10 meilleures solutions de base de données de graphes à essayer
Les bases de données graphiques excellent dans le stockage et le traitement de données fortement interconnectées, permettant des requêtes rapides et efficaces. Mais comment choisir la base de données graphique idéale pour votre projet ? Cet article vous éclairera sur les critères de sélection.
L'expression « les données sont le nouvel or noir » illustre l'importance cruciale de la gestion et de l'exploitation des données pour toute organisation. Avec 2,5 trillions d'octets de données générés quotidiennement, il est impératif de disposer de systèmes de stockage robustes et fiables. Les bases de données relationnelles ont longtemps dominé ce domaine, mais l'évolution rapide du volume et de la variété des données a conduit à l'émergence d'alternatives.
Par conséquent, des bases de données SQL, NoSQL, Hadoop, et des bases de données graphiques ont vu le jour. Chacune de ces technologies répond à des cas d'utilisation spécifiques et traite différents formats de données. Les bases de données graphiques se sont développées pour faciliter les opérations sur les données et optimiser leur stockage.
Présentation des bases de données graphiques
Un graphique est une structure de données constituée de nœuds (les entités) et d'arêtes (les relations). Une base de données, elle, organise et stocke les informations ainsi que les liens qui les unissent. Une base de données graphique, donc, enregistre les données en tant que nœuds et leurs relations sous forme d'arêtes. Cette approche permet de gérer efficacement les requêtes en temps réel et de traiter les relations de type « plusieurs à plusieurs ».
Parmi les modèles de données graphiques populaires, on distingue les graphes de propriétés et les graphes RDF. Les graphes de propriétés sont privilégiés pour l'analyse et les requêtes, tandis que les graphes RDF sont utilisés pour l'intégration des données. La distinction fondamentale réside dans la représentation : les graphes RDF utilisent des triplets (sujet, prédicat, objet) pour structurer l'information.
Les bases de données graphiques enregistrent les données dans des nœuds et les relations entre elles via des arêtes qui relient ces nœuds. Ces arêtes peuvent être orientées (unidirectionnelles) ou non orientées (bidirectionnelles).
Le traitement des requêtes est basé sur l'exploration du graphique. Des algorithmes de parcours de graphe sont utilisés pour déterminer les chemins entre les nœuds, les distances, les schémas, les boucles et les possibilités de formation de groupes, permettant ainsi des réponses rapides et précises.
Domaines d'application des bases de données graphiques
Les bases de données graphiques sont particulièrement efficaces dans la détection de la fraude. Les nœuds peuvent représenter des personnes, des adresses, des dates de naissance, tandis que les arêtes identifient les connexions suspectes basées sur des adresses IP frauduleuses, des numéros d'appareils, etc. Une interaction entre un nœud frauduleux et un nœud non frauduleux est ainsi mise en évidence.
Les réseaux sociaux utilisent largement les bases de données graphiques pour proposer des suggestions d'amis et de contenu pertinents. Ce système est basé sur des algorithmes de parcours de graphes.
La cartographie de réseau, la gestion de l'infrastructure et des éléments de configuration font également partie des applications où les bases de données graphiques se révèlent précieuses.
Comparaison : bases de données graphiques vs bases de données relationnelles
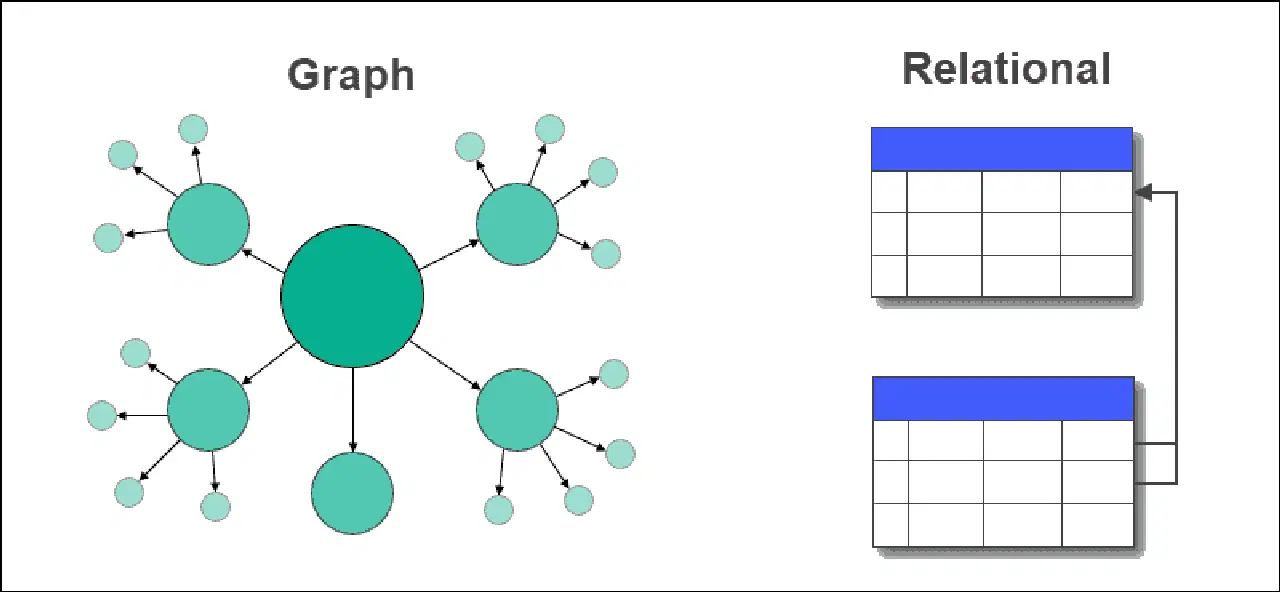
Dans une base de données graphique, les traditionnelles tables avec leurs lignes et colonnes sont remplacées par des nœuds et des arêtes. Les relations entre les données sont explicitement stockées sur les arêtes.
Dans une base de données relationnelle, les relations entre les tables sont gérées via des clés étrangères. L'interrogation des données dans une base de données graphique est simplifiée par l'absence de jointures complexes, contrairement aux bases de données relationnelles.
Les bases de données relationnelles sont mieux adaptées aux systèmes transactionnels, tandis que les bases de données graphiques sont parfaites pour les applications fortement axées sur les relations et les données interconnectées.
Les bases de données graphiques acceptent les données structurées, semi-structurées et non structurées, alors que les bases de données relationnelles nécessitent un schéma fixe.
Les bases de données graphiques s'adaptent aux besoins dynamiques, tandis que les bases de données relationnelles sont souvent utilisées pour des problèmes connus et statiques.
Comparaison bases de données graphiques vs relationnelles
Examinons maintenant quelques-unes des meilleures solutions de bases de données graphiques disponibles.
Cayley
Cayley, une base de données graphique open source sous licence Apache 2.0, a été développée en Go. Elle est conçue pour gérer des données liées et est notamment utilisée pour la création de la base de connaissances de Google. Elle prend en charge de nombreux langages de requêtes tels que MQL et Javascript via un objet graphique basé sur Gremlin.

Cayley est réputée pour sa facilité d'utilisation, sa rapidité et sa conception modulaire. Elle s'intègre avec divers systèmes de stockage backend tels que LevelDB, MongoDB et Bolt. Elle propose des API tierces écrites dans de nombreux langages comme Java, .NET, Rust, Haskell, Ruby, PHP, Javascript et Clojure. Elle est compatible avec Docker et Kubernetes. Elle est largement utilisée dans les technologies de l'information, les logiciels et les services financiers.
Amazon Neptune
Amazon Neptune se distingue par ses excellentes performances avec des jeux de données hautement connectés. Elle est fiable, sécurisée, totalement gérée et compatible avec les API de graphes ouvertes. Elle peut stocker des milliards de relations et exécuter des requêtes avec une latence minimale de quelques millisecondes.
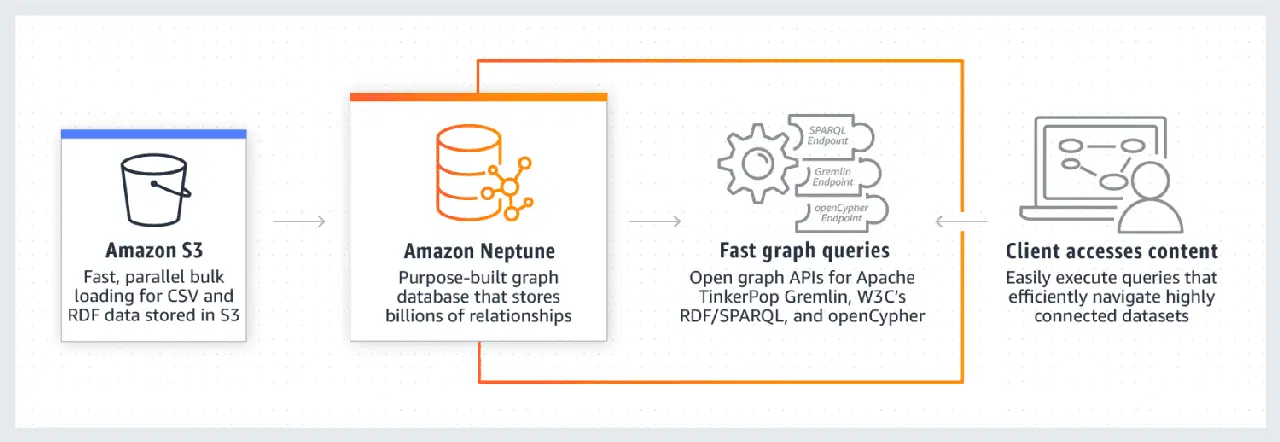
Le modèle de données de Neptune est composé de 4 positions : sujet (S), prédicat (P), objet (O) et graphe (G). Chacune de ces positions stocke respectivement la position du nœud source, du nœud cible, la relation qui les unit et leurs propriétés.
Elle utilise un cache pour accélérer les requêtes de lecture. Les données sont stockées dans des clusters de bases de données constitués d'une instance de base de données principale et de répliques de lecture. La sécurité de Neptune est renforcée par l'authentification IAM, la certification SSL et la surveillance des journaux. La migration de données depuis d'autres sources est également simplifiée. Enfin, Neptune assure la résilience grâce à la création de répliques et de sauvegardes régulières. Des entreprises telles que Herren, Onedot, Juncture et Hi Platform l'ont déjà adoptée.
Neo4j
Neo4j est une base de données graphique évolutive, sécurisée, à la demande et fiable. Développée en Java, elle utilise Cypher comme langage de requête. Elle fonctionne avec le protocole Bolt et toutes les transactions sont réalisées via un point de terminaison HTTP. Elle est particulièrement performante pour répondre aux requêtes, surpassant souvent les bases de données relationnelles grâce à l'absence de jointures complexes et ses optimisations qui conviennent parfaitement aux grands jeux de données hautement connectés. Elle combine les avantages du stockage de données en graphe avec les propriétés ACID d'une base de données relationnelle.

Neo4j offre une compatibilité avec de nombreux langages tels que Java, .NET, Node.js, Ruby, Python, etc., via des pilotes. Elle est également utilisée dans le domaine de la science des données graphiques, de l'analyse et de l'apprentissage automatique. Neo4j Aura DB est une base de données graphique cloud gérée et tolérante aux pannes. Des entreprises comme Microsoft, Cisco, Adobe, eBay, IBM et Samsung, font confiance à Neo4j.
ArangoDB
ArangoDB est une base de données multi-modèle open-source qui permet aux utilisateurs d'interroger les données avec le langage de requête de leur choix. Les nœuds et les arêtes d'ArangoDB sont des documents JSON, chaque document ayant un identifiant unique. Les relations entre les nœuds sont représentées par des arêtes qui stockent les identifiants uniques des nœuds liés. La performance d'ArangoDB est optimisée par l'utilisation d'un index de hachage.

Les parcours, les jointures et les recherches sont améliorés. ArangoDB permet de concevoir, de mettre à l'échelle et de s'adapter à des architectures diverses. Elle joue un rôle clé dans les tâches de science des données complexes telles que l'extraction de caractéristiques et la recherche avancée.
ArangoDB peut être déployée dans des environnements cloud et est compatible avec Mac OS, Linux et Windows. L'authentification LDAP, le masquage des données et les algorithmes de chiffrement garantissent la sécurité de la base de données. Elle est utilisée pour la gestion des risques, l'IAM, la détection de la fraude, l'infrastructure réseau et les moteurs de recommandation. Accenture, Cisco, Dish et VMware figurent parmi les entreprises qui utilisent ArangoDB.
DataStax
DataStax est une base de données cloud NoSQL, proposée en tant que service et basée sur Apache Cassandra. Elle est hautement évolutive et utilise une architecture cloud native. Elle est réputée pour sa fiabilité et sa sécurité. Chaque document stocké dans DataStax possède un index qui facilite la recherche et la récupération rapide des données. Les données indexées sont partitionnées. DataStax permet de créer des applications à partir de diverses sources de données grâce aux outils Datastax Enterprise, Kafka et Docker.
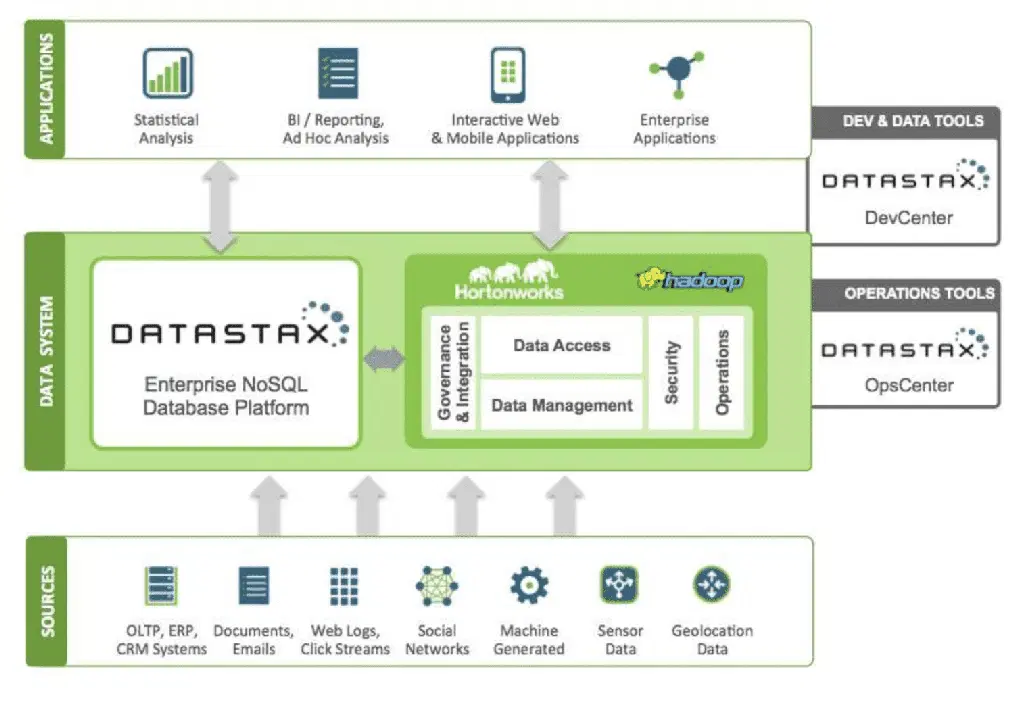
Les données collectées sont envoyées à un écosystème Hadoop et DataStax. Hadoop gère la sécurité, les opérations, l'accès aux données et leur gestion en interagissant avec DataStax. Les données sont ensuite affinées à l'aide des outils de développement et d'exploitation de Datastax.
Les informations analysées sont ensuite utilisées pour des analyses statistiques, des applications d'entreprise, des rapports, etc. La tarification basée sur l'utilisation rend cette solution cloud économique. Des entreprises telles que Verizon, CapitalOne, TMobile et Overstock utilisent DataStax.
OrientDB
OrientDB est une base de données graphique qui facilite la gestion des données et aide à créer des représentations visuelles. Elle a été développée en Java. OrientDB stocke les données sous forme de paires clé-valeur, de documents, de modèles d'objets, etc. Elle est structurée en trois composants clés : l'éditeur de graphes, la requête de studio et la console de ligne de commande.
L'éditeur de graphique est utilisé pour visualiser et interagir avec les données. L'interface de requête de Studio sert à exécuter les requêtes et à afficher les résultats sous forme d'images et de tableaux. La console de ligne de commande permet d'interroger les données. OrientDB a une architecture distribuée avec plusieurs serveurs permettant les opérations de lecture et d'écriture. Les serveurs de réplication sont utilisés pour les opérations de lecture et de requête. OrientDB prend en charge l'indexation et est également conforme aux normes ACID. Des entreprises comme Comcast Corporation et Blackfriars Group l'utilisent.
Dgraph
Dgraph est une base de données graphique cloud qui supporte GraphQL. Elle est développée en Go. Elle minimise les appels réseau et réduit la latence en optimisant le traitement simultané des requêtes. L'intégration de Dgraph avec GraphQL facilite le développement d'applications backend GraphQL.
Une mutation GraphQL est transmise via une fonction Lambda, qui interagit avec la base de données et un pipeline de données, ce qui simplifie le traitement des requêtes. La base de données est évolutive horizontalement, ce qui permet d'adapter les ressources à la demande en termes de requêtes et de volume de données. Elle offre des fonctionnalités comme l'autorisation basée sur JWT, un visualiseur de données, l'authentification cloud, des sauvegardes de données, etc. Intuit, Intel et Factset font partie des entreprises qui utilisent Dgraph.
Tigergraph
Tigergraph est une base de données de graphes de propriétés développée en C++. Elle est hautement évolutive et permet d'effectuer des analyses avancées sur des données fortement interconnectées. Elle utilise une structure graphique native pour le stockage des données et un moteur de traitement graphique pour leur manipulation. La base de données est stockée sur disque et en mémoire, et exploite également un cache CPU pour des accès rapides. Le traitement parallèle des données est réalisé à l'aide de la fonction Map Reduce.
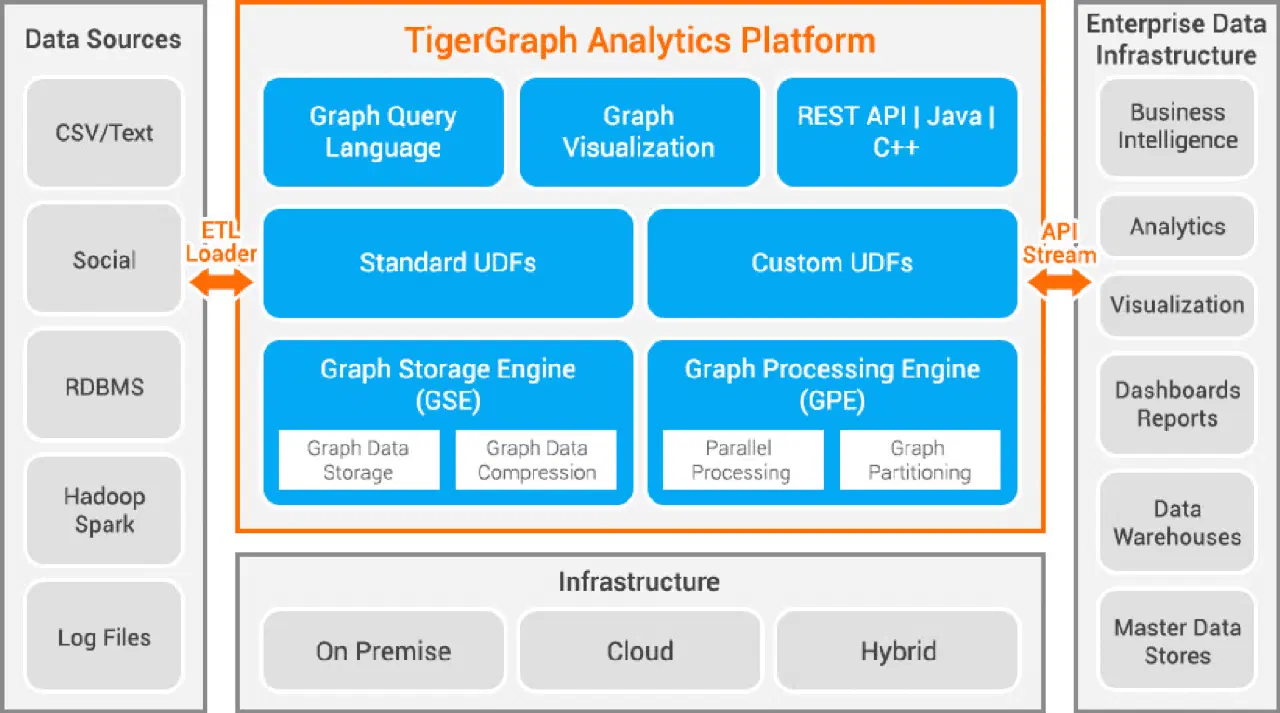
Tigergraph est particulièrement rapide et évolutive. Elle permet des calculs parallèles et des mises à jour en temps réel. Elle utilise des techniques de compression de données qui peuvent réduire le volume des données par un facteur de 10. Les données sont automatiquement partitionnées sur les serveurs, ce qui évite à l'utilisateur de le faire manuellement. Elle est utilisée dans la détection de fraude, la gestion de la chaîne d'approvisionnement et l'amélioration des soins de santé. JPMorgan Chase, Intuit et United Health Group utilisent Tigergraph.
AllegroGraph
AllegroGraph utilise la technologie des graphes de connaissances entité-événement pour analyser des données interconnectées, complexes et denses et prendre des décisions. Les données sont stockées au format JSON et JSON-LD dans les nœuds du graphe. Elle fonctionne via une architecture de protocole REST. AllegroGraph traite également de très grands ensembles de données en divisant les données selon des critères spécifiques et en les distribuant dans plusieurs référentiels de base de connaissances.
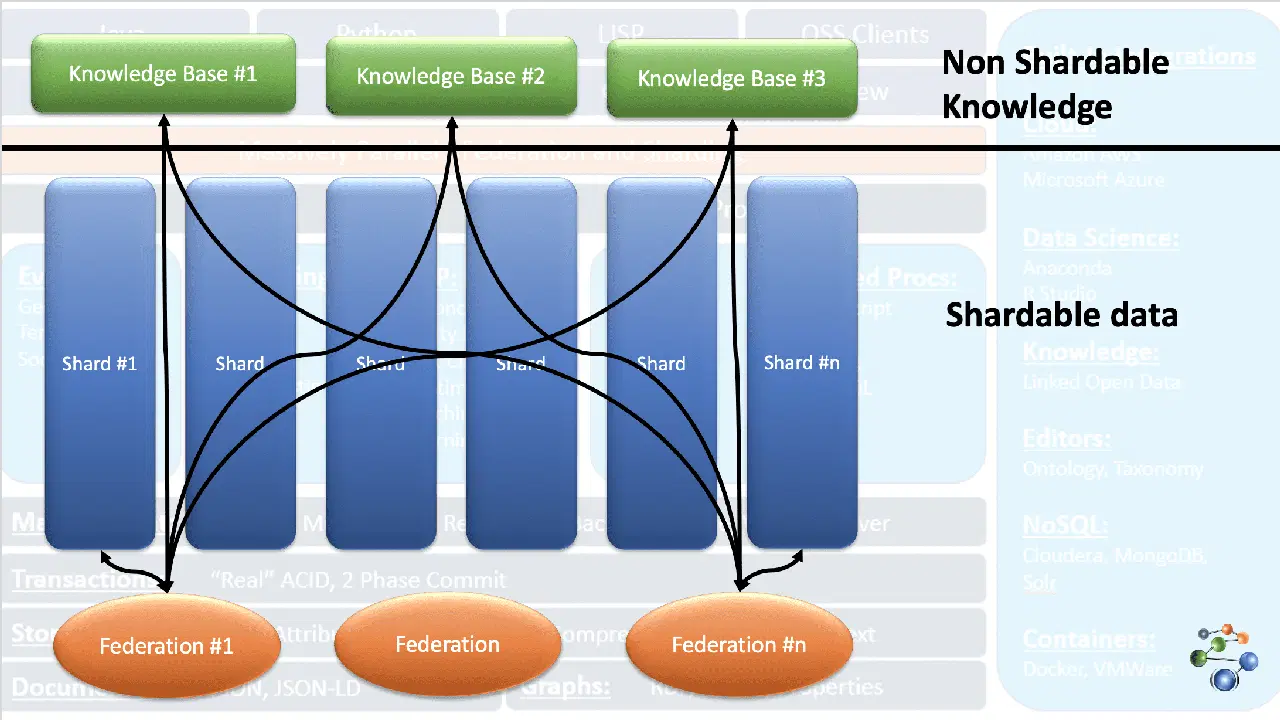
Ceci est rendu possible par la fonctionnalité FedShard d'AllegroGraph. L'exécution des requêtes se fait en combinant les fédérations et les référentiels de la base de connaissances. AllegroGraph prend en charge les schémas XML et utilise des index triples. Elle stocke des données géospatiales (latitudes et longitudes) et temporelles (date, horodatage, etc.). Elle est compatible avec Windows, Mac et Linux. AllegroGraph est utilisée dans la détection de fraude, les soins de santé, l'identification d'entités et la prédiction des risques.
Stardog
Stardog est une base de données graphique qui effectue la virtualisation de données graphiques et relie les informations des entrepôts de données et des lacs de données sans avoir à les copier physiquement. Stardog est basée sur des standards ouverts RDF. Elle supporte les données structurées, semi-structurées et non structurées. Ce type de matérialisation apportée par Stardog offre de la flexibilité. C'est la seule base de données graphique qui combine des graphes de connaissances et la virtualisation.

Stardog utilise un moteur d'inférence basé sur l'IA pour traiter et fournir des résultats de requêtes efficaces. Elle est compatible ACID et prend en charge les lectures et écritures simultanées. Elle est performante pour gérer les requêtes complexes grâce à son architecture de pointe. Stardog est utilisée dans la gestion des actifs informatiques, la gestion et l'analyse des données et offre une haute disponibilité. Cisco, eBay, la NASA et Finra font partie des entreprises qui l'ont adopté.
Pour conclure
Les bases de données graphiques facilitent l'interrogation des relations « plusieurs à plusieurs » et permettent un stockage efficace des données. Elles sont évolutives, sécurisées et peuvent être intégrées à de nombreux outils, API et langages tiers. Au cours des dernières années, leur intégration au cloud a contribué à améliorer leurs performances.
Elles simplifient les requêtes complexes grâce à des jointures simplifiées, ce qui facilite la tâche des développeurs. Les bases de données graphiques sont particulièrement adaptées aux tâches gourmandes en données comme l'IoT et le Big Data. Leur développement devrait s'accélérer, avec de nouvelles applications à venir.