11 meilleures plateformes de données en continu pour l'analyse et le traitement en temps réel
L'univers numérique actuel est intrinsèquement lié aux données. La capacité à acquérir des renseignements précis en temps réel à partir d'informations concrètes offre un avantage compétitif indéniable. Le streaming de données permet une saisie et un traitement continus de données provenant de sources diverses, soulignant ainsi l'importance cruciale de plateformes de streaming performantes.
Les plateformes de streaming de données se caractérisent par leur évolutivité, leur nature distribuée et leur haute efficacité, assurant un traitement fiable des flux d'informations. Elles facilitent l'agrégation et l'analyse des données, et proposent souvent un tableau de bord unifié pour une visualisation optimale.
Un large éventail d'options s'offre à vous, des systèmes entièrement gérés tels que Confluent Cloud et Amazon Kinesis, aux solutions open source comme Arroyo et Fluvio.
Quelles sont les applications concrètes du streaming de données ?
Les applications des plateformes de streaming de données sont vastes et variées. Voici quelques exemples notables :
- La détection de la fraude est assurée par une analyse continue des transactions, des comportements utilisateurs et des schémas atypiques.
- Les données boursières sont traitées par des systèmes à haute fréquence effectuant des transactions ultra-rapides basées sur des analyses de marché.
- Des informations personnalisées, fondées sur des données de marché en temps réel, permettent aux plateformes de commerce électronique de cibler leurs produits avec une grande précision.
- Des millions de capteurs, intégrés à divers systèmes, fournissent des informations concrètes et contribuent à la génération de prédictions comme les prévisions météorologiques.
Voici une sélection des meilleures plateformes de données pour répondre à tous vos besoins d'analyse et de traitement en temps réel.
Confluent Cloud
Confluent Cloud, solution entièrement basée sur le cloud pour Apache Kafka, offre une excellente résilience, une évolutivité optimale et des performances de pointe.. Tirant parti du moteur Kora, il fournit des performances jusqu'à dix fois supérieures à celles d'un cluster Kafka autogéré. Les fonctionnalités incluent :
- Des clusters sans serveur offrent une évolutivité et une élasticité parfaites. Vos besoins en streaming de données sont satisfaits instantanément grâce à un ajustement automatique à la demande.
- Vos exigences en matière de stockage sont assurées grâce à une conservation et une intégrité illimitées des données. Vous pouvez vous fier à Confluent Cloud comme source unique de vérité, sans souci de durabilité.
- Confluent Cloud garantit un taux de disponibilité de 99,99 %, l'un des plus élevés du secteur. Combiné à la réplication multi-zones, vos données sont protégées contre toute perte ou corruption.
Le concepteur de flux intègre une interface utilisateur intuitive de type glisser-déposer pour créer vos pipelines de traitement de manière visuelle. De plus, des connecteurs Kafka pré-intégrés simplifient la connexion à n'importe quelle application ou source de données.
Confluent Cloud propose Stream Governance, la seule suite de gouvernance des données entièrement gérée. Sécurité et conformité de niveau entreprise protègent vos données et contrôlent l'accès.
Divers plans tarifaires sont disponibles. De nombreuses ressources sont également proposées pour une prise en main rapide.
Aiven

Aiven prend en charge tous vos besoins en matière de streaming de données via un service cloud Apache Kafka entièrement géré. Il est compatible avec tous les principaux fournisseurs de cloud, comme AWS, Google Cloud, Microsoft Azure, Digital Ocean et UpCloud.
Configurez votre propre service Kafka en moins de 10 minutes en utilisant la console web ou via l'API et la CLI. Vous pouvez également choisir de l'exécuter dans des conteneurs.
Éliminez les complexités de la gestion Kafka grâce à un service cloud entièrement géré. Configurez rapidement votre pipeline de données grâce à un tableau de bord de suivi. Voici les avantages clés :
- Recevez des mises à jour automatiques de votre cluster et gérez les versions et les opérations de maintenance en quelques clics.
- Aiven vous assure une disponibilité de 99,99 % et une quasi-absence d'interruptions de service.
- Augmentez votre stockage à la demande, ajoutez davantage de nœuds Kafka, ou étendez-vous à de nouvelles régions.
Les tarifs mensuels d'Aiven commencent à 200 $, avec des variations basées sur votre localisation et le fournisseur cloud choisi.
Arroyo
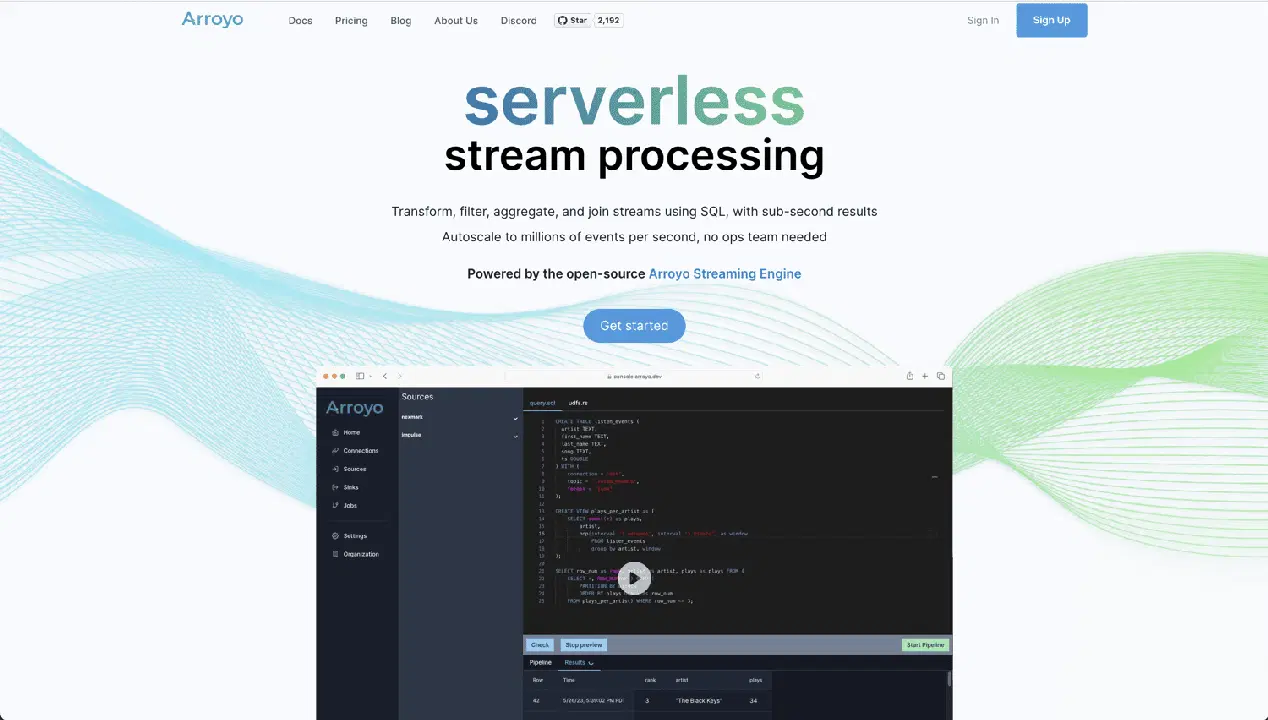
Si vous êtes à la recherche d'une solution cloud native et open source pour vos traitements et analyses en temps réel, Arroyo est une option particulièrement intéressante. Elle s'appuie sur Arroyo Streaming Engine, une solution de traitement de flux distribuée qui excelle dans l'analyse de données en temps réel avec des résultats en moins d'une seconde.
Arroyo est conçu pour rendre le traitement en temps réel aussi aisé que le traitement par lots. Sa grande convivialité vous évite d'être un expert pour créer votre pipeline. Voici ce qu'offre Arroyo :
- Une prise en charge native de divers connecteurs, comme Kafka, Pulsar, Redpanda, WebSockets et Server Sent Events.
- Après l'ingestion et le traitement des données, les résultats peuvent être transférés vers des systèmes tels que Kafka, Amazon S3 et Postgres.
- Un compilateur performant optimise vos requêtes SQL pour une efficacité maximale.
- Le flux de données de votre plateforme peut s'adapter horizontalement afin de prendre en charge des millions d'événements par seconde.
Vous avez la possibilité d'exécuter votre propre instance auto-hébergée d'Arroyo (gratuite), ou d'utiliser Arroyo Cloud, avec des prix commençant à 200 $ par mois. Notez qu'Arroyo est actuellement en version Alpha et peut donc présenter certaines limitations.
Amazon Kinesis

Amazon Kinesis Data Streams permet de collecter et de traiter de grands flux de données en continu. Il se caractérise par son évolutivité massive, sa durabilité et son faible coût. Voici un aperçu de ses principales fonctionnalités :
- Amazon Kinesis fonctionne dans le cloud AWS en mode sans serveur à la demande. En quelques clics depuis AWS Management Console, vous pouvez activer vos flux Kinesis Data.
- Kinesis peut être exécuté sur jusqu'à 3 zones de disponibilité (AZ). Il offre également une conservation des données pendant 365 jours.
- Les flux de données Kinesis permettent de connecter jusqu'à 20 consommateurs. De plus, chaque consommateur possède son propre débit de lecture dédié et peut publier les données dans les 70 millisecondes suivant l'ingestion.
- Répondez à vos exigences de sécurité en chiffrant les données via un chiffrement côté serveur.
- Faisant partie d'AWS, Kinesis s'intègre de manière transparente avec d'autres services AWS tels que Cloudwatch, DynamoDB et AWS Lambda.
Avec Amazon Kinesis, vous payez uniquement ce que vous utilisez. Pour un démarrage avec 1000 enregistrements/seconde de 3 Ko chacun, le coût journalier en mode à la demande sera d'environ 30,61 $. Le calculateur AWS vous permet d'estimer le coût en fonction de votre utilisation.
Databricks

Si vous recherchez une plateforme de données unique pour le traitement par lots et par flux, la plateforme Databricks Lakehouse est un excellent choix. Elle propose des analyses en temps réel, l'apprentissage automatique et la création d'applications sur une seule et même plateforme.
La plateforme Databricks Lakehouse utilise Delta Live Tables (DLT), avec les avantages suivants :
- DLT simplifie la définition de votre pipeline de données de bout en bout.
- Des tests automatiques garantissent la qualité des données. Vous pouvez également suivre les tendances de la qualité dans le temps.
- L'ajustement automatique de DLT gère les charges de travail imprévisibles.
Vous bénéficiez d'une plateforme performante pour exécuter vos tâches Apache Spark, avec Spark Structured Streaming comme technologie de base. S'y ajoute Delta Lake, l'unique plateforme de stockage open source compatible avec les données en continu et par lots.
Vous pouvez profiter d'un essai gratuit de 14 jours avec la plateforme Databricks Lakehouse, après quoi vous serez automatiquement abonné au forfait que vous aurez choisi.
Qlik Data Streaming (CDC)

CDC (Change Data Capture) est une technique permettant de notifier les modifications de données à d'autres systèmes. Solution simple et universelle, Qlik Data Streaming (CDC) permet de déplacer facilement vos données de la source à la destination en temps réel. L'ensemble de ces opérations se gère via une interface graphique intuitive.
Qlik Data Streaming (CDC) offre une configuration simple et automatisée. Vous pouvez ainsi configurer, contrôler et surveiller votre pipeline de données en temps réel en toute facilité.
Cette solution prend en charge une grande diversité de sources, de cibles et de plateformes. Vous pouvez ingérer une grande variété de données et synchroniser des données sur site, dans le cloud et de manière hybride.
Qlik Enterprise Manager centralise la commande, et vous permet de suivre le flux de données via des alertes.
Il existe une option de déploiement flexible pour l'exécution de votre pipeline CDC. En fonction de vos besoins, vous pouvez choisir entre les options suivantes :
Vous pouvez commencer par un essai gratuit sans téléchargement ni installation.
Fluvio

Si vous recherchez une solution de streaming cloud native open source avec une faible latence et des performances élevées, Fluvio pourrait répondre à vos attentes. Vous pouvez effectuer des calculs en ligne avec SmartModules, ce qui enrichit les fonctionnalités de la plateforme.
Fluvio offre un traitement de flux distribué avec des mécanismes garantissant l'absence de perte de données et de temps d'arrêt. Il prend en charge les API pour les langages de programmation les plus courants (Rust, Node.js, Python, Java et Go). Voici les principaux atouts de cette plateforme :
- La combinaison de calcul et de streaming dans un seul cluster réduit les latences.
- Fluvio charge dynamiquement des modules personnalisés qui étendent les possibilités de calcul.
- Il offre une grande évolutivité, des petits appareils IoT aux systèmes multi-cœurs.
- Des mécanismes de réparation automatique assurent la gestion, la réconciliation et la réplication.
- Conçu pour la communauté des développeurs, Fluvio dispose d'une puissante interface CLI pour une efficacité accrue.
Vous pouvez installer Fluvio sur n'importe quelle plateforme, que ce soit votre ordinateur portable, votre centre de données d'entreprise, ou le cloud public de votre choix.
Étant open source, l'utilisation de Fluvio est gratuite.
Cloudera Stream Processing (CSP)

S'appuyant sur Apache Flink et Apache Kafka, Cloudera Stream Processing (CSP) vous offre des fonctionnalités d'analyse avancées pour mieux comprendre vos flux de données. Il est compatible avec les technologies standard comme SQL et REST. Cette solution complète de gestion de flux est conçue pour les entreprises.
Cloudera Stream Processing analyse de gros volumes de données en temps réel avec des latences inférieures à la seconde. Il prend en charge le multicloud et les environnements hybrides, et propose des outils pour construire des analyses sophistiquées basées sur les données. Voici les principales fonctionnalités :
- Avec une capacité de traitement de plusieurs millions de messages par seconde, son streaming est très évolutif.
- Streams Messaging Manager offre une vue de bout en bout de la manière dont vos données circulent dans votre pipeline.
- Streams Replication Manager garantit la réplication, la disponibilité et la reprise après sinistre.
- Schema Registry vous aide à gérer les incompatibilités de schémas, en centralisant le tout dans un référentiel partagé.
- Cloudera SDX offre un contrôle et une gouvernance unifiés de tous vos composants, avec une sécurité centralisée et appliquée automatiquement.
Avec Cloudera Stream Processing, vous pouvez lancer votre pipeline de traitement de flux en moins de 10 minutes sur la plateforme cloud de votre choix (AWS, Azure ou Google Cloud Platform).
Striim Cloud
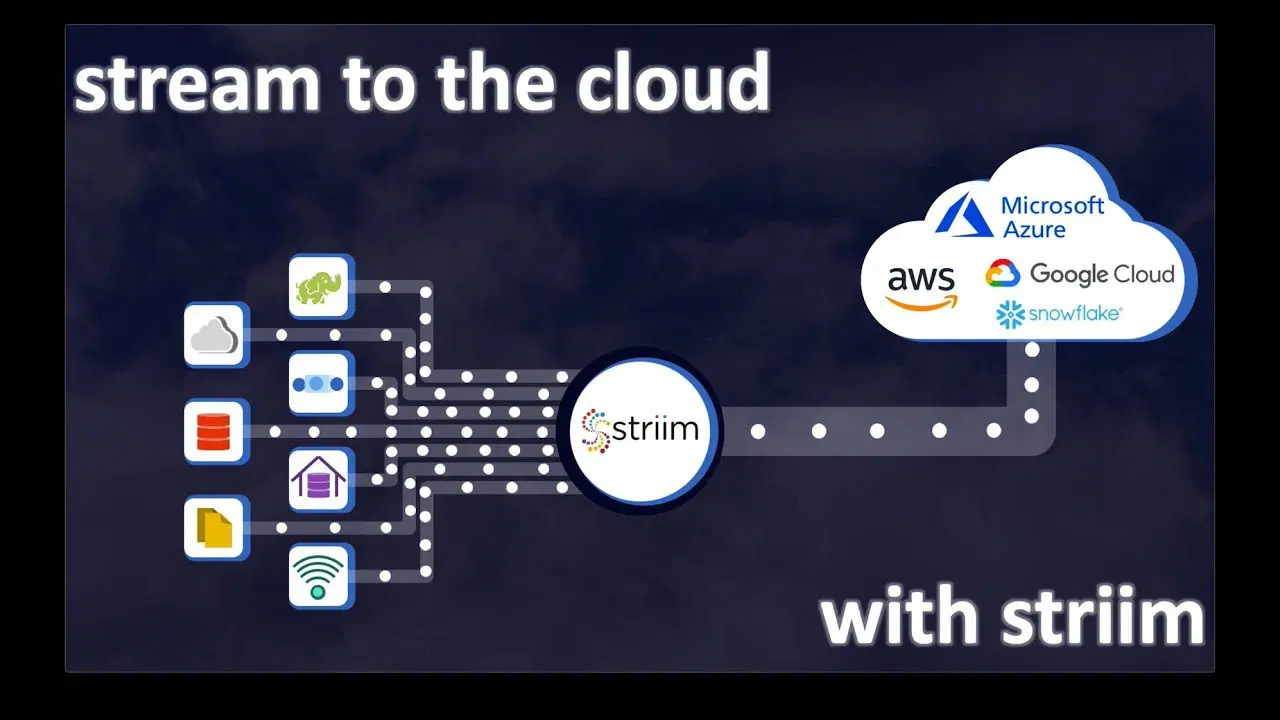
Si votre plateforme de données et vos analyses en temps réel nécessitent une grande variété de producteurs et de consommateurs de données, Striim Cloud, avec plus de 100 connecteurs intégrés, est une option à considérer. Elle permet d'intégrer vos magasins de données existants et de diffuser des données en temps réel grâce à une plateforme SaaS entièrement gérée et conçue pour le cloud.
Striim Cloud intègre une interface simple de type glisser-déposer qui aide à la création de votre pipeline, mais également fournit des renseignements précieux sur vos données. Il prend en charge les outils d'analyse les plus répandus, notamment Google BigQuery, Snowflake, Azure Synapse et Databricks. Voici quelques avantages :
- Striim gère les modifications de structure de données via ses capacités d'évolution de schémas. Vous pouvez choisir une résolution automatique ou une intervention manuelle.
- Construit sur une plateforme SQL de streaming distribué, Striim permet d'exécuter des requêtes continues.
- Striim garantit une grande évolutivité et un débit élevé. Vous pouvez adapter votre pipeline sans planification ni coût supplémentaires.
- La méthode 'ReadOnlyWriteMany' permet d'ajouter et de supprimer de nouvelles cibles sans impacter vos magasins de données.
Vous ne payez que ce que vous utilisez. L'environnement de développement Striim est gratuit et vous permet de tester la plateforme avec 10 millions d'événements/mois. Pour une solution cloud à l'échelle de l'entreprise, les tarifs commencent à 2 500 $/mois.
Plateforme de données de streaming VK

Avec des produits de données et des informations de pointe, Vertical Knowledge (VK) aide les particuliers et les entreprises à prendre des décisions éclairées à grande échelle. La plateforme de données de streaming VK vous permet de traiter de grandes quantités de données via un environnement de streaming de données web.
Bénéficiez d'informations exploitables grâce à la découverte automatisée de données. Voici les principaux avantages de la plateforme :
- Une cybersécurité renforcée est assurée par l'infrastructure stable de VK. Vous téléchargez des données via un environnement virtuel.
- Les flux de données automatisés facilitent l'exploitation de nombreuses sources de données.
- Une découverte rapide réduit les processus manuels, souvent chronophages.
- Générez des collections de données approfondies en exécutant des pipelines simultanés à partir de plusieurs sources. Vous pouvez ainsi générer des résultats pour des mots-clés sélectionnés.
- Vous pouvez exporter vos collections de données au format JSON ou CSV brut, ou utiliser des API pour les intégrer avec des systèmes tiers.
Plateforme HStream
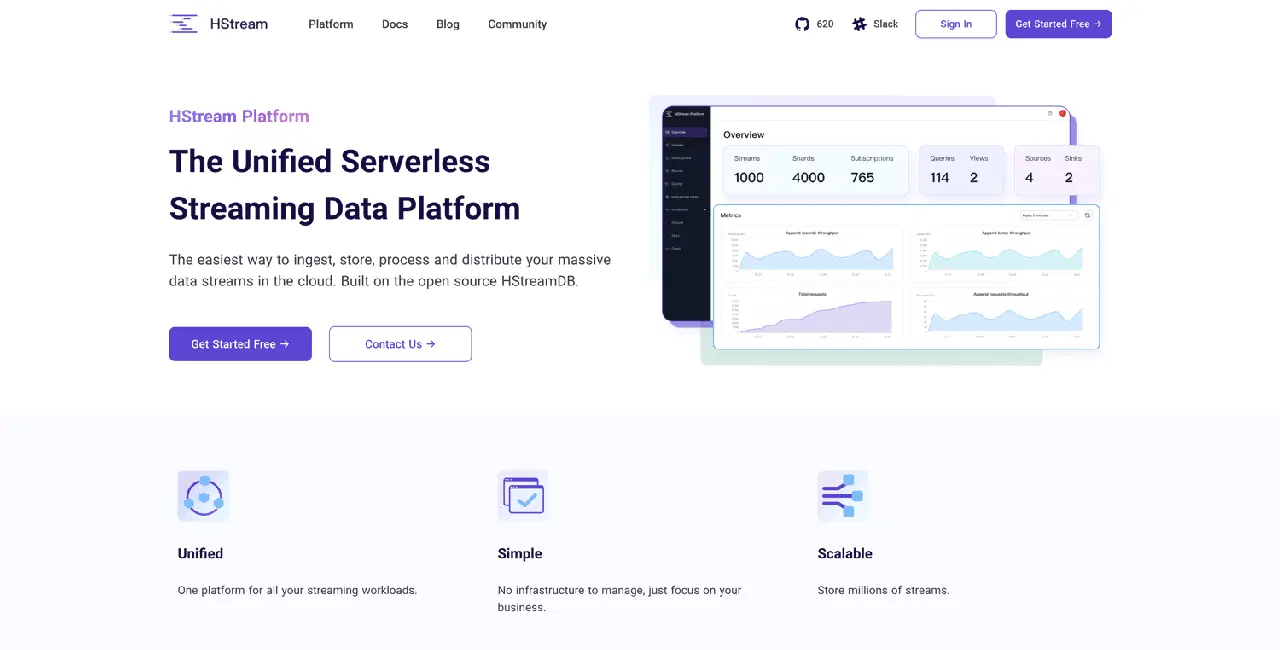
Basée sur HStreamDB open source, la plateforme HStream propose une plateforme de données de streaming sans serveur. Elle permet d'ingérer et de stocker de manière fiable des millions de flux de données. HStreamDB est aussi rapide que Kafka, et vous permet de rejouer des données historiques.
Vous pouvez utiliser SQL pour filtrer, transformer, agréger et joindre diverses vues de données, et obtenir ainsi une vision en temps réel. La plateforme HStream est facile à prendre en main. Voici ses principales fonctionnalités :
- Étant sans serveur, elle est opérationnelle immédiatement.
- Kafka n'est pas nécessaire pour le streaming.
- Le traitement des flux est effectué sur place avec SQL.
- Vous pouvez utiliser différentes bases de données, entrepôts de données ou lacs de données, sans outils ETL supplémentaires.
- Gérez vos charges de travail sur une plateforme de streaming unique.
- L'architecture cloud native permet d'adapter vos besoins informatiques et de stockage indépendamment.
La plateforme HStream est actuellement en version bêta publique. Elle est gratuite : il suffit de s'inscrire pour y accéder.
Conclusion
Le choix d'une plateforme de streaming de données dépend de vos besoins spécifiques en termes d'échelle, de connecteurs, de disponibilité et de fiabilité.
Certaines plateformes sont des services entièrement gérés, tandis que d'autres sont open source et offrent une personnalisation plus poussée. Évaluez attentivement vos besoins et votre budget pour faire le choix le plus approprié.
Vous vous demandez toujours comment tirer le meilleur parti de vos données ? Envisagez d'utiliser des outils de prévision et de prédiction de données basés sur l'IA pour les entreprises.