Prometheus se présente comme un système de supervision open source, fondé sur l’analyse de métriques. Son fonctionnement repose sur la collecte de données auprès de divers services et hôtes, obtenue par l’envoi de requêtes HTTP ciblant des points d’accès spécifiques aux métriques. Les données ainsi récoltées sont ensuite stockées dans une base de données de séries chronologiques, prêtes à être exploitées pour l’analyse et la configuration d’alertes.
Pourquoi mettre en place une surveillance ?
- La surveillance permet d’activer des alertes en cas d’anomalies, idéalement avant que celles-ci ne dégénèrent, donnant ainsi la possibilité d’une intervention rapide.
- Elle offre un ensemble d’informations cruciales pour l’analyse, le débogage et la résolution de problèmes.
- Elle permet de visualiser les tendances et les évolutions au fil du temps, comme le nombre de sessions actives à un instant T, facilitant ainsi les décisions en matière de conception et de planification des capacités.
La surveillance se concentre généralement sur les événements, qui peuvent inclure la réception d’une requête HTTP, l’envoi d’une réponse, la lecture à partir du disque ou une connexion utilisateur. La supervision d’un système peut englober le profilage, la journalisation, le traçage, l’analyse de métriques, les alertes et la visualisation des données.
Surveillance Blackbox vs Whitebox
La surveillance se divise en deux approches principales :
Surveillance de type boîte noire (Blackbox)
Avec la surveillance Blackbox, l’observation se fait au niveau de l’application ou de l’hôte, comme si on les examinait de l’extérieur. Cette approche peut parfois se révéler limitée en termes de détails.
Surveillance de type boîte blanche (Whitebox)
La surveillance Whitebox consiste à scruter les aspects internes d’un service. Elle expose des données relatives à l’état et aux performances des différents composants internes.
Les quatre indicateurs clés (Golden Signals)
Selon Google, si vous ne deviez mesurer que quatre métriques de votre système orienté utilisateur, concentrez-vous sur les quatre indicateurs suivants, désignés comme les quatre signaux d’or :
#1. Latence
C’est le temps nécessaire pour traiter une requête, qu’elle soit réussie ou non. Il est essentiel de suivre à la fois les demandes abouties et celles qui ont échoué.
#2. Trafic
Cette métrique représente la charge pesant sur votre système. Dans le cas d’un service web, il s’agit généralement du nombre de requêtes HTTP traitées par seconde.
#3. Erreurs
Il s’agit du pourcentage de requêtes qui échouent.
#4. Saturation
C’est une mesure du niveau d’occupation de votre service. Une augmentation de la latence est souvent un signe précurseur de saturation. Il est fréquent que les performances d’un système se dégradent bien avant d’atteindre son utilisation maximale (100%).
Types de métriques Prometheus
Les métriques gérées par Prometheus se répartissent en quatre catégories principales :
#1. Compteur
La valeur d’un compteur ne peut qu’augmenter ou être remise à zéro. Elle n’est jamais décroissante. Si une collecte de données échoue, seul un point de données est manqué. L’augmentation cumulée sera disponible lors de la prochaine récupération. Exemples :
- Le nombre total de requêtes HTTP reçues.
- Le nombre d’exceptions rencontrées.
#2. Jauge
Une jauge représente un instantané à un moment précis. Sa valeur peut évoluer à la hausse ou à la baisse. En cas d’échec de récupération de données, un échantillon est perdu ; la prochaine extraction peut afficher une valeur différente. Exemples : espace disque disponible, utilisation de la mémoire.
#3. Histogramme
Un histogramme effectue des échantillonnages et les regroupe dans des compartiments configurables. Il est utilisé pour mesurer des éléments tels que la durée des requêtes ou la taille des réponses. Par exemple, on peut mesurer la durée de traitement d’une requête HTTP spécifique. L’histogramme possède un ensemble de paliers, comme 1 ms, 10 ms et 25 ms. Au lieu de stocker chaque durée pour chaque requête, Prometheus enregistre la fréquence des requêtes se trouvant dans chaque palier.
#4. Sommaire
Similaires aux histogrammes, les données de type « sommaire » sont souvent utilisées pour suivre les durées ou les tailles des réponses. Elles fournissent le nombre total d’observations ainsi que la somme de toutes les valeurs observées, ce qui permet de calculer la moyenne des valeurs observées. Par exemple, si sur une minute, trois requêtes ont pris 2, 3 et 4 secondes, la somme serait de 9 et le nombre de 3, avec une latence moyenne de 3 secondes.
Composants de l’écosystème Prometheus
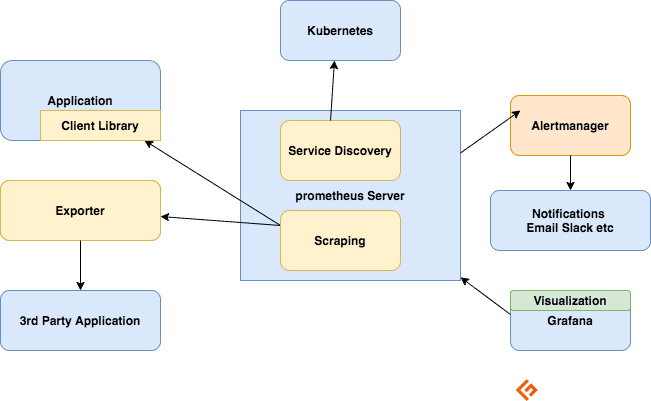
Le serveur Prometheus
Ce composant est chargé de collecter les métriques, de les stocker, de les rendre disponibles pour les requêtes et d’envoyer des alertes en fonction des métriques collectées.
Le processus de « scraping »
Prometheus fonctionne selon un modèle de « pull » (extraction). Pour récupérer les métriques, Prometheus initie une requête HTTP appelée « scrape ». Il envoie ces requêtes aux cibles en fonction de sa configuration.
Chaque cible, définie statiquement ou découverte dynamiquement, est interrogée à intervalles réguliers (intervalle de « scrape »). Chaque « scrape » lit le point d’accès HTTP « /metrics » pour obtenir l’état actuel des métriques du client et conserve ces valeurs dans la base de données de séries temporelles de Prometheus.
Il existe d’autres bases de données de séries chronologiques pour les solutions de surveillance que vous pourriez vouloir explorer.
Bibliothèques clientes
Pour surveiller un service, il est nécessaire d’ajouter une instrumentation à votre code. Des bibliothèques clientes sont disponibles pour tous les langages et environnements d’exécution courants. Avec quelques lignes de code, votre application peut commencer à émettre des métriques. C’est ce que l’on appelle l’instrumentation directe. Ces bibliothèques permettent de définir des métriques internes et de les exposer via un point d’accès HTTP. Lorsque Prometheus interroge le point d’accès HTTP des métriques, la bibliothèque cliente envoie ces métriques au serveur.
Prometheus propose des bibliothèques clientes officielles pour Go, Java, Python et Ruby. Grâce à son écosystème ouvert, des bibliothèques clientes développées par la communauté sont également disponibles pour C, PHP, Node.js, C#/.NET et bien d’autres.
Exportateurs
De nombreuses applications exposent des métriques dans un format autre que celui de Prometheus. Pour ces applications, ainsi que pour celles auxquelles vous n’avez pas accès au code, il n’est pas possible d’ajouter une instrumentation directe. C’est le cas par exemple de MySQL, Kafka, JMX, HAProxy ou du serveur NGINX. Dans ces situations, on utilise des exportateurs.
Un exportateur est un outil déployé avec l’application dont vous souhaitez extraire les métriques. Il agit comme un intermédiaire entre l’application et Prometheus. Il reçoit les requêtes du serveur Prometheus, collecte les données des journaux d’accès ou des journaux d’erreurs, les convertit au format approprié et les renvoie au serveur Prometheus.
Voici quelques exportateurs couramment utilisés :
- Windows – pour les métriques de serveurs Windows
- Node – pour les métriques de serveurs Linux
- Blackbox – pour mesurer les performances DNS et de sites web
- JMX – pour les métriques d’applications basées sur Java
Une fois que les applications ont été instrumentées ou que les exportateurs sont en place, il faut indiquer à Prometheus où les trouver. Cela peut être fait par une configuration statique. Dans les environnements dynamiques, la découverte de service est employée.
Alertes
Le système d’alerte de Prometheus se compose de deux éléments :
Des règles d’alerte envoient des notifications à Alertmanager.
Alertmanager se charge ensuite de gérer ces alertes. Il envoie des notifications via diverses intégrations (e-mail, Slack, Hipchat, PagerDuty). Alertmanager peut également effectuer la mise en sourdine ou l’agrégation pour réduire le nombre de notifications.
Vous trouverez ici un guide pour surveiller un serveur Linux avec Prometheus et un tableau de bord.
Visualisation à l’aide de tableaux de bord
Prometheus fournit des API permettant aux requêtes PromQL de générer des données brutes destinées aux visualisations.
Bien que Prometheus intègre un explorateur d’expressions utilisable pour des requêtes ponctuelles, l’outil de référence pour la visualisation est Grafana. Celui-ci s’intègre parfaitement avec Prometheus pour produire une grande variété de tableaux de bord.
Il faudra configurer Prometheus comme source de données pour Grafana.
Il est possible d’ajouter des tableaux de bord en :
- Important des tableaux de bord conçus par la communauté
- Créant vos propres tableaux
- Utilisant des tableaux de bord prédéfinis
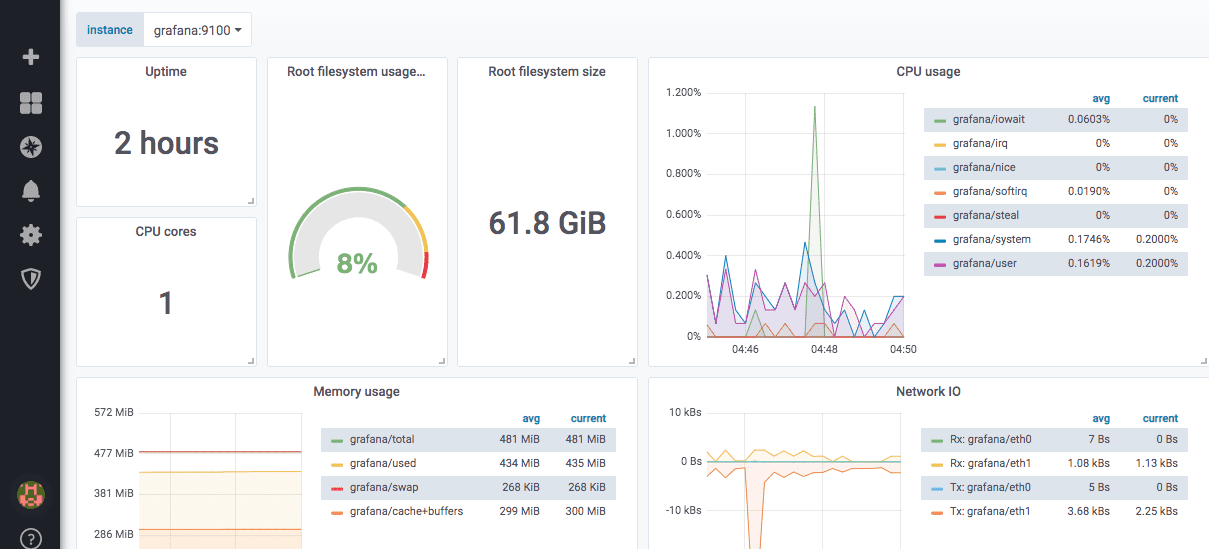
Voici un aperçu d’un tableau de bord prédéfini pour l’exportateur de nœuds :
Grafana propose un module worldPing qui permet de surveiller les métriques de performance des sites et du DNS à l’échelle mondiale.
En résumé
Prometheus est très peu exigeant en ressources. Il est relativement simple à mettre en œuvre, car il s’agit d’un simple exécutable avec un fichier de configuration. Il peut gérer des milliers de cibles et ingérer des millions d’échantillons par seconde. Prometheus est conçu pour suivre l’état de santé et le comportement global d’un système.
Grafana est l’outil le plus approprié pour visualiser les métriques et fonctionne de façon harmonieuse avec Prometheus.