Si vous avez acquis des compétences dans divers langages de programmation, vous avez probablement rencontré le concept d’analyse de texte. Cette technique est essentielle pour simplifier des ensembles de données complexes contenus dans un fichier. Cet article vous guidera à travers les méthodes d’analyse de texte en utilisant un langage de programmation. De plus, si vous avez déjà rencontré une erreur lors de l’analyse de texte (erreur d’analyse x), vous trouverez ici des solutions pour la corriger.
Comprendre l’analyse de texte
Nous vous proposons un guide complet pour l’analyse de texte, explorant différentes approches et détaillant les principes fondamentaux de cette technique.
Qu’est-ce que l’analyse de texte ?
Avant d’explorer les concepts d’analyse de texte à l’aide de code, il est crucial d’avoir une base solide dans les principes des langages de programmation et du codage.
Le Traitement du Langage Naturel (NLP)
L’analyse de texte s’appuie souvent sur le Traitement du Langage Naturel (NLP), un sous-domaine de l’intelligence artificielle. Le langage Python est fréquemment utilisé dans ce contexte pour analyser le texte.
Les algorithmes de NLP permettent aux ordinateurs d’interpréter et de traiter le langage humain. Pour appliquer des techniques d’apprentissage automatique au langage, il est nécessaire de convertir les données textuelles non structurées en données tabulaires structurées. Le langage Python est alors utilisé pour modifier les codes du programme et réaliser l’analyse.
Définition de l’analyse de texte
L’analyse de texte consiste fondamentalement à transformer des données d’un format vers un autre. Le format initial du fichier doit être analysé ou converti dans un format différent pour permettre son utilisation dans diverses applications.
- Autrement dit, le processus consiste à examiner une chaîne de caractères ou un texte et à le traduire en éléments logiques, tout en modifiant le format du fichier.
- Pour ce faire, on utilise certaines règles du langage Python, qui est souvent utilisé pour cette tâche. L’analyse de texte décompose la séquence de texte en composants plus petits.
Pourquoi l’analyse de texte est-elle nécessaire ?
Cette section explique pourquoi l’analyse de texte est importante et présente les connaissances fondamentales nécessaires pour comprendre son fonctionnement.
- Les données informatiques n’existent pas toutes dans un format uniforme et peuvent varier selon les applications.
- Les formats de données sont différents selon les besoins des applications et un code incompatible pourrait générer des erreurs.
- Il n’existe pas de programme unique qui puisse lire les données de tous les formats.
Méthode 1 : Utilisation de la classe DataFrame
La classe DataFrame de Python possède les fonctionnalités nécessaires pour analyser du texte. Cette bibliothèque comprend les outils requis pour convertir des données d’un format vers un autre.
Présentation de la classe DataFrame
La classe DataFrame est une structure de données puissante et polyvalente. Elle est souvent utilisée comme outil pour l’analyse de données, permettant l’analyse avec un minimum d’efforts.
- Le code est lu dans un pandas DataFrame pour réaliser l’analyse avec Python.
- Cette classe propose plusieurs fonctionnalités via les packages pandas, souvent utilisés par les analystes de données.
- L’abstraction est une caractéristique de cette classe : le fonctionnement interne de la fonction est masqué à l’utilisateur. La bibliothèque NumPy, qui fournit des fonctions pour travailler avec des tableaux, est la base de cette abstraction.
- La classe DataFrame peut représenter un tableau à deux dimensions, avec plusieurs index de lignes et de colonnes, facilitant le stockage de données multidimensionnelles. Ces index, appelés MultiIndex, nécessitent une manipulation pour corriger les erreurs d’analyse.
Les outils pandas permettent d’effectuer des opérations de style SQL, ou de base de données, de manière précise pour éviter les erreurs lors de l’analyse de texte. Elle intègre des fonctions d’E/S pour analyser les fichiers CSV, MS Excel, JSON, HDF5 et d’autres formats de données.
Analyse de texte avec DataFrame : Le processus
Voici les étapes à suivre pour analyser du texte à l’aide de la classe DataFrame.
- Déterminer le format de données du fichier d’entrée.
- Choisir le format de sortie des données (par exemple, CSV).
- Écrire le code en utilisant un type de données primitif tel que list ou dict.
Note : Travailler avec un DataFrame vide peut être compliqué. Pandas permet de créer les données sur la classe DataFrame à partir de ces types de données. Il est donc possible d’analyser facilement les données du type primitif dans le format souhaité.
- Analyser les données à l’aide de l’outil d’analyse pandas DataFrame et afficher le résultat.
Option I : Format standard
Voici une explication de la méthode standard pour formater un fichier avec un format de données spécifique, tel que CSV.
- Enregistrez le fichier contenant les données sur votre ordinateur. Vous pouvez le nommer data.txt, par exemple.
- Importez le fichier dans pandas en lui donnant un nom spécifique, et chargez les données dans une autre variable. Dans le code, pandas est importé sous le nom pd, par exemple.
- L’importation doit inclure le nom du fichier d’entrée, la fonction, et le format du fichier.
Note : La variable « res » est utilisée ici pour lire les données du fichier « data.txt » à l’aide de la fonction pandas, importée sous le nom « pd ». Le format de données d’entrée est spécifié comme CSV.
- Appelez le type de fichier et affichez le résultat de l’analyse. Par exemple, la commande « res » après l’exécution de la ligne de commande affiche le texte analysé.
Voici un exemple de code pour illustrer ce processus :
import pandas as pd
res = pd.read_csv('data.txt')
res
Dans cet exemple, si le fichier « data.txt » contient les données [1,2,3], le résultat affiché sera 1 2 3.
Option II : Méthode de chaîne
Si le texte contient uniquement des chaînes de caractères, les caractères spéciaux tels que les virgules ou les espaces peuvent être utilisés pour séparer et analyser le texte. Le processus est similaire aux opérations courantes sur les chaînes internes. Pour corriger une erreur d’analyse, suivez le processus décrit ci-dessous.
- Extrayez les données de la chaîne et notez tous les caractères spéciaux qui séparent le texte.
Dans l’exemple de code ci-dessous, les caractères spéciaux de la chaîne « my_string », qui sont « , », et « : », sont identifiés. Cette opération doit être réalisée avec soin pour éviter toute erreur.
- Le texte de la chaîne est divisé en fonction de la position des caractères spéciaux.
Par exemple, la chaîne est divisée en valeurs de données en fonction des caractères identifiés à l’aide de la commande « split ».
- Les valeurs de données de la chaîne sont affichées séparément en tant que texte analysé. L’instruction « print » est utilisée pour afficher les valeurs de données analysées.
Voici un exemple de code pour illustrer ce processus :
my_string = 'Names: Tech, computer'
sfinal = [name.strip() for name in my_string.split(':')[1].split(',')]
print("Names: {}".format(sfinal))
Le résultat de l’analyse de cette chaîne serait :
Names: ['Tech', 'computer']
Pour mieux comprendre comment analyser le texte en utilisant les chaînes de caractères, une boucle « for » peut être utilisée pour modifier le code de cette façon :
my_string = 'Names: Tech, computer'
s1 = my_string.split(':')
s2 = s1[1]
s3 = s2.split(',')
s4 = [name.strip() for name in s3]
for idx, item in enumerate([s1, s2, s3, s4]):
print("Step {}: {}".format(idx, item))
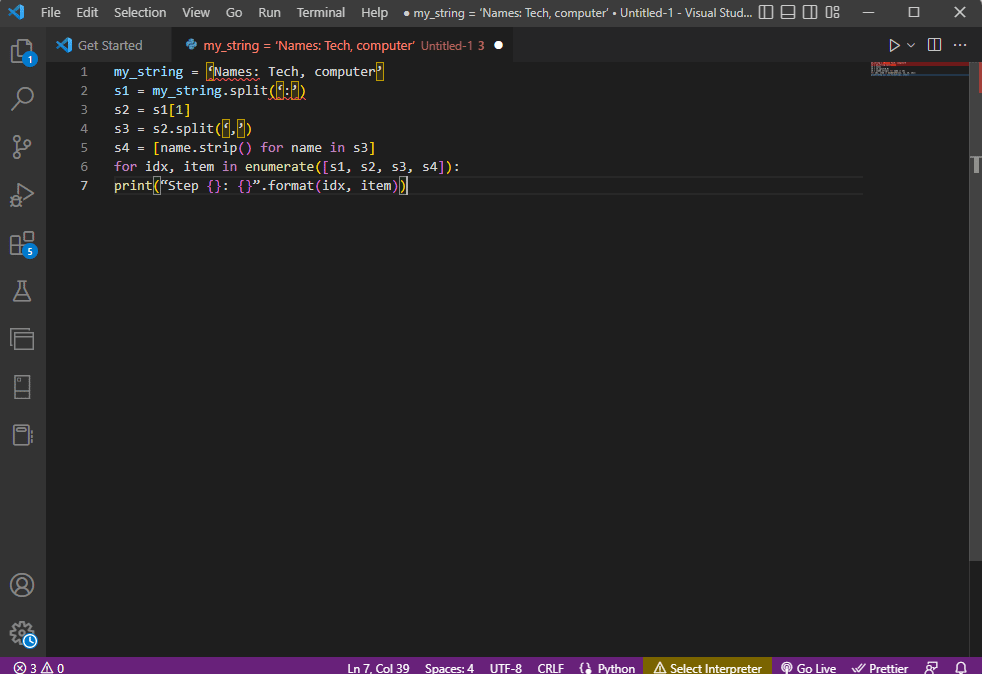
Le résultat de l’analyse à chaque étape est le suivant. Vous pouvez observer qu’à l’étape 0, la chaîne est divisée en fonction du caractère spécial « : » et que les valeurs de données sont séparées aux étapes suivantes.
Step 0: ['Names', 'Tech, computer'] Step 1: Tech, computer Step 2: [' Tech', ' computer'] Step 3: ['Tech', 'computer']
Option 3 : Analyse de fichiers complexes
Souvent, les données à analyser contiennent différents types et valeurs de données, ce qui rend les méthodes précédentes difficiles à appliquer. L’analyse de données complexes consiste à afficher les valeurs sous forme de tableau.
- Le titre ou les métadonnées sont affichés en haut du fichier.
- Les variables et les champs sont affichés dans la sortie sous forme de tableau.
- Les valeurs de données forment une clé composée.
Avant d’aborder l’analyse de texte avec cette méthode, il est important de comprendre quelques concepts fondamentaux. L’analyse des valeurs de données est basée sur les expressions régulières, ou Regex.
Modèles d’expressions régulières
Pour corriger les erreurs d’analyse, assurez-vous que les modèles Regex dans les expressions sont corrects. Les modèles Regex courants sont les suivants :
\d: correspond à un chiffre décimal.\s: correspond à un espace blanc.\w: correspond à un caractère alphanumérique.+ou*: effectue une correspondance « gourmande », en trouvant un ou plusieurs caractères.a-z: correspond aux groupes en minuscules.A-Zoua-z: correspond aux groupes majuscules et minuscules.0-9: correspond aux valeurs numériques.
Expressions régulières
Les modules d’expressions régulières sont un élément important de la bibliothèque pandas en Python et une expression mal formée peut entraîner une erreur. Les expressions régulières, ou Regex, sont des chaînes de caractères avec une syntaxe spécifique. Elles permettent de trouver des modèles dans d’autres chaînes.
L’expression régulière est créée en fonction du type de données. Par exemple, String = (.*)\n. L’expression régulière précède le modèle dans chaque expression. Voici quelques symboles utiles :
.: récupère n’importe quel caractère des données.*: utilise zéro ou plusieurs données de l’expression précédente.(.*): regroupe une partie de l’expression régulière entre parenthèses.\n: crée un nouveau caractère de ligne en fin de ligne.\d: crée une valeur entière (0 à 9).+: utilise une ou plusieurs données de l’expression précédente.|: crée une déclaration logique (OU).
RegexObjets
Le RegexObject est la valeur de retour de la fonction de compilation. Il retourne un MatchObject si l’expression correspond à une valeur.
1. MatchObject
La valeur booléenne d’un MatchObject est toujours True. Vous pouvez donc utiliser une instruction « if » pour identifier les correspondances positives. Le groupe référencé par l’index est utilisé pour trouver la correspondance de l’objet dans l’expression.
group()renvoie un ou plusieurs sous-groupes de correspondance.group(0)renvoie la correspondance entière.group(1)renvoie le premier sous-groupe entre parenthèses.- Pour référencer plusieurs groupes, on utilise une extension spécifique à Python, qui permet de spécifier le nom du groupe :
(?P. Pour corriger une erreur d’analyse, vérifiez que le groupe pointe correctement.regex1)
2. Méthodes de MatchObject
Le MatchObject a deux méthodes principales :
- La méthode
match(string)trouve les correspondances de la chaîne au début de l’expression régulière. - La méthode
search(string)parcourt la chaîne pour trouver une correspondance. Si la correspondance est trouvée, une instance du MatchObject est retournée, sinon c’est « None ».
Fonctions d’expressions régulières
Les fonctions Regex sont des lignes de code qui exécutent des opérations spécifiées par l’utilisateur sur l’ensemble des données.
Note : Pour éviter les erreurs, on utilise des chaînes brutes pour les expressions régulières en ajoutant l’indice « r » avant chaque modèle.
Voici quelques fonctions courantes :
1. re.findall()
Cette fonction renvoie tous les modèles qui correspondent à une chaîne. Si aucune correspondance n’est trouvée, une liste vide est retournée. Exemple : string = re.findall('[aeiou]', regex_filename) (trouver les voyelles dans un nom de fichier).
2. re.split()
Cette fonction divise la chaîne à chaque fois qu’un caractère spécifié est rencontré. Elle retourne une chaîne vide si aucune correspondance n’est trouvée.
3. re.sub()
Cette fonction remplace le texte correspondant par le contenu d’une variable de remplacement. Si aucun modèle n’est trouvé, la chaîne d’origine est retournée.
4. search()
Cette fonction recherche un modèle dans une chaîne et retourne un objet de correspondance. Si aucune correspondance n’est identifiée, aucune valeur n’est retournée.
5. re.compile(motif)
Cette fonction compile des modèles d’expressions régulières dans un RegexObject, tel que décrit précédemment.
Autres ressources
- Pour visualiser les expressions régulières, utilisez « regexper ».
- Pour tester les expressions régulières, utilisez « regex101 ».
Le processus d’analyse de texte
Voici les étapes pour analyser le texte dans cette option complexe :
- Comprendre le format d’entrée en lisant le contenu du fichier. Utilisez par exemple les fonctions « with open » et « read() » pour ouvrir et lire le fichier « sample ». Le fichier « sample » contient le contenu de « file.txt ». Il est important de lire tout le fichier pour corriger les erreurs.
- Afficher le contenu du fichier pour analyser manuellement les données et leurs métadonnées. Utilisez la fonction « print() ».
- Importer les outils nécessaires à l’analyse de texte. Donnez un nom à la classe pour faciliter le codage. Par exemple, importez les expressions régulières et pandas.
- Définir les expressions régulières nécessaires dans le fichier, en incluant le modèle regex et la fonction regex. Cela permet à l’objet texte d’être analysé.
- Utilisez la fonction « compile() » pour compiler la chaîne du groupe « stringname1 » du fichier « filename ». La commande « ief_parse_line(line) » utilise la fonction de vérification des correspondances de regex.
- Écrivez l’analyseur de ligne pour le code en utilisant « def_parse_file(filepath) ». Cette fonction vérifie toutes les correspondances d’expressions régulières dans la fonction spécifiée. La méthode « regex search() » recherche la clé « rx » dans le fichier « filename » et retourne la clé et la correspondance. Un problème à cette étape peut engendrer une erreur.
- L’étape suivante consiste à écrire un analyseur de fichiers en utilisant la fonction « def_parse_file(filepath) ». Une liste vide est créée pour collecter les données (data = []). La correspondance est vérifiée à chaque ligne, et les données de valeur exactes sont retournées en fonction du type de données.
- Pour extraire le nombre et la valeur du tableau, la ligne de commande « line.strip().split(‘,’) » est utilisée. La commande « row{} » crée un dictionnaire avec la ligne de données. « data.append(row) » comprend les données et les analyse dans un format tabulaire.
Utilisez la commande « data = pd.DataFrame(data) » pour créer un pandas DataFrame à partir des valeurs dict.
Vous pouvez également utiliser les commandes suivantes :
data.set_index(['string', 'integer']inplace=True)pour définir l’index du tableau.data = data.groupby(level=data.index.names).first()pour consolider et supprimer les NaN.data = data.apply(pd.to_numeric, errors='ignore')pour mettre à niveau le score de float à entier.
La dernière étape pour analyser le texte consiste à tester l’analyseur en utilisant l’instruction « if », en attribuant des valeurs à une variable et en l’affichant à l’aide de la commande « print(data) ».
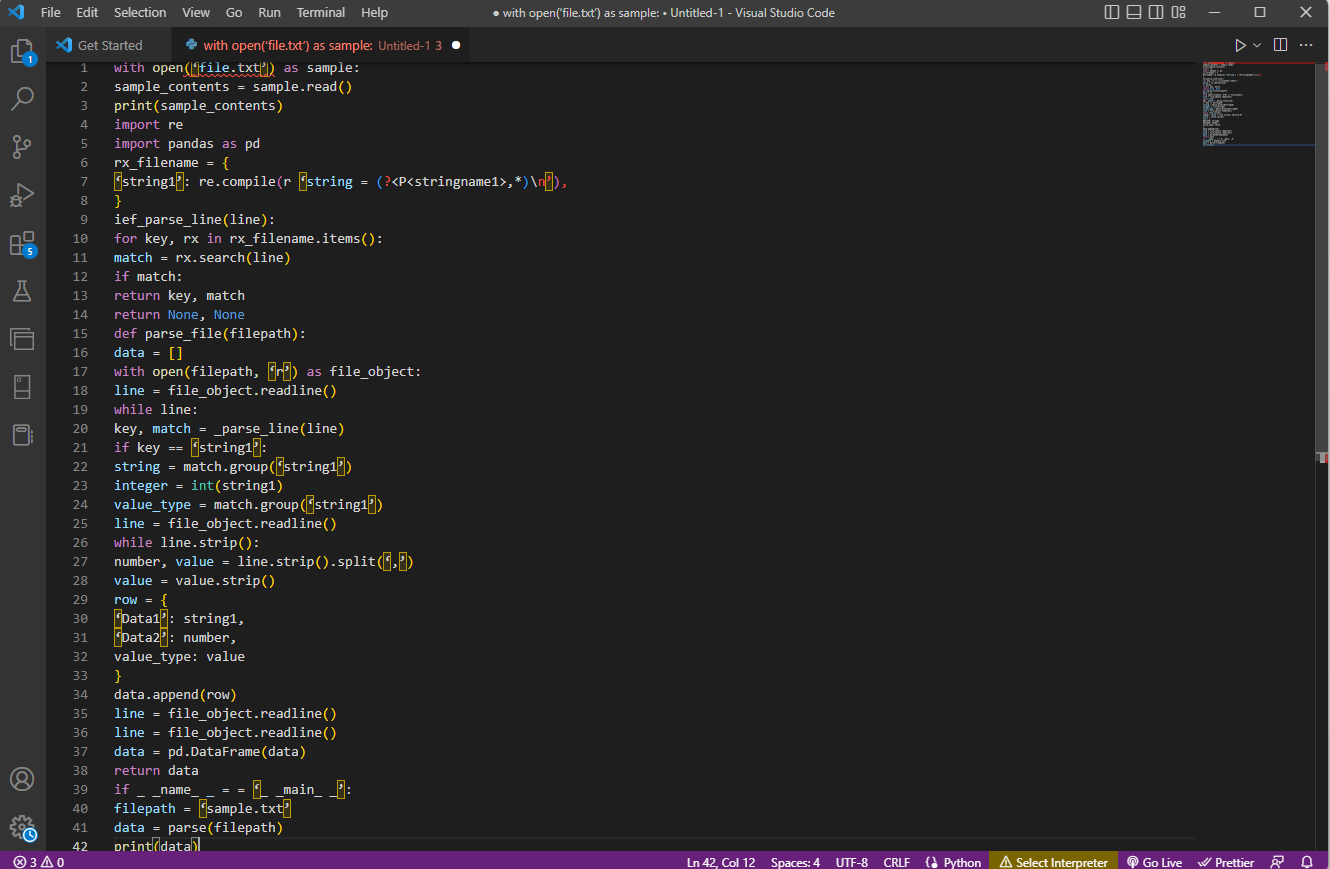
Voici un exemple de code qui illustre les étapes ci-dessus :
with open('file.txt') as sample:
sample_contents = sample.read()
print(sample_contents)
import re
import pandas as pd
rx_filename = {
'string1': re.compile(r'string = (?P,*)n'),
}
def ief_parse_line(line):
for key, rx in rx_filename.items():
match = rx.search(line)
if match:
return key, match
return None, None
def parse_file(filepath):
data = []
with open(filepath, 'r') as file_object:
line = file_object.readline()
while line:
key, match = _parse_line(line)
if key == 'string1':
string = match.group('string1')
integer = int(string1)
value_type = match.group('string1')
line = file_object.readline()
while line.strip():
number, value = line.strip().split(',')
value = value.strip()
row = {
'Data1': string1,
'Data2': number,
value_type: value
}
data.append(row)
line = file_object.readline()
line = file_object.readline()
data = pd.DataFrame(data)
return data
if __name__ == '__main__':
filepath = 'sample.txt'
data = parse(filepath)
print(data)
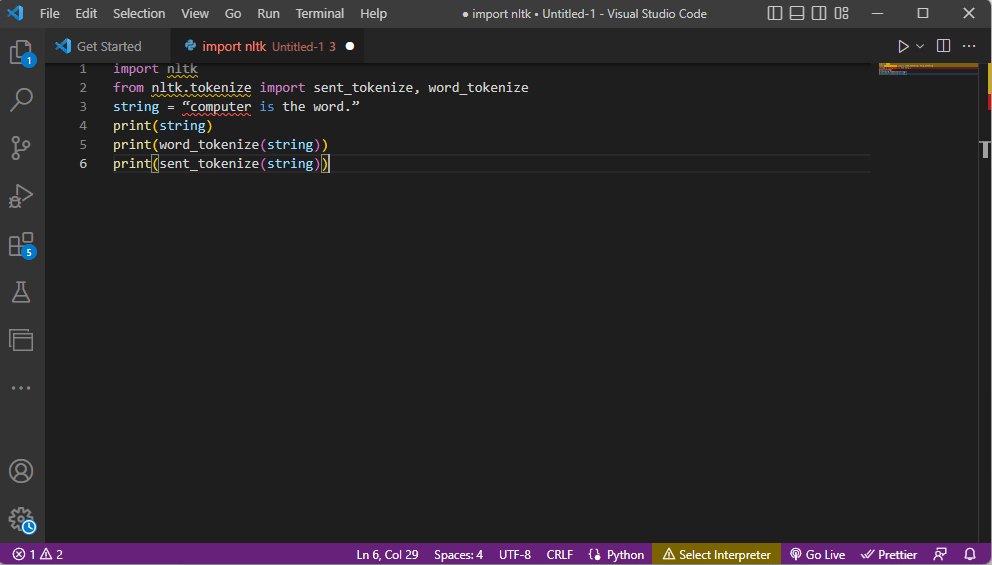
Méthode 2 : La tokenisation de mots
La tokenisation est le processus de conversion d’un texte en jetons (ou « tokens »). Ces jetons sont des unités plus petites. Il est important d’analyser correctement les commandes de tokenisation pour éviter les erreurs. Des règles peuvent être définies pour cette méthode, ce qui facilite le prétraitement du texte. Des activités telles que la recherche de mots, le nettoyage de texte, et la préparation des données pour l’analyse des sentiments font partie de cette méthode. Une mauvaise tokenisation peut causer des erreurs.
La bibliothèque NLTK
La bibliothèque NLTK (Natural Language Toolkit) est un outil puissant avec de nombreuses fonctions pour le NLP. Elle peut être téléchargée avec « pip ». On peut également l’utiliser par défaut dans la distribution Anaconda.
Les formes de tokenisation
Les deux formes courantes sont la segmentation de mots et la segmentation de phrases. La segmentation de mots affiche chaque mot une seule fois, tandis que la segmentation de phrases affiche les phrases complètes.
Processus d’analyse de texte
- Importer la bibliothèque « nltk » et les fonctions de tokenisation.
- Définir une chaîne de caractères et les commandes de tokenisation.
- Lors de l’affichage de la chaîne, la sortie sera : « ordinateur est le mot ».
- Avec la fonction « word_tokenize() », chaque mot est affiché entre guillemets et séparé par une virgule : ‘ordinateur’, ‘est’, ‘le’, ‘mot’, ‘.’
- Avec la fonction « sent_tokenize() », les phrases individuelles sont affichées entre guillemets : « l’ordinateur est le mot. »
Voici le code illustrant les étapes de tokenisation ci-dessus :
import nltk from nltk.tokenize import sent_tokenize, word_tokenize string = "computer is the word." print(string) print(word_tokenize(string)) print(sent_tokenize(string))
Méthode 3 : Utilisation de la classe DocParser
Comme la classe DataFrame, la classe DocParser peut être utilisée pour analyser du texte en utilisant un chemin de fichier.
Processus d’analyse de texte
Voici les instructions pour analyser du texte avec la classe DocParser :
- La fonction « get_format(filename) » extrait l’extension du fichier, la renvoie à une variable et la transmet à la fonction suivante. Par exemple, « p1 = get_format(filename) » extrait l’extension du fichier, la stocke dans la variable « p1 » et la passe à la fonction suivante.
- Une structure logique avec des instructions « if-elif-else » est mise en place.
- Si l’extension est valide, la fonction « get_parser » analyse les données et retourne l’objet string.
Note : Cette fonction doit être implémentée correctement pour éviter des erreurs d’analyse.
- L’analyse se base sur l’extension du fichier. L’implémentation concrète de la classe (« parse_txt » ou « parse_docx ») génère des objets « string » à partir du type de fichier donné.
- L’analyse peut être effectuée pour d’autres extensions (parse_pdf, parse_html, parse_pptx).
- Les données et l’interface peuvent être importées dans d’autres applications en instanciant un objet DocParser. Il est crucial d’effectuer cette opération correctement pour éviter les erreurs.
Méthode 4 : Utilisation d’un outil d’analyse de texte
Les outils d’analyse de texte extraient des données et les relient à d’autres variables. L’outil BPA Platform est utilisé pour générer des variables. Utilisez ce lien pour accéder à un outil d’analyse de texte en ligne.
Méthode 5 : Utilisation de TextFieldParser (Visual Basic)
TextFieldParser permet d’analyser de très grands fichiers structurés. On utilise cette méthode pour analyser des fichiers journaux, des bases de données, ou des fichiers de largeur fixe. L’analyse se fait en itérant sur un fichier texte, et en extrayant les champs de texte de la même manière que les méthodes de manipulation de chaînes. On utilise un délimiteur (virgule, espace, tabulation) pour séparer les chaînes.
Fonctions pour analyser du texte
Voici les fonctions utilisables dans cette méthode :
SetDelimitersdéfinit un délimiteur. Par exemple,testReader.SetDelimiters (vbTab)définit la tabulation comme délimiteur.SetFieldWidthsdéfinit une largeur de champ (valeur entière positive). Par exemple,testReader.SetFieldWidths (entier).testReader.TextFieldType = Microsoft.VisualBasic.FileIO.FieldType.FixedWidthpermet de tester le type de champ du texte.
Méthodes pour trouver MatchObject
Voici les deux méthodes principales pour trouver le MatchObject :
- Définir le format et parcourir le fichier avec la méthode
ReadFields, ce qui permet de traiter chaque ligne du code. - Utiliser la méthode
PeekCharspour vérifier chaque champ individuellement avant de le lire.
Si un champ ne correspond pas au format spécifié lors de l’analyse, une exception MalformedLineException est retournée.
Conseil : Analyse de texte avec MS Excel
MS Excel peut être utilisé pour créer des fichiers délimités par des tabulations ou des virgules. Cela permet de vérifier le résultat de l’analyse et de corriger les erreurs.
1. Sélectionnez les données dans le fichier source et copiez-les avec Ctrl + C.
2. Ouvrez Excel.
3. Cliquez sur la cellule A1 et collez le texte avec Ctrl + V.
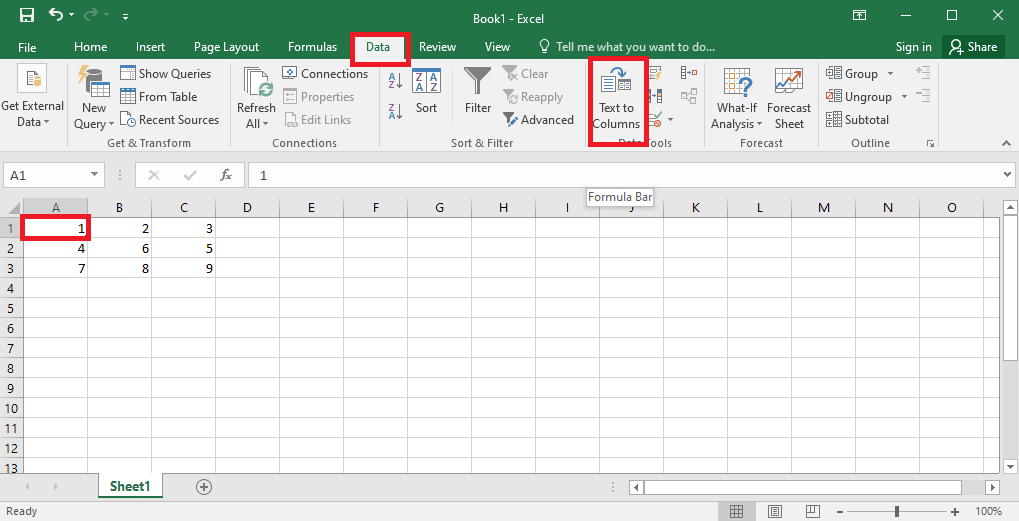
4. Sélectionnez la cellule A1, allez dans l’onglet « Données » et cliquez sur « Texte en colonnes ».
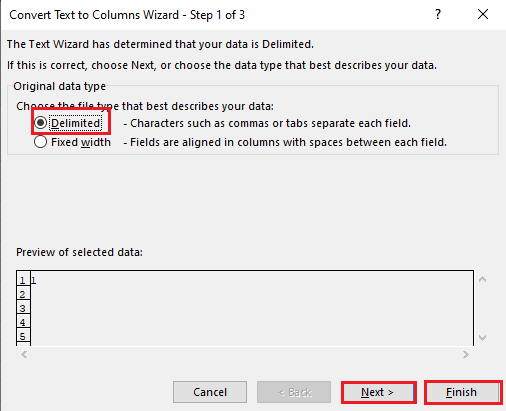
5A. Choisissez l’option « Délimité » si un séparateur (virgule ou tabulation) est utilisé, puis cliquez sur « Suivant » et « Terminer ».
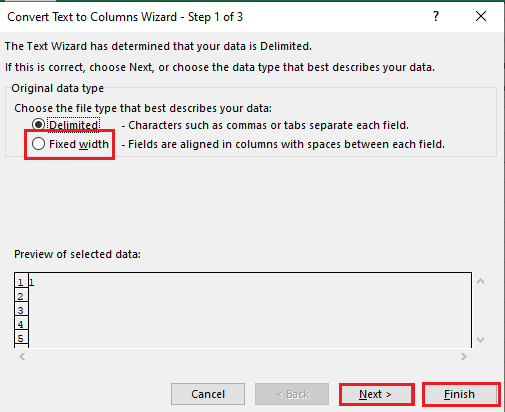
5B. Choisissez l’option « Largeur fixe », attribuez une valeur au séparateur, et cliquez sur « Suivant » et « Terminer ».
Comment corriger les erreurs d’analyse
Une erreur d’analyse peut survenir sur les appareils Android (« Erreur d’analyse : un problème est survenu lors de l’analyse du package »). Cela se produit généralement quand l’application ne parvient pas à s’installer depuis le Google Play Store, ou lors de l’exécution d’une application tierce.
L’erreur peut également se produire si une liste de caractères est bouclée et que d’autres fonctions forment un modèle linéaire pour calculer les valeurs de données : « Error in parse(text = x, keep.source = FALSE):
Consultez des articles sur la façon de corriger les erreurs d’analyse sur Android pour plus de détails.
Voici quelques correctifs à essayer :
- Télécharger à nouveau le fichier .apk ou restaurer le nom du fichier.
- Restaurer les modifications dans le fichier « AndroidManifest.xml », si vous avez des compétences en programmation avancées.
***
Cet article vous a guidé à travers les principes de l’analyse de texte et les méthodes pour corriger les erreurs. N’hésitez pas à partager vos suggestions et questions dans la section des commentaires ci-dessous.