5 services AWS natifs capables de créer une plate-forme sans serveur de bout en bout
L'Évolution vers les Architectures Sans Serveur
Pendant de nombreuses années, la mise en place d'un système logiciel automatisé impliquait la configuration de multiples serveurs, chacun doté de ressources dédiées telles que le CPU, la mémoire et le stockage. Une équipe d'administrateurs était ensuite chargée de la gestion de ces systèmes. Par la suite, l'équipe de développement prenait le relais pour créer des processus reliant ces serveurs.
Ce processus s'avérait complexe, nécessitant une collaboration étroite entre diverses équipes, ce qui pouvait engendrer des conflits d'intérêts et des difficultés.
De plus, cette approche était souvent coûteuse, impliquant des dépenses en personnel pour les administrateurs et une consommation continue de ressources par les serveurs, même lorsqu'ils étaient inactifs.
Afin de maintenir des performances optimales, une solution d'autoscaling était nécessaire pour ajuster automatiquement les ressources des serveurs en fonction des besoins.
La plateforme cloud a révolutionné ce paysage, offrant la possibilité de concevoir une architecture complète sans avoir à configurer un cluster de serveurs. Du point de vue administratif, cette approche élimine la nécessité de maintenance.
Elle s'avère particulièrement avantageuse pour les startups et les phases de produit minimum viable (MVP) de projets, constituant un excellent point de départ lorsque les charges de production et l'activité des utilisateurs sont difficiles à anticiper. Dans de tels cas, la configuration des serveurs du cluster peut s'avérer ardue.
L'automatisation des processus via des services cloud sans serveur est la caractéristique distinctive de l'architecture sans serveur. Elle relie les services entre eux et produit des résultats similaires à ceux obtenus avec des serveurs de cluster traditionnels.
Nous allons maintenant examiner un exemple de construction d'une telle architecture en utilisant uniquement des services natifs d'AWS.
Exploration du Flux de Services Sans Serveur
Imaginons que vous souhaitiez créer une plateforme pour collecter des données et des images relatives à l'infrastructure d'actifs concrets (qu'il s'agisse de biens de fabrication ou de services).
- Afin de permettre des analyses ultérieures, les données entrantes doivent d'abord être ingérées.
- Après application de règles métier, une procédure dorsale enregistre les résultats calculés sous forme d'informations normalisées dans une base de données relationnelle.
- Une application frontale affichant des données propres et normalisées permet aux utilisateurs de visualiser les résultats.
Analysons les composants que pourrait inclure cette architecture.
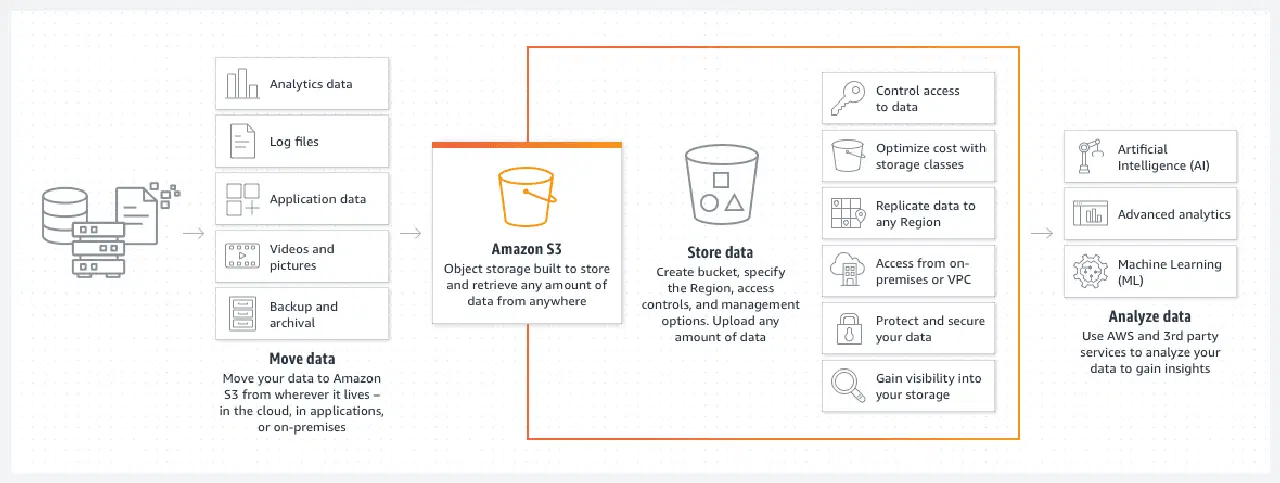
Buckets AWS S3
 Source : aws.amazon.com
Source : aws.amazon.com
Les buckets Amazon S3 sont un excellent moyen de stocker des fichiers ou des images dans le cloud AWS, notamment grâce à leur coût très avantageux. La mise en place d'une politique de cycle de vie pour le bucket S3 permet de réduire encore ce coût.
Une telle stratégie déplacera automatiquement les fichiers anciens vers différentes classes de buckets S3, telles que l'archive ou l'accès aux archives profondes. Ces classes diffèrent par leur temps d'accès, mais cela importe moins pour les données anciennes, destinées à être consultées en cas d'urgence plutôt que pour des besoins opérationnels courants.
- Vous pouvez organiser vos données en sous-dossiers.
- Vous devez définir des restrictions d'autorisation appropriées.
- Ajoutez des étiquettes aux buckets afin de faciliter leur identification et leur utilisation dans les politiques de bucket S3 dynamiques.
- Un bucket est par nature sans serveur, car il s'agit simplement d'un espace de stockage pour vos données.
Un bucket S3 est, de par sa conception, sans serveur. Il n'est qu'un espace de stockage pour vos informations.
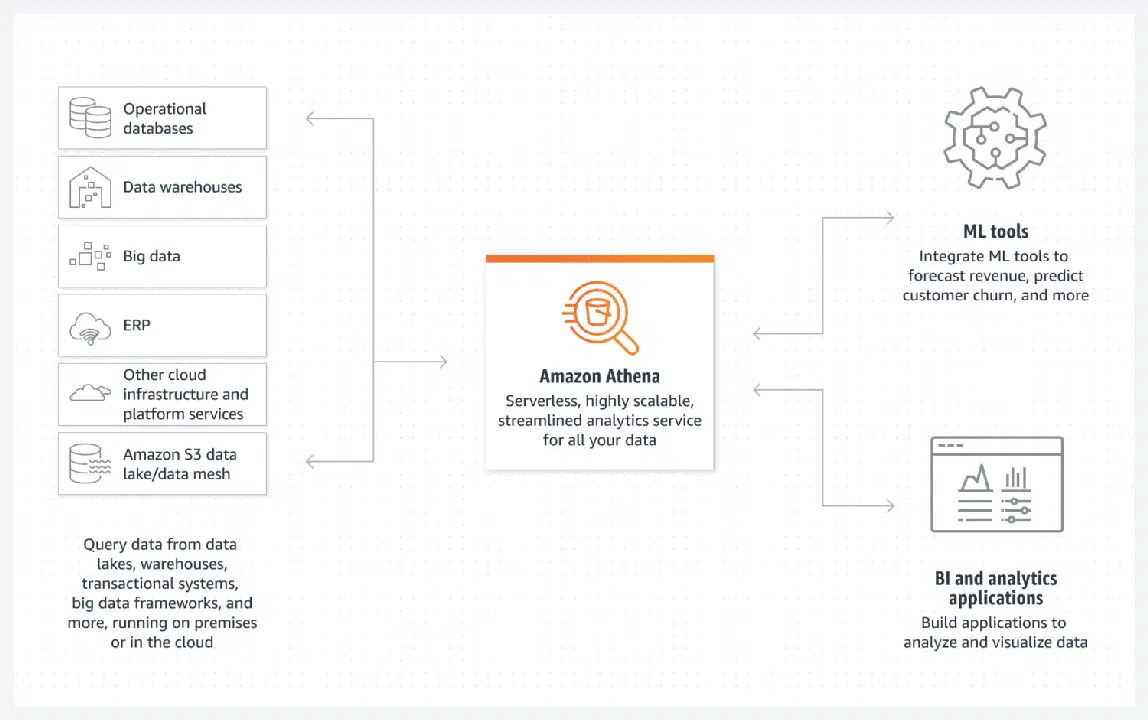
Base de Données AWS Athena
 Source : aws.amazon.com
Source : aws.amazon.com
Athena facilite la création d'un lac de données de base sur AWS. Il s'agit d'une base de données sans serveur qui utilise un bucket S3 pour stocker ses données. L'organisation des données est maintenue par des formats de fichiers structurés, tels que les fichiers Parquet ou CSV (valeurs séparées par des virgules). Le bucket S3 contient les fichiers et Athena s'y réfère lorsque les processus sélectionnent les données de la base de données.
Il est important de noter qu'Athena ne prend pas en charge certaines fonctionnalités considérées comme standard, telles que les instructions de mise à jour. Il est donc préférable de considérer Athena comme une option simple.
Cependant, elle prend en charge l'indexation et le partitionnement et peut évoluer horizontalement très facilement, car cela revient à ajouter de nouveaux buckets à l'infrastructure. Cela peut être suffisant dans la plupart des cas pour la création d'un lac de données simple mais fonctionnel.
Pour garantir de bonnes performances, il est essentiel de choisir une conception de données adaptée à une utilisation future. Il est crucial d'avoir une idée précise de la manière dont vous souhaitez sélectionner les données, car il est difficile de recréer des tables une fois qu'elles sont en place et qu'elles contiennent de grandes quantités de données.
Athena DB est un excellent choix et répond parfaitement à vos besoins si vous souhaitez créer un pool de données simple, immuable et facile à mettre à l'échelle horizontalement.
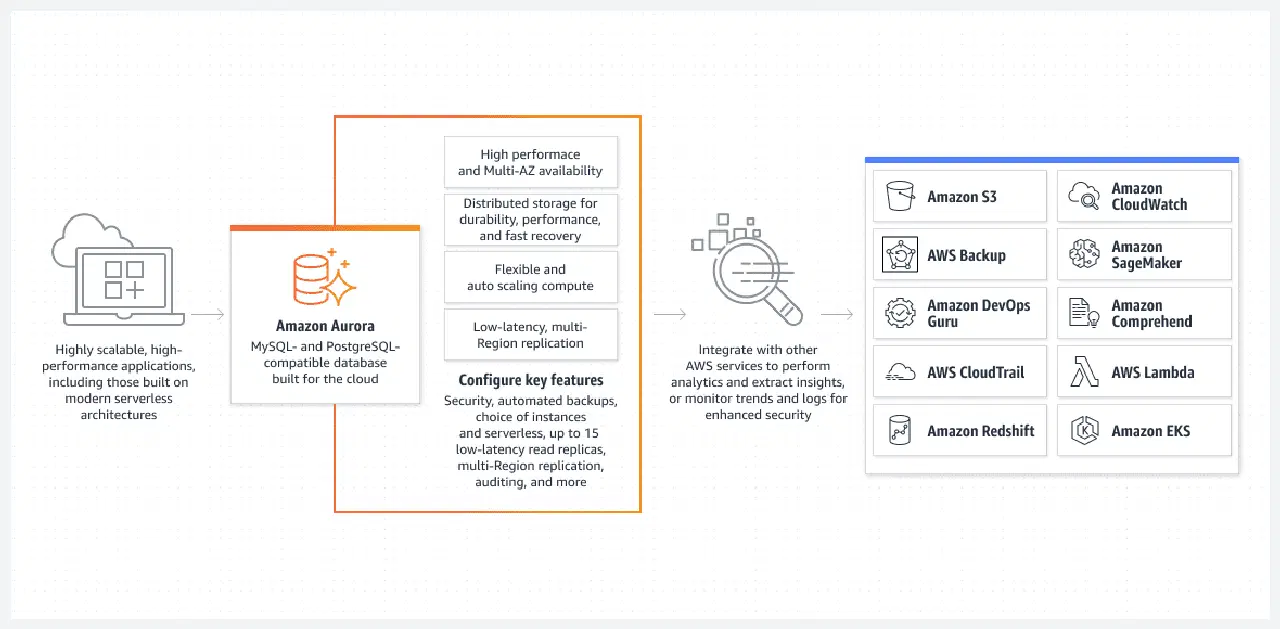
Base de Données AWS Aurora
 Source : aws.amazon.com
Source : aws.amazon.com
Athena DB est idéale pour le stockage de données non conservées. C'est ainsi que vous devez stocker votre contenu original pour maximiser sa réutilisation future. Cependant, elle peut être lente pour fournir des résultats sélectionnés à une application frontale.
La base de données Aurora, exécutée en mode sans serveur, est l'une des meilleures options, notamment en raison de sa facilité de configuration.
Aurora est bien plus qu'une simple base de données. Il s'agit de l'une des solutions de bases de données relationnelles natives les plus avancées d'AWS, et elle s'améliore à chaque nouvelle version.
Aurora se distingue par sa capacité à fonctionner en mode sans serveur, ce qui la différencie des autres services relationnels. Voici comment fonctionne ce mode :
- Pour configurer le cluster Aurora, vous devez utiliser la console AWS et spécifier les niveaux standard de CPU et de RAM, ainsi que l'intervalle maximal de la fonctionnalité d'autoscaling. Cela déterminera les performances que le cluster Aurora pourra ajouter ou supprimer dynamiquement. AWS décide d'augmenter ou de réduire les ressources en fonction de l'utilisation actuelle de la base de données.
- Le cluster Aurora ne démarre que si un utilisateur ou un processus lance une demande réelle, par exemple, lorsqu'un traitement par lots planifié démarre, ou lorsqu'une application effectue un appel d'API backend pour récupérer des données. La base de données s'ouvre automatiquement et reste active pendant une période prédéterminée après la fin des processus de demande.
- Le cluster Aurora s'arrête automatiquement s'il n'y a plus d'activité au niveau de la base de données.
Pour insister, la base de données Aurora sans serveur ne s'exécute que lorsqu'elle doit effectuer un travail réel. Le cluster démarré automatiquement se désactive s'il n'y a plus d'activité. Vous ne payez donc que pour le travail réel effectué, et non pour le temps d'inactivité.
L'Aurora sans serveur est entièrement gérée par AWS et ne nécessite pas d'administrateur.
Amplificateur AWS
Amplify offre une plateforme sans serveur pour le déploiement rapide d'applications frontales réalisées avec des bibliothèques JavaScript et React. Il n'est pas nécessaire de configurer des serveurs de cluster. Vous pouvez utiliser la console AWS pour déployer directement le code ou opter pour un pipeline DevOps automatisé.
Vous pouvez appeler des API backend pour accéder aux données stockées dans les bases de données. Ces appels vous permettent d'accéder aux données réelles dans l'application frontale. L'optimisation des performances côté backend incombe à l'équipe. Une conception efficace des requêtes de sélection dans les appels d'API permet de minimiser davantage les risques de lenteur de la réponse dans l'interface utilisateur.
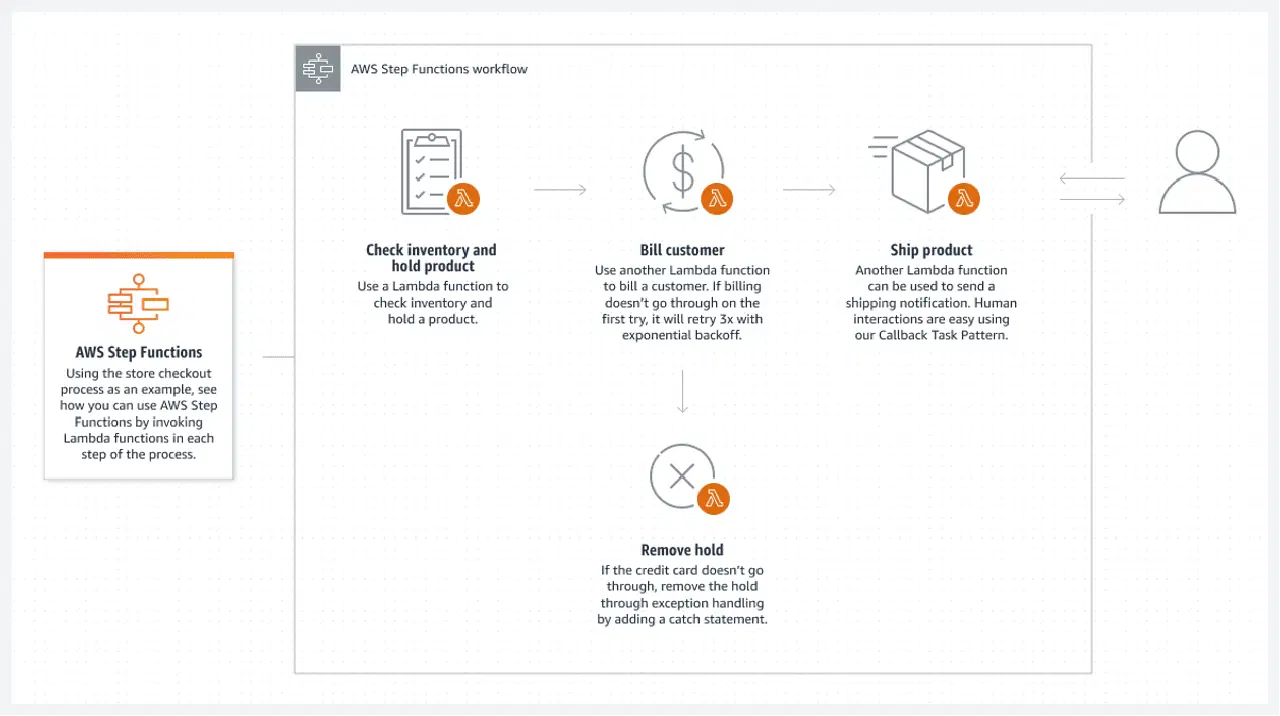
Fonctions Step d'AWS
 Source : aws.amazon.com
Source : aws.amazon.com
Même si tous les composants principaux d'un système sont sans serveur, cela ne garantit pas une architecture entièrement sans serveur. Une telle architecture nécessite également que tous les traitements par lots entre les composants soient sans serveur.
Les fonctions Step d'AWS constituent la meilleure solution pour le cloud AWS. Une fonction Step se compose d'une liste connectée de fonctions AWS Lambda. Ces fonctions créent un organigramme avec des états de début et de fin clairement définis. Une fonction Lambda, généralement écrite en Python ou Node JS, est un morceau de code exécutable qui effectue tous les traitements nécessaires.
Voici un exemple de la manière dont vous pouvez exécuter une fonction Step :
- AWS déclenche une fonction Lambda automatique chaque fois qu'un nouveau fichier arrive dans le dossier S3. Après avoir analysé le fichier, la fonction Lambda le charge dans Athena. Elle enregistre ensuite ses résultats au format CSV sur un bucket S3 (ou dans une table de suivi de base de données) avant de se fermer.
- Ce résultat est ensuite utilisé par la fonction Lambda suivante pour effectuer les étapes suivantes, telles que l'appel d'un modèle d'apprentissage automatique et la transformation d'un sous-ensemble des nouvelles données en tables normalisées. La dernière étape peut consister à charger les données dans la base de données Aurora.
- Une fonction Step relie ces fonctions Lambda pour former un flux par lots. Il est même possible d'avoir une autre fonction Step exécutée à la place d'une étape d'une autre fonction Step racine, ce qui permet de couvrir de nombreux scénarios.
Ce flux sans serveur a un inconvénient : chaque fonction Lambda ne peut s'exécuter que pendant 15 minutes maximum. Il est donc préférable de diviser le flux en fonctions Lambda plus petites afin de limiter les risques.
Il est possible d'appeler plusieurs fonctions Lambda simultanément en une seule étape, ce qui permet de paralléliser une étape avec plusieurs fonctions Lambda s'exécutant en parallèle. Il suffit d'attendre la fin de tous les traitements Lambda parallèles avant de passer à la fonction Lambda suivante.
Dernières Réflexions
L'architecture sans serveur offre une opportunité unique de créer une plateforme cloud couvrant l'ensemble du paysage système. Cette plateforme est évolutive horizontalement et a des coûts d'exploitation réduits.
Elle constitue la solution idéale pour les projets à budget limité, ainsi qu'une excellente option d'exploration, en particulier lorsque la charge de production est inconnue. Cela est d'autant plus important une fois que vous avez réussi à intégrer tous les utilisateurs. Les équipes de projet bénéficient d'une vue d'ensemble du fonctionnement du système, sans avoir à faire de compromis.
Cette approche ne convient cependant pas à tous les cas, notamment ceux qui nécessitent une utilisation importante du processeur. Néanmoins, le cloud AWS évolue constamment en matière de cas d'utilisation sans serveur. Il est donc généralement judicieux de mener des recherches approfondies avant de choisir l'option sans serveur pour votre prochain projet cloud AWS.
Pour aller plus loin, explorez les meilleures bases de données sans serveur pour les applications modernes.