraînement personnalisé sur un ensemble de données d’images normales et anormales pour créer un modèle sur mesure pour la détection d’anomalies. Son but n’est pas la détection en temps réel, mais plutôt le traitement par lots d’images, en mettant l’accent sur l’exactitude et la précision.
Voici quelques cas d’utilisation courants où Lookout for Vision est un bon choix :
- Détection de défauts dans les produits manufacturés ou identification de pannes d’équipement sur une chaîne de production.
- Gestion d’un grand ensemble de données d’images ou d’autres données.
- Détection d’anomalies en temps réel dans un processus industriel.
- Intégration d’une détection d’anomalies à d’autres services AWS, tels qu’Amazon S3 ou AWS IoT.
Voici quelques exemples d’anomalies que vous pouvez détecter à l’aide de Lookout for Vision :
- Défauts dans les produits manufacturés, tels que des rayures, des bosses ou d’autres imperfections qui peuvent affecter la qualité du produit.
- Pannes d’équipement sur une chaîne de production, telles que la détection de machines cassées ou défectueuses pouvant entraîner des retards ou des risques pour la sécurité.
- Problèmes de contrôle qualité dans une chaîne de production, notamment la détection de produits qui ne répondent pas aux spécifications ou aux tolérances requises.
- Risques pour la sécurité dans une chaîne de production, incluant la détection d’objets ou de matériaux qui pourraient présenter un danger pour les travailleurs ou l’équipement.
- Anomalies dans un processus de production, telles que des changements inattendus dans le flux de matières premières ou de produits sur la chaîne de production.
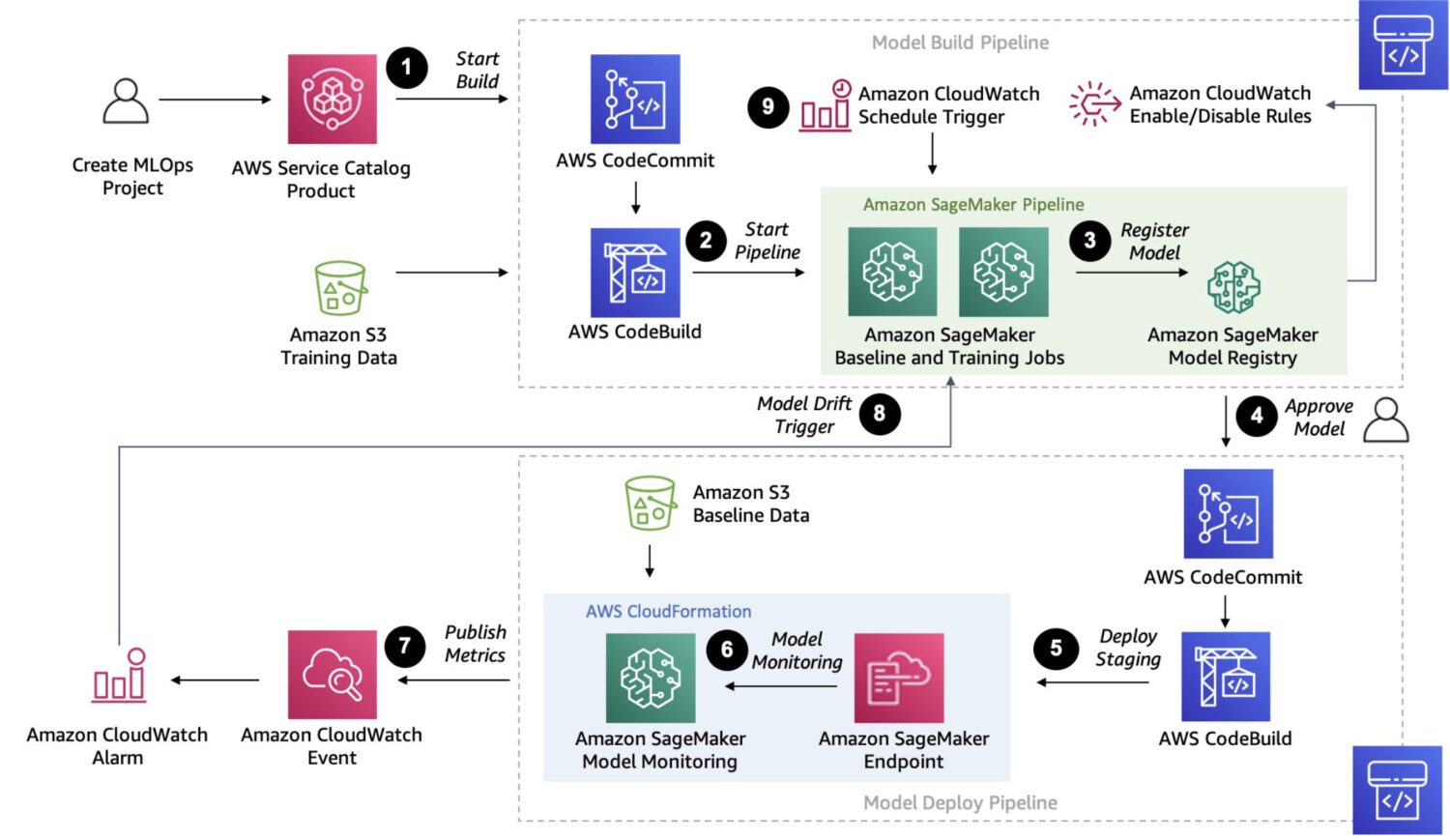
AWS SageMaker
Source : aws.amazon.com
SageMaker est une plateforme entièrement gérée pour la création, l’entraînement et le déploiement de modèles d’apprentissage automatique personnalisés.
C’est une solution beaucoup plus robuste. Elle permet de connecter et d’exécuter plusieurs processus en plusieurs étapes au sein d’une chaîne de tâches, de manière similaire aux fonctions d’étape AWS.
Étant donné que SageMaker utilise des instances EC2 ad hoc pour le traitement, il n’y a pas de limite de 15 minutes pour la durée d’une seule tâche, contrairement aux fonctions AWS Lambda dans AWS Step Functions.
SageMaker offre également un réglage automatique du modèle, ce qui en fait une option intéressante. Enfin, SageMaker peut facilement déployer le modèle dans un environnement de production.
Voici quelques cas d’utilisation courants où SageMaker est un bon choix pour la détection d’anomalies :
- Un cas d’utilisation spécifique non couvert par des modèles ou des API pré-entraînés, nécessitant la création d’un modèle personnalisé adapté à vos besoins spécifiques.
- La gestion d’un grand ensemble de données d’images ou d’autres données. Les modèles pré-construits nécessitent un prétraitement dans de tels cas, alors que Sagemaker peut le faire sans cela.
- La détection d’anomalies en temps réel.
- L’intégration de votre modèle à d’autres services AWS, tels qu’Amazon S3, Amazon Kinesis ou AWS Lambda.
Voici quelques exemples d’anomalies que SageMaker peut détecter :
- Détection de fraudes dans les transactions financières, telles que des habitudes de dépenses inhabituelles ou des transactions en dehors de la plage normale.
- Cybersécurité dans le trafic réseau, comme des schémas inhabituels de transfert de données ou des connexions inattendues à des serveurs externes.
- Diagnostic médical dans les images médicales, comme la détection de tumeurs.
- Anomalies dans les performances des équipements, comme la détection de changements de vibrations ou de températures.
- Contrôle qualité dans les processus de fabrication, comme la détection de défauts dans les produits ou l’identification des écarts par rapport aux normes de qualité attendues.
- Schémas de consommation d’énergie inhabituels.
Comment intégrer les modèles dans une architecture sans serveur
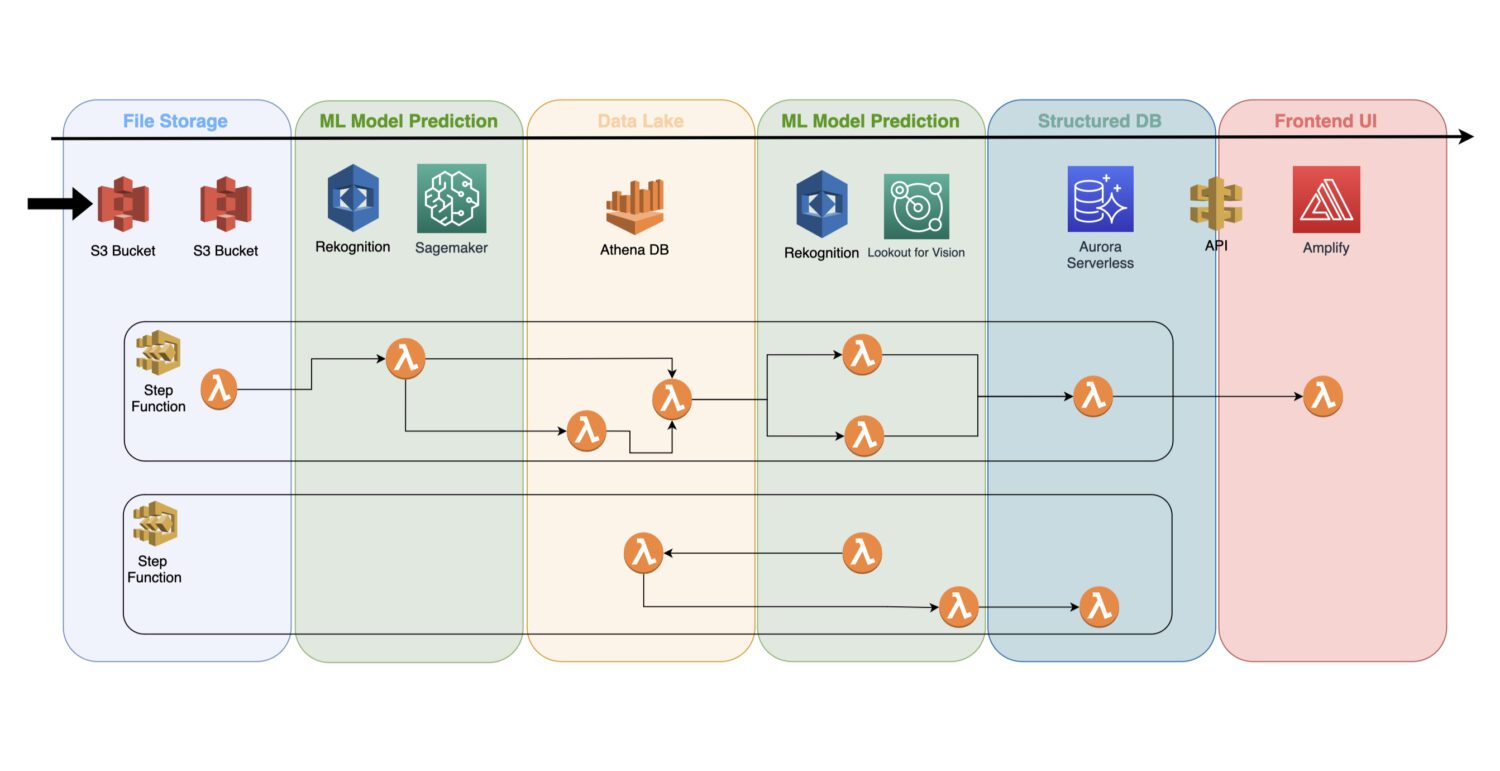
Un modèle d’apprentissage automatique entraîné est un service cloud qui ne requiert aucun serveur de cluster en arrière-plan. Par conséquent, il peut facilement être intégré dans une architecture sans serveur existante.
L’automatisation est effectuée via des fonctions AWS Lambda, connectées à une tâche en plusieurs étapes au sein d’un service AWS Step Functions.
En général, une détection initiale est nécessaire juste après la collecte des images et leur prétraitement dans le compartiment S3. C’est à ce moment que vous générerez la détection d’anomalies élémentaires sur les images d’entrée et enregistrerez les résultats dans un lac de données, par exemple, représenté par la base de données Athena.
Dans certains cas, cette détection initiale n’est pas suffisante pour votre cas d’utilisation spécifique. Vous pouvez avoir besoin d’une analyse plus approfondie. Par exemple, le modèle initial (par exemple, Rekognition) peut détecter un problème sur l’équipement, mais il n’est pas possible d’identifier avec certitude le type de problème.
Dans ce cas, vous pouvez avoir recours à un autre modèle avec des capacités différentes. Par exemple, vous pourriez exécuter un autre modèle (par exemple, Lookout for Vision) sur le sous-ensemble d’images où le modèle initial a identifié un problème.
C’est aussi une bonne approche pour réduire les coûts, car vous n’avez pas besoin d’exécuter le deuxième modèle sur un ensemble complet d’images. Au lieu de cela, vous l’exécutez uniquement sur le sous-ensemble pertinent.
Les fonctions AWS Lambda exécuteront tous ces traitements à l’aide de code Python ou JavaScript. Cela dépend uniquement de la nature des processus et du nombre de fonctions AWS Lambda que vous devrez inclure dans un flux. La limite de 15 minutes pour la durée maximale d’un appel AWS Lambda déterminera le nombre d’étapes que ce processus doit contenir.
Derniers mots
Travailler avec des modèles d’apprentissage automatique dans le cloud est une tâche très intéressante. D’un point de vue technique et des compétences requises, une équipe diversifiée est nécessaire.
L’équipe doit comprendre comment entraîner un modèle, qu’il soit pré-construit ou conçu à partir de zéro. Cela implique de solides connaissances en mathématiques ou en algèbre pour équilibrer la fiabilité et les performances des résultats.
Il faut également des compétences avancées en codage Python ou JavaScript, en bases de données et en SQL. Et une fois que tout le travail de contenu est terminé, des compétences DevOps sont requises pour connecter le tout à un pipeline qui en fera un processus automatisé, prêt pour le déploiement et l’exécution.
Définir l’anomalie et entraîner le modèle est une étape. Mais intégrer le tout au sein d’une équipe opérationnelle capable de traiter les résultats des modèles et d’enregistrer les données de manière efficace et automatisée pour les mettre à disposition des utilisateurs finaux constitue un véritable défi.
Pour aller plus loin, découvrez tout sur la reconnaissance faciale pour les entreprises.